大家好!
正如你们许多人所知,各种LLM基准的可靠性一直是我们社区讨论的话题[1], [2], [3]。越来越明显的是,我们需要更准确和有意义的基准来评估LLM在现实场景中的表现。这就是为什么我们继续开发ProLLM排行榜。在这里查看:https://prollm.toqan.ai/leaderboard
新基准
自我们上次发布以来,我们增加了多个新任务(其中一些是多语言的):
- StackUnseen(英语):一个独特的交互式基准,使用Stack Overflow最近三个月未发布数据中的质量过滤的Q&A来测试模型在最近的现实世界编码问题上的表现。
- 实体提取(波兰语):从实际的招聘广告中提取给定的感兴趣实体,以提高OLX招聘门户网站中广告的可发现性。此基准可以了解LLM在不太流行的语言中的整体实体提取和标记性能。
- 函数调用(英语):评估LLM解释请求并调用具有正确参数的适当函数的能力。随着基于代理的系统成为主流,这种能力对于与外部工具的集成至关重要。
- SQL消歧(葡萄牙语):随着企业越来越多地使用LLM进行SQL生成,我们正在评估这些模型识别问题歧义并确定何时需要澄清的能力。这是LLM倾向于失败的最具挑战性的领域。
有趣的发现
我们在基准测试中观察到了一些有趣的规律。一些排行榜将Llama3.1-405B排名很高[4],但它在我们的排行榜上的表现却不尽如人意。我们创建了一个表格,比较了LMSYS聊天机器人竞技场上一些最受欢迎和排名最高的模型。
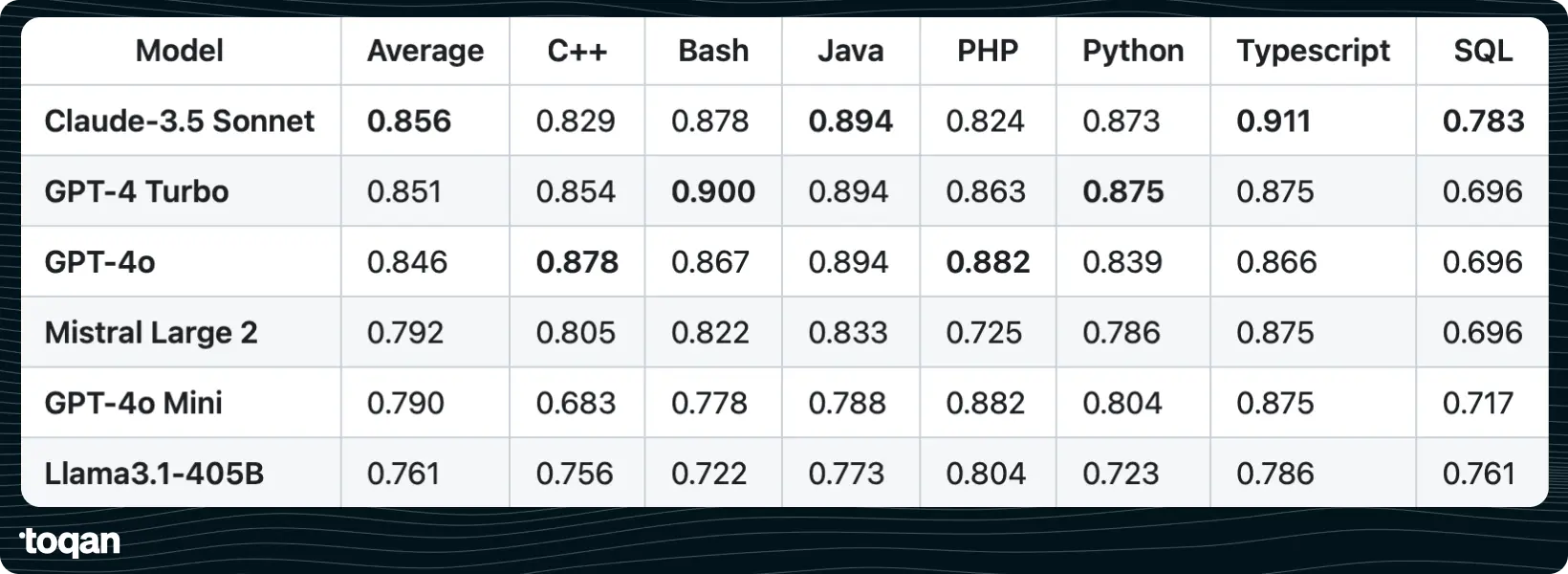
我们的部分发现也得到了Mistral的新闻发布(图2和表1)的确认。此表格仅汇总了我们的排行榜。我们网站上的完整版本(https://prollm.toqan.ai/leaderboard)是完全交互式的。您可以按语言、难度和问题类型过滤结果,以获得与您的兴趣或工作相关的内容。随时探索并查看您关心的领域中不同模型的表现。
下一步
我们正在积极使用从我们集团公司的多样化评估集扩展我们的基准。接下来:OpenBook Q&A,测试不同模型在RAG风格的问题回答上的表现。我们一直在寻求改进我们的基准。如果您有任何想法或面临的特定行业挑战,请告诉我们!
讨论总结
本次讨论主要集中在ProLLM的新基准更新,包括编程、实体提取、函数调用和SQL查询消歧等实际应用。用户对模型的排名、评估方法以及新技术的版本表现出浓厚兴趣,同时也对模型的实际应用能力和量化版本进行了深入探讨。讨论中既有对现有基准的认可,也有对未来技术发展的期待。
主要观点
- 👍 ProLLM的新基准更新
- 支持理由:引入了新的实际应用基准,如编程、实体提取等,更贴近现实需求。
- 反对声音:部分用户认为当前基准可能过于简单,不足以区分未来接近的模型。
- 🔥 模型排名和评估方法
- 正方观点:用户对模型的排名和评估方法表现出浓厚兴趣,认为这是评价模型性能的关键。
- 反方观点:有用户质疑评估方法的公正性,特别是使用GPT-4 Turbo进行自动评估。
- 💡 新技术版本和量化模型
- 用户对新发布的Gemini预览版和量化模型表现出浓厚兴趣,期待这些新技术能被纳入基准测试。
金句与有趣评论
- “😂 Thanks for your hard work but you should really sort that chart better.”
- 亮点:ServeAlone7622指出了表格排序问题,反映了用户对数据呈现的重视。
- “🤔 I think the benchmark looks a little too easy–those scores don’t leave a lot of room for differentiating near-future models.”
- 亮点:DeProgrammer99对基准的难度提出了质疑,引发了对基准设计的深入思考。
- “👀 Very nice! Would be cool to see the new Gemini preview added.”
- 亮点:TheRealGentlefox对新技术的期待,反映了用户对技术进步的热情。
情感分析
讨论的总体情感倾向较为积极,用户对ProLLM的新基准更新表示认可,并对模型的实际应用能力表现出浓厚兴趣。主要分歧点在于基准的难度和评估方法的公正性,部分用户认为当前基准可能过于简单,不足以区分未来接近的模型。
趋势与预测
- 新兴话题:未来可能会看到更多关于新技术版本(如Gemini预览版)和量化模型的讨论。
- 潜在影响:ProLLM的新基准更新可能会推动更多实际应用场景的开发,特别是在编程和实体提取等领域。
详细内容:
《ProLLM 更新:全新真实世界基准测试》
Reddit 上有一则关于 ProLLM 更新的热门帖子引起了广泛关注,点赞数众多,评论区也十分热闹。原帖主要介绍了 ProLLM 新增的多项用于评估语言模型(LLM)在真实场景中的任务基准测试,还分享了一些有趣的发现,并提及了未来的计划。帖子获得的链接包括https://www.reddit.com/r/LocalLLaMA/comments/1ean2i6/the_final_straw_for_lmsys/、https://www.reddit.com/r/LocalLLaMA/comments/1ehlg6g/comment/lg2827i、https://www.reddit.com/r/LocalLLaMA/comments/1efw7ji/best_coding_leaderboard/以及https://prollm.toqan.ai/leaderboard。
文章将要探讨的核心问题是这些新的基准测试如何更准确地评估 LLM 在实际应用中的表现,以及它们对 LLM 发展的意义。
在讨论中,主要观点如下:
- 有用户对新的基准测试表示赞赏,认为这对于评估 LLM 在真实场景中的能力十分有意义。
- 但也有声音质疑这些基准测试的全面性和准确性。
有趣的是,在观察到的模式中,一些排行榜对 Llama3.1-405B 评价颇高,但在这个新的 ProLLM 领导者排行榜中表现不佳。
同时,讨论中也存在一定的共识,即大家都期待更完善和有效的基准测试,以推动 LLM 领域的发展。
特别有见地的观点如:一位用户提到“非常不错!要是能看到新的 Gemini 预览版加入就更棒了。” 这一观点丰富了对于未来 LLM 发展的期待。
总之,这次关于 ProLLM 更新的讨论展现了大家对 LLM 评估标准的关注和思考,也为该领域的进一步发展提供了多样的视角和建议。


感谢您的耐心阅读!来选个表情,或者留个评论吧!