嘿 r/LocalLLaMA!Google 刚刚发布了 Gemma-2 2b,这是在一个更大的 LLM(27b?甚至更大的?)上经过2万亿个蒸馏输出的训练结果。我上传了4位 bitsandbytes 量化和 GGUF 变体!我也已经为 9b 和 27b 上传了4位版本。
我还使微调速度提高了2倍,并减少了63%的VRAM使用! 我有一个免费的 Colab 笔记本,通过 Unsloth 在这里微调 Gemma-2 2b:https://colab.research.google.com/drive/1weTpKOjBZxZJ5PQ-Ql8i6ptAY2x-FWVA?usp=sharing。9b 和 27b 的 Kaggle 和其他 Colab 笔记本在 https://github.com/unslothai/unsloth
Gemma-2 2b Instruct GGUF 量化在 https://huggingface.co/unsloth/gemma-2-it-GGUF
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q2_k.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q3_k_m.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q4_k_m.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q5_k_m.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q6_k.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.q8_0.gguf
- https://huggingface.co/unsloth/gemma-2-it-GGUF/blob/main/gemma-2-2b-it.F16.gguf
Bitsandbytes 4位量化(微调下载速度提高4倍)
- https://huggingface.co/unsloth/gemma-2-2b-it-bnb-4bit
- https://huggingface.co/unsloth/gemma-2-2b-bnb-4bit
对于其他使 Gemma-2 微调速度提高2倍并减少50-60% VRAM 使用的笔记本,请查看我们的9b免费笔记本:
Colab: https://colab.research.google.com/drive/1vIrqH5uYDQwsJ4-OO3DErvuv4pBgVwk4?usp=sharing
Kaggle: https://www.kaggle.com/code/danielhanchen/kaggle-gemma-7b-unsloth-notebook/
Gemma-2 2b 在 Chat LMSYS 排行榜上表现相当不错:
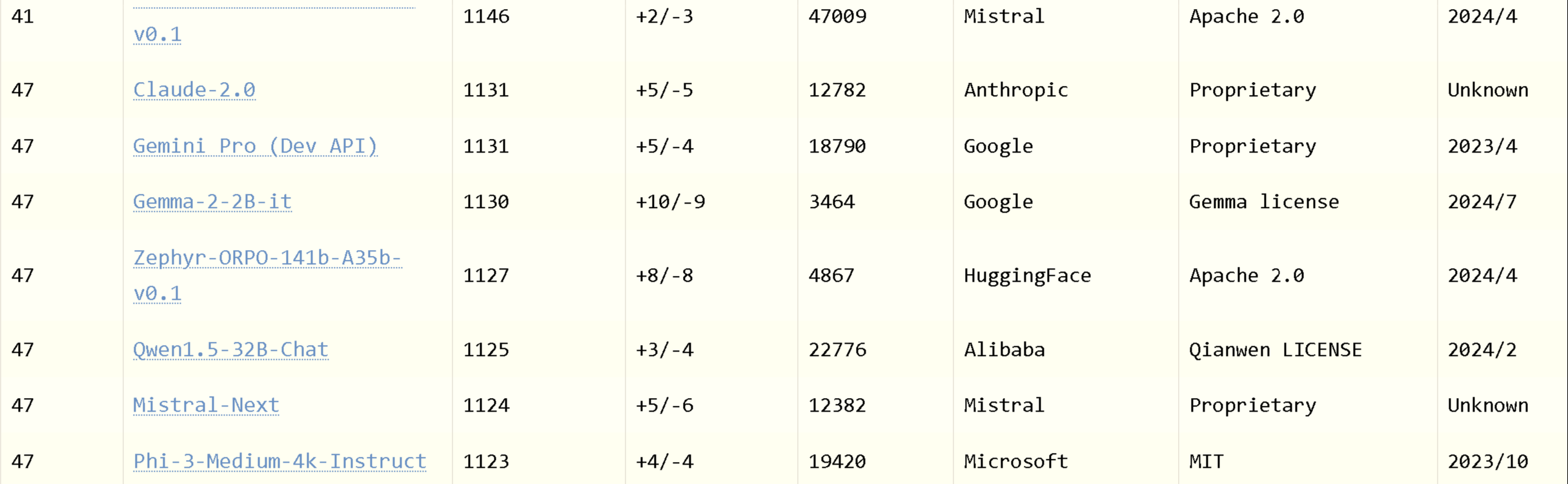
另外,请更新 Unsloth 以使用支持 Gemma-2 的 Flash Attention v2,包括软上限支持!现在注意力使用线性内存而不是二次内存 - 允许长上下文微调!
pip uninstall unsloth -y
pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
我还为 Gemma-2 instruct 制作了一个在线推理聊天界面:https://colab.research.google.com/drive/1i-8ESvtLRGNkkUQQr_-z_rcSAIo9c3lM?usp=sharing
讨论总结
本次讨论主要聚焦于Google最新发布的Gemma-2 2b模型,该模型基于2万亿蒸馏数据训练,并提供了多种量化版本和优化后的微调方法。讨论内容包括模型的性能表现、资源节省策略以及在线工具的分享。用户对模型的更新和优化表示赞赏,尤其是微调速度的提升和VRAM使用的减少。总体上,讨论氛围积极,技术细节丰富,用户对新技术的接受度和支持度较高。
主要观点
- 👍 Gemma-2 2b模型的发布
- 支持理由:基于2万亿蒸馏数据训练,性能优越。
- 反对声音:无明显反对声音。
- 🔥 微调优化和资源节省
- 正方观点:微调速度提升2倍,VRAM使用减少63%。
- 反方观点:无明显反方观点。
- 💡 在线工具和资源分享
- 解释:提供了免费的Colab笔记本和GitHub链接,方便用户进行微调和资源优化。
金句与有趣评论
- “😂 Was waiting for this one.”
- 亮点:用户对新模型的期待和兴奋。
- “🤔 Your colab notebooks are a gift to humanity”
- 亮点:对作者分享工具的感激和认可。
- “👀 Yes it should still function relatively well!”
- 亮点:对量化后模型性能的肯定。
情感分析
讨论的总体情感倾向积极,用户对新模型的发布和优化表示赞赏。主要分歧点在于对新技术声明的初始怀疑,但随着时间的推移,用户逐渐认识到技术的真实性和可靠性。这种转变体现了用户对技术更新的接受和信任建立过程。
趋势与预测
- 新兴话题:Flash Attention v2的支持和长上下文微调的优化。
- 潜在影响:对AI模型微调和资源优化的进一步推动,可能引发更多相关技术的讨论和应用。


感谢您的耐心阅读!来选个表情,或者留个评论吧!