嗨,
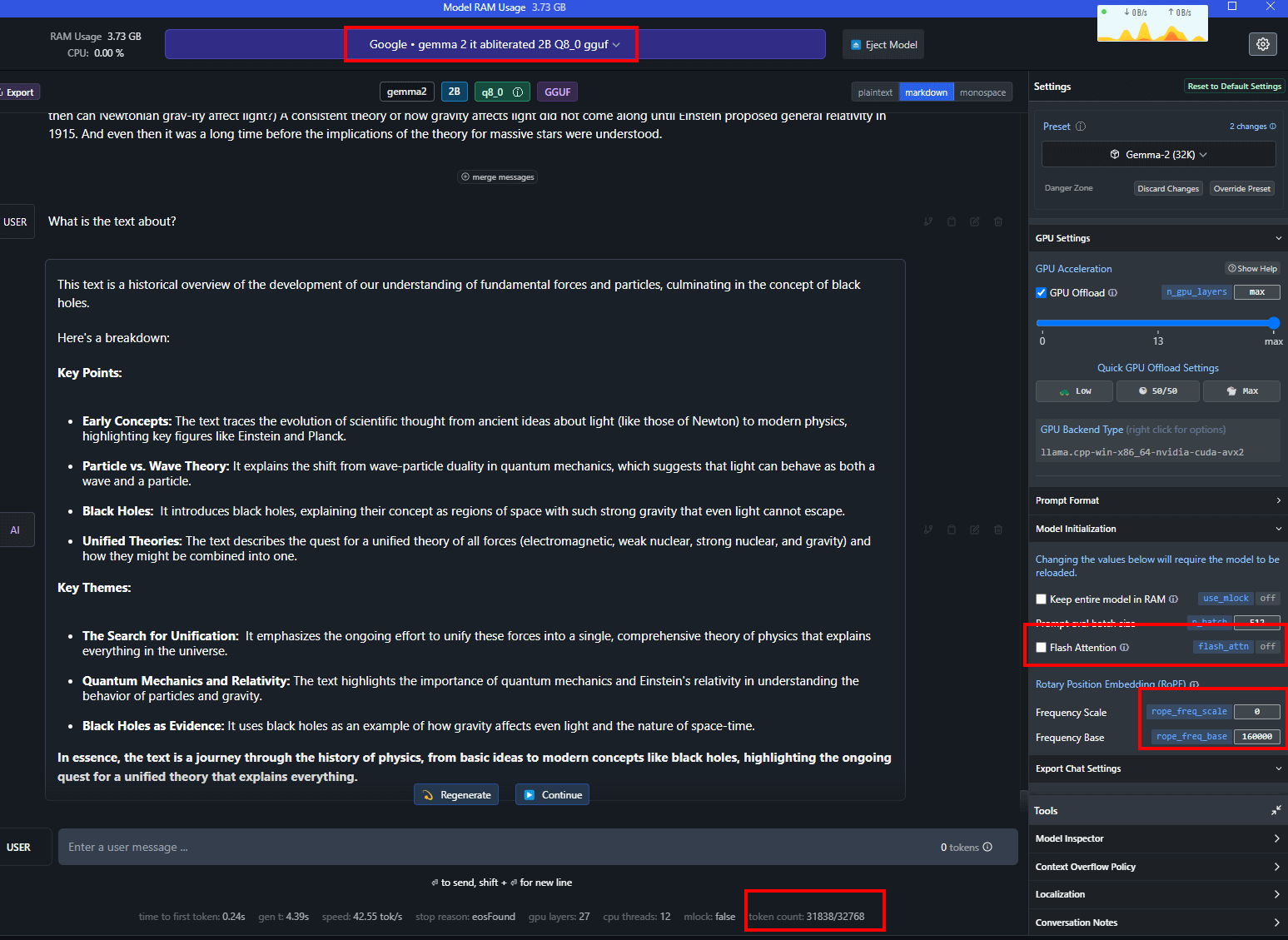
这篇帖子只是提醒您,您可以通过使用RoPE频率基底160000来扩展任何Gemma-2模型的上下文大小,包括2B模型,如下面的截图所示,
该模型保持连贯性,这是Google令人印象深刻的成果。
祝您使用愉快!
讨论总结
本次讨论主要聚焦于如何通过使用RoPE Frequency Base 160000来扩展Gemma-2-2b模型的上下文大小,并探讨了这一扩展在不同基准测试中的表现。讨论中涉及了对模型性能的怀疑、测试方法的有效性以及模型在长上下文处理中的连贯性问题。参与者提出了多种观点,包括对现有测试方法的质疑和对更合适测试方法的建议。
主要观点
- 👍 扩展模型上下文大小并不意味着模型能有效处理长上下文
- 支持理由:超过8k的上下文处理时,模型常返回不相关或虚构的信息。
- 反对声音:需要更合适的测试方法,如“needle in the haystack”或针对特定内容的测试。
- 🔥 Gemma-2-2b模型可以通过使用RoPE Frequency Base 160000来扩展上下文大小
- 正方观点:这种方法不仅限于LM Studio,其他应用程序也可以支持。
- 反方观点:需要对扩展后的模型进行基准测试以验证其效果。
- 💡 “needle in haystack”测试不适用于评估模型在长上下文中的表现
- 解释:该测试主要衡量检索能力,不适用于评估模型在长上下文中的表现。
金句与有趣评论
- “😂 vasileer:what is the score with these settings in "needle in a haystack" and RULER benchmarks?”
- 亮点:直接询问特定设置在基准测试中的表现,体现了对模型性能的实际关注。
- “🤔 AdHominemMeansULost:Anything over 8k and you’re getting hallucinations and irrelevant information back 90% of the time.”
- 亮点:指出了模型在处理长上下文时的常见问题,引发了对模型连贯性的讨论。
- “👀 LoafyLemon:On the contrary, I’d say needle in haystack is a terrible test to test reasoning and comprehensibility of the text in long context.”
- 亮点:对现有测试方法的有效性提出质疑,推动了对更合适测试方法的探讨。
情感分析
讨论的总体情感倾向较为技术性和批判性,参与者对模型的扩展和测试方法持有不同意见。主要分歧点在于模型在长上下文处理中的表现和测试方法的有效性。可能的原因包括对新技术的不确定性和对现有测试方法的怀疑。
趋势与预测
- 新兴话题:对Gemma-2-2b模型扩展上下文大小的实际应用效果和更合适的测试方法的探讨可能会引发后续讨论。
- 潜在影响:对模型性能的深入讨论可能会推动相关领域的技术进步和测试方法的改进。


感谢您的耐心阅读!来选个表情,或者留个评论吧!