我看到很多人在寻找LLama 3.1采样器的最佳点时遇到困难。
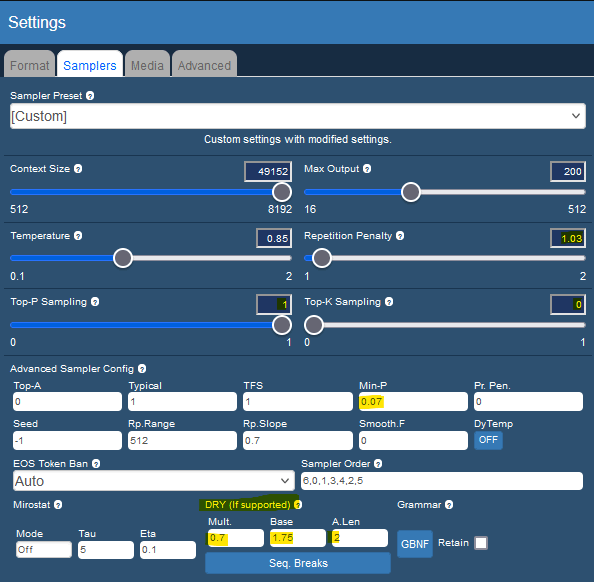
关键是要禁用top-P、top-K,并使用非常低的重复惩罚(大约1.02)。 使用min-P(大约0.05)和DRY代替。这些方法更好,而且DRY在不损害模型的情况下更好地防止重复。
对于大约50K上下文大小的RP,我仍然能得到非常连贯、多样化和有创意的回复,同时模型仍然聪明,不会对自己的角色感到困惑。与默认设置相比,这是一个巨大的进步。值得尝试更现代的模型,因为旧的采样器现在确实过时了,会导致更多问题。
(所有功劳归于这篇文章和这个人: https://www.reddit.com/r/LocalLLaMA/comments/17vonjo/your_settings_are_probably_hurting_your_model_why/)
此外,你可以修改默认的用户和助手标签,让模型知道它是谁。
示例:
<|eot_id|><|start_header_id|>Guest<|end_header_id|>\n\n <|eot_id|><|start_header_id|>TavernKeeper<|end_header_id|>\n\n
对于Koboldcpp用户,我还推荐使用Memory、World info和Assistant标签。这些都是改变游戏规则的设置。
讨论总结
本次讨论主要集中在如何通过调整LLama 3.1的采样器设置来优化模型表现。许多用户分享了他们的经验,包括禁用top-P和top-K,使用非常低的重复惩罚(约1.02),以及推荐使用min-P(约0.05)和DRY。这些设置被认为可以提高模型的连贯性和创造性,同时避免重复。此外,还有关于修改默认的用户和助手标签,以及推荐Koboldcpp用户使用Memory、World info和Assistant标签的讨论。讨论中也有一些质疑声音,特别是关于修改默认标签可能导致的潜在问题。
主要观点
- 👍 禁用top-P和top-K,使用非常低的重复惩罚(约1.02)
- 支持理由:这些设置可以提高模型的连贯性和创造性,同时避免重复。
- 反对声音:无明显反对声音,但有用户提到需要根据具体情况调整参数。
- 🔥 使用min-P(约0.05)和DRY
- 正方观点:这些设置可以更好地防止重复,且不会损害模型性能。
- 反方观点:有用户提到DRY在某些情况下可能导致重复问题,需要适当调整参数。
- 💡 修改默认的用户和助手标签
- 支持理由:可以更好地定义模型的角色。
- 反对声音:有用户质疑这种修改可能导致模型无法正常工作。
- 💡 推荐Koboldcpp用户使用Memory、World info和Assistant标签
- 支持理由:这些设置被认为是游戏规则改变者,可以显著提升模型表现。
- 反对声音:无明显反对声音。
金句与有趣评论
- “😂 Use min-P (around 0.05) and DRY instead.”
- 亮点:简洁明了地提出了优化建议。
- “🤔 DRY author here. Your Min-P is too high. 0.1 is way too much with current models, and even 0.05 is too high IMO.”
- 亮点:DRY方法的原作者亲自参与讨论,提供了具体参数建议。
- “👀 What makes you think you can do this? The instruct training was done with the tags in the official template… if you use anything else, they are not working.”
- 亮点:对修改默认标签的做法提出了质疑,强调了官方模板的重要性。
情感分析
讨论的总体情感倾向较为积极,大多数用户对优化模型设置持支持态度,并分享了他们的成功经验。然而,也有一些用户对某些设置提出了质疑,特别是关于修改默认标签可能导致的潜在问题。这种分歧主要源于对模型训练基础和参数调整的不同理解。
趋势与预测
- 新兴话题:DRY采样方法的进一步优化和应用,以及Koboldcpp用户如何更好地利用Memory、World info和Assistant标签。
- 潜在影响:这些优化设置可能会对LLama 3.1模型的性能产生显著影响,特别是在处理长上下文和避免重复方面。随着更多用户的尝试和反馈,这些设置可能会成为未来模型优化的标准做法。


感谢您的耐心阅读!来选个表情,或者留个评论吧!