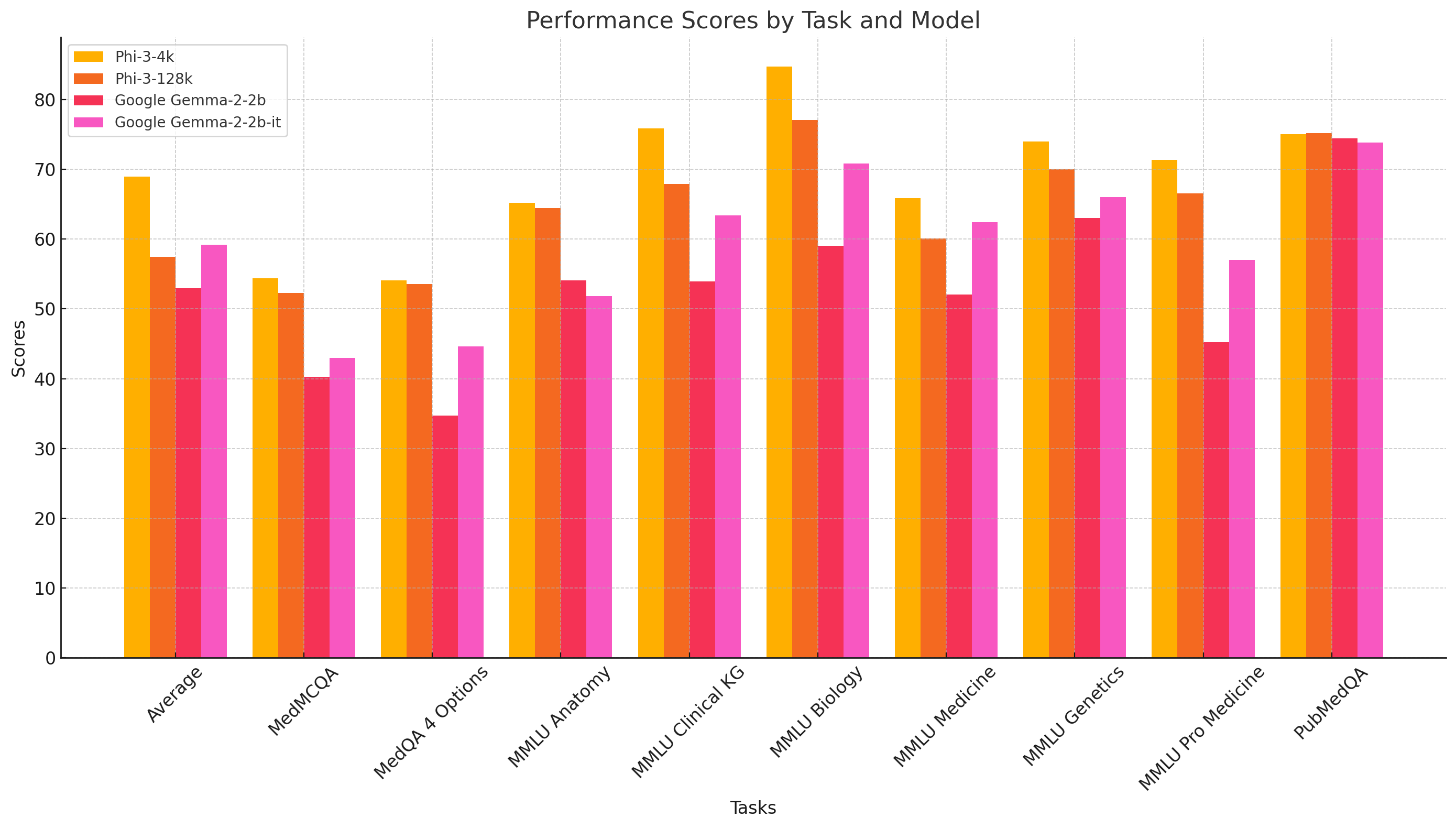
探索谷歌的Gemma-2-2b-it和微软的Phi-3-4k模型在医疗领域的性能表现(未经微调)
谷歌的Gemma-2-2b-it平均表现得分达到59.21%,而微软的Phi-3-4k以68.93%领先。
将很快评估更多医疗领域的小型模型 来源帖子
讨论总结
本次讨论主要聚焦于Google的Gemma-2-2b-it和Microsoft的Phi-3-4k在医疗领域的性能比较。评论者们对作者的工作表示感谢,同时也提出了对图表颜色选择的不满。讨论中涉及了模型的微调技术、数据集的使用以及小型语言模型在医疗领域的应用前景。此外,还有评论者提出了对模型版本的疑问,以及一些技术幽默的评论。
主要观点
- 👍 Google的Gemma-2-2b-it在医疗领域表现良好
- 支持理由:平均得分59.21%,显示出一定的性能。
- 反对声音:无明显反对声音。
- 🔥 Microsoft的Phi-3-4k在医疗领域表现更佳
- 正方观点:平均得分68.93%,领先于Google的模型。
- 反方观点:无明显反对声音。
- 💡 小型语言模型不应仅用于医疗问答
- 解释:应更多用于自动化任务和预测,而不仅仅是问答。
- 👀 通过基准测试可以评估模型的医疗知识水平
- 解释:对医疗预测有帮助,了解模型知识水平是关键。
- 🌍 在医疗资源匮乏的地区,聊天机器人提供基础答案可能比没有使用更有益
- 解释:简单的聊天机器人可以提供基础帮助,特别是在资源匮乏地区。
金句与有趣评论
- “😂 Thanks for doing this but i hate your graph color choices lol”
- 亮点:评论者对图表颜色选择的不满,带有幽默感。
- “🤔 I don’t understand why people evaluate LLMs, especially smaller models, on medical QA datasets.”
- 亮点:对小型语言模型在医疗问答数据集上的评估表示不解。
- “👀 I just created the smallest sane healthcare model (<4.0K) in the world… use ‘zcat doctor.txt’ to get your answers.. /s”
- 亮点:评论者幽默地分享了一个极小的医疗模型,带有讽刺标记。
情感分析
讨论的总体情感倾向较为积极,多数评论者对作者的工作表示感谢。然而,也有评论者对图表设计表示不满,以及对模型版本和使用方法的质疑。情感上的分歧主要集中在对模型性能的评价和对图表设计的批评上。
趋势与预测
- 新兴话题:小型语言模型在医疗领域的应用前景和微调技术的进一步探讨。
- 潜在影响:这些模型的性能提升和应用扩展可能对医疗资源匮乏地区产生积极影响,提供更多基础医疗支持。


感谢您的耐心阅读!来选个表情,或者留个评论吧!