This Hugging Face guide by Maxime Labonne we will provide a comprehensive overview of supervised fine-tuning by using Unsloth.
It will detail when it makes sense to use fine-tuning over RAG & prompting, detail the main techniques with their pros and cons, and introduce concepts, such as LoRA hyperparameters, storage formats, and chat templates. Finally, we will implement it in practice by fine-tuning Llama 3.1 8B in Google Colab.
Full blog with explanation + pics: https://huggingface.co/blog/mlabonne/sft-llama3
Colab notebook: https://colab.research.google.com/drive/164cg_O7SV7G8kZr_JXqLd6VC7pd86-1Z#scrollTo=PoPKQjga6obNhttps://i.imgur.com/jUDo6ID.jpeg
🔧 Supervised Fine-Tuning
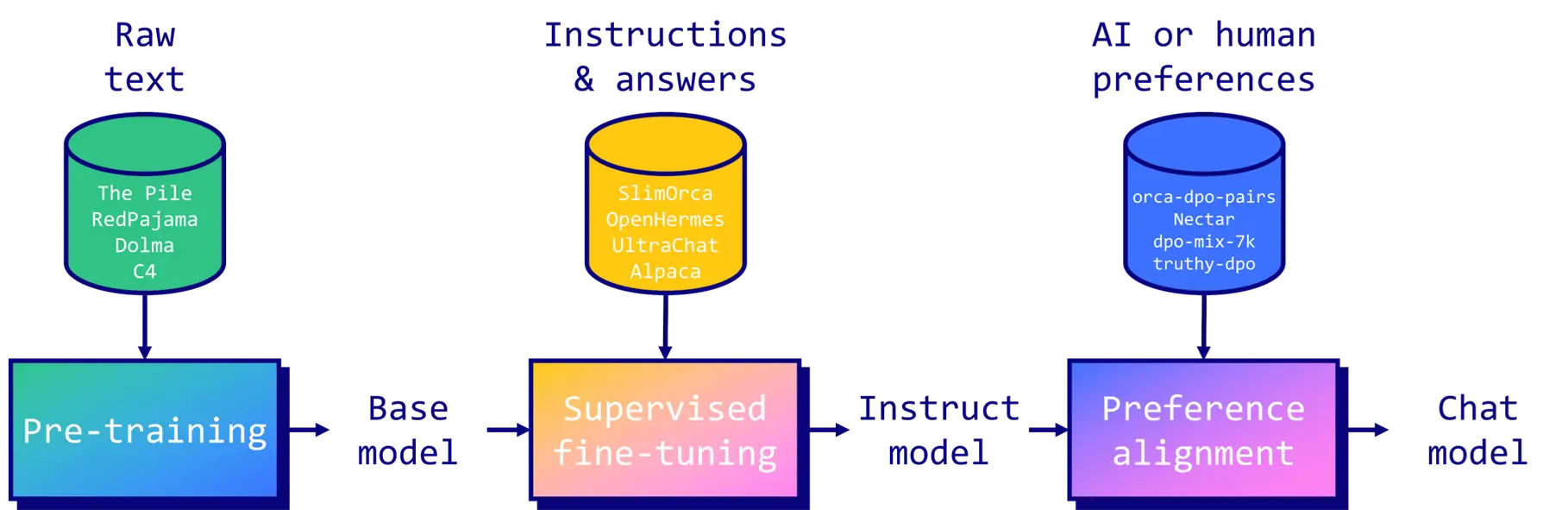
Supervised Fine-Tuning (SFT) is a method to improve and customize pre-trained LLMs. It involves retraining base models on a smaller dataset of instructions and answers. The main goal is to transform a basic model that predicts text into an assistant that can follow instructions and answer questions. SFT can also enhance the model’s overall performance, add new knowledge, or adapt it to specific tasks and domains. Fine-tuned models can then go through an optional preference alignment stage (see my article about DPO) to remove unwanted responses, modify their style, and more.
The following figure shows an instruction sample. It includes a system prompt to steer the model, a user prompt to provide a task, and the output the model is expected to generate. You can find a list of high-quality open-source instruction datasets in the 💾 LLM Datasets GitHub repo.
Before considering SFT, I recommend trying prompt engineering techniques like few-shot prompting or retrieval augmented generation (RAG). In practice, these methods can solve many problems without the need for fine-tuning, using either closed-source or open-weight models (e.g., Llama 3.1 Instruct). If this approach doesn’t meet your objectives (in terms of quality, cost, latency, etc.), then SFT becomes a viable option when instruction data is available. Note that SFT also offers benefits like additional control and customizability to create personalized LLMs.
However, SFT has limitations. It works best when leveraging knowledge already present in the base model. Learning completely new information like an unknown language can be challenging and lead to more frequent hallucinations. For new domains unknown to the base model, it is recommended to continuously pre-train it on a raw dataset first.
On the opposite end of the spectrum, instruct models (i.e., already fine-tuned models) can already be very close to your requirements. For example, a model might perform very well but state that it was trained by OpenAI or Meta instead of you. In this case, you might want to slightly steer the instruct model’s behavior using preference alignment. By providing chosen and rejected samples for a small set of instructions (between 100 and 1000 samples), you can force the LLM to say that you trained it instead of OpenAI.
⚖️ SFT Techniques
The three most popular SFT techniques are full fine-tuning, LoRA, and QLoRA.
Full fine-tuning is the most straightforward SFT technique. It involves retraining all parameters of a pre-trained model on an instruction dataset. This method often provides the best results but requires significant computational resources (several high-end GPUs are required to fine-tune a 8B model). Because it modifies the entire model, it is also the most destructive method and can lead to the catastrophic forgetting of previous skills and knowledge.
Low-Rank Adaptation (LoRA) is a popular parameter-efficient fine-tuning technique. Instead of retraining the entire model, it freezes the weights and introduces small adapters (low-rank matrices) at each targeted layer. This allows LoRA to train a number of parameters that is drastically lower than full fine-tuning (less than 1%), reducing both memory usage and training time. This method is non-destructive since the original parameters are frozen, and adapters can then be switched or combined at will.
QLoRA (Quantization-aware Low-Rank Adaptation) is an extension of LoRA that offers even greater memory savings. It provides up to 33% additional memory reduction compared to standard LoRA, making it particularly useful when GPU memory is constrained. This increased efficiency comes at the cost of longer training times, with QLoRA typically taking about 39% more time to train than regular LoRA.
While QLoRA requires more training time, its substantial memory savings can make it the only viable option in scenarios where GPU memory is limited. For this reason, this is the technique we will use in the next section to fine-tune a Llama 3.1 8B model on Google Colab.
🦙 Fine-Tune Llama 3.1 8B Guide:
To efficiently fine-tune a Llama 3.1 8B model, we’ll use the Unsloth library by Daniel and Michael Han. Thanks to its custom kernels, Unsloth provides 2x faster training and 60% memory use compared to other options, making it ideal in a constrained environment like Colab. Unfortunately, Unsloth only supports single-GPU settings at the moment.
In this example, we will QLoRA fine-tune it on the mlabonne/FineTome-100k dataset. Note that this classifier wasn’t designed for instruction data quality evaluation, but we can use it as a rough proxy. The resulting FineTome is an ultra-high quality dataset that includes conversations, reasoning problems, function calling, and more.
Let’s start by installing all the required libraries.
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers<0.0.27" "trl<0.9.0" peft accelerate bitsandbytes
Once installed, we can import them as follows.
import torch
from trl import SFTTrainer
from datasets import load_dataset
from transformers import TrainingArguments, TextStreamer
from unsloth.chat_templates import get_chat_template
from unsloth import FastLanguageModel, is_bfloat16_supported
Let’s now load the model. Since we want to use QLoRA, I chose the pre-quantized unsloth/Meta-Llama-3.1-8B-bnb-4bit. This 4-bit precision version of meta-llama/Meta-Llama-3.1-8B is significantly smaller (5.4 GB) and faster to download compared to the original 16-bit precision model (16 GB). We load in NF4 format using the bitsandbytes library.
When loading the model, we must specify a maximum sequence length, which restricts its context window. Llama 3.1 supports up to 128k context length, but we will set it to 2,048 in this example since it consumes more compute and VRAM. Finally, the dtype parameter automatically detects if your GPU supports the BF16 format for more stability during training (this feature is restricted to Ampere and more recent GPUs).
max_seq_length = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length=max_seq_length,
load_in_4bit=True,
dtype=None,
)
Now that our model is loaded in 4-bit precision, we want to prepare it for parameter-efficient fine-tuning with LoRA adapters. LoRA has three important parameters:
- Rank (r), which determines LoRA matrix size. Rank typically starts at 8 but can go up to 256. Higher ranks can store more information but increase the computational and memory cost of LoRA. We set it to 16 here.
- Alpha (α), a scaling factor for updates. Alpha directly impacts the adapters’ contribution and is often set to 1x or 2x the rank value.
- Target modules: LoRA can be applied to various model components, including attention mechanisms (Q, K, V matrices), output projections, feed-forward blocks, and linear output layers. While initially focused on attention mechanisms, extending LoRA to other components has shown benefits. However, adapting more modules increases the number of trainable parameters and memory needs.
Here, we set r=16, α=16, and target every linear module to maximize quality. We don’t use dropout and biases for faster training.
In addition, we will use Rank-Stabilized LoRA (rsLoRA), which modifies the scaling factor of LoRA adapters to be proportional to 1/√r instead of 1/r. This stabilizes learning (especially for higher adapter ranks) and allows for improved fine-tuning performance as rank increases. Gradient checkpointing is handled by Unsloth to offload input and output embeddings to disk and save VRAM.
model = FastLanguageModel.get_peft_model(
model,
r=16,
lora_alpha=16,
lora_dropout=0,
target_modules=["q_proj", "k_proj", "v_proj", "up_proj", "down_proj", "o_proj", "gate_proj"],
use_rslora=True,
use_gradient_checkpointing="unsloth"
)
With this LoRA configuration, we’ll only train 42 million out of 8 billion parameters (0.5196%). This shows how much more efficient LoRA is compared to full fine-tuning.
Let’s now load and prepare our dataset. Instruction datasets are stored in a particular format: it can be Alpaca, ShareGPT, OpenAI, etc. First, we want to parse this format to retrieve our instructions and answers. Our mlabonne/FineTome-100k dataset uses the ShareGPT format with a unique “conversations” column containing messages in JSONL. Unlike simpler formats like Alpaca, ShareGPT is ideal for storing multi-turn conversations, which is closer to how users interact with LLMs.
Once our instruction-answer pairs are parsed, we want to reformat them to follow a chat template. Chat templates are a way to structure conversations between users and models. They typically include special tokens to identify the beginning and the end of a message, who’s speaking, etc. Base models don’t have chat templates so we can choose any: ChatML, Llama3, Mistral, etc. In the open-source community, the ChatML template (originally from OpenAI) is a popular option. It simply adds two special tokens (<|im_start|> and <|im_end|>) to indicate who’s speaking.
If we apply this template to the previous instruction sample, here’s what we get:
<|im_start|>system
You are a helpful assistant, who always provide explanation. Think like you are answering to a five year old.<|im_end|>
<|im_start|>user
Remove the spaces from the following sentence: It prevents users to suspect that there are some hidden products installed on theirs device.
<|im_end|>
<|im_start|>assistant
Itpreventsuserstosuspectthattherearesomehiddenproductsinstalledontheirsdevice.<|im_end|>
In the following code block, we parse our ShareGPT dataset with the mapping parameter and include the ChatML template. We then load and process the entire dataset to apply the chat template to every conversation.
tokenizer = get_chat_template(
tokenizer,
mapping={"role": "from", "content": "value", "user": "human", "assistant": "gpt"},
chat_template="chatml",
)
def apply_template(examples):
messages = examples["conversations"]
text = [tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=False) for message in messages]
return {"text": text}
dataset = load_dataset("mlabonne/FineTome-100k", split="train")
dataset = dataset.map(apply_template, batched=True)
We’re now ready to specify the training parameters for our run. I want to briefly introduce the most important hyperparameters:
- Learning rate: It controls how strongly the model updates its parameters. Too low, and training will be slow and may get stuck in local minima. Too high, and training may become unstable or diverge, which degrades performance.
- LR scheduler: It adjusts the learning rate (LR) during training, starting with a higher LR for rapid initial progress and then decreasing it in later stages. Linear and cosine schedulers are the two most common options.
- Batch size: Number of samples processed before the weights are updated. Larger batch sizes generally lead to more stable gradient estimates and can improve training speed, but they also require more memory. Gradient accumulation allows for effectively larger batch sizes by accumulating gradients over multiple forward/backward passes before updating the model.
- Num epochs: The number of complete passes through the training dataset. More epochs allow the model to see the data more times, potentially leading to better performance. However, too many epochs can cause overfitting.
- Optimizer: Algorithm used to adjust the parameters of a model to minimize the loss function. In practice, AdamW 8-bit is strongly recommended: it performs as well as the 32-bit version while using less GPU memory. The paged version of AdamW is only interesting in distributed settings.
- Weight decay: A regularization technique that adds a penalty for large weights to the loss function. It helps prevent overfitting by encouraging the model to learn simpler, more generalizable features. However, too much weight decay can impede learning.
- Warmup steps: A period at the beginning of training where the learning rate is gradually increased from a small value to the initial learning rate. Warmup can help stabilize early training, especially with large learning rates or batch sizes, by allowing the model to adjust to the data distribution before making large updates.
- Packing: Batches have a pre-defined sequence length. Instead of assigning one batch per sample, we can combine multiple small samples in one batch, increasing efficiency.
I trained the model on the entire dataset (100k samples) using an A100 GPU (40 GB of VRAM) on Google Colab. The training took 4 hours and 45 minutes. Of course, you can use smaller GPUs with less VRAM and a smaller batch size, but they’re not nearly as fast. For example, it takes roughly 19 hours and 40 minutes on an L4 and a whopping 47 hours on a free T4.
In this case, I recommend only loading a subset of the dataset to speed up training. You can do it by modifying the previous code block, like dataset = load_dataset("mlabonne/FineTome-100k", split="train[:10000]") to only load 10k samples.
trainer=SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
packing=True,
args=TrainingArguments(
learning_rate=3e-4,
lr_scheduler_type="linear",
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
num_train_epochs=1,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.01,
warmup_steps=10,
output_dir="output",
seed=0,
),
)
trainer.train()
Now that the model is trained, let’s test it with a simple prompt. This is not a rigorous evaluation but just a quick check to detect potential issues. We use FastLanguageModel.for_inference() to get 2x faster inference.
model = FastLanguageModel.for_inference(model)
messages = [
{"from": "human", "value": "Is 9.11 larger than 9.9?"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(input_ids=inputs, streamer=text_streamer, max_new_tokens=128, use_cache=True)
The model’s response is “9.9”, which is correct!
Let’s now save our trained model. If you remember the part about LoRA and QLoRA, what we trained is not the model itself but a set of adapters. There are three save methods in Unsloth: lora to only save the adapters, and merged_16bit/merged_4bit to merge the adapters with the model in 16-bit/ 4-bit precision.
In the following, we merge them in 16-bit precision to maximize the quality. We first save it locally in the “model” directory and then upload it to the Hugging Face Hub. You can find the trained model on mlabonne/FineLlama-3.1-8B.
model.save_pretrained_merged("model", tokenizer, save_method="merged_16bit")
model.push_to_hub_merged("mlabonne/FineLlama-3.1-8B", tokenizer, save_method="merged_16bit")
Unsloth also allows you to directly convert your model into GGUF format. This is a quantization format created for llama.cpp and compatible with most inference engines, like Ollama, and oobabooga’s text-generation-webui. Since you can specify different precisions (see my article about GGUF and llama.cpp), we’ll loop over a list to quantize it in q2_k, q3_k_m, q4_k_m, q5_k_m, q6_k, q8_0 and upload these quants on Hugging Face. The mlabonne/FineLlama-3.1-8B-GGUF contains all our GGUFs.
quant_methods = ["q2_k", "q3_k_m", "q4_k_m", "q5_k_m", "q6_k", "q8_0"]
for quant in quant_methods:
model.push_to_hub_gguf("mlabonne/FineLlama-3.1-8B-GGUF", tokenizer, quant)
Congratulations, we fine-tuned a model from scratch and uploaded quants you can now use in your favorite inference engine. Feel free to try the final model available on mlabonne/FineLlama-3.1-8B-GGUF. What to do now? Here are some ideas on how to use your model:
- Evaluate it on the Open LLM Leaderboard (you can submit it for free) or using other evals like in LLM AutoEval.
- Align it with Direct Preference Optimization using a preference dataset like mlabonne/orpo-dpo-mix-40k to boost performance.
- Quantize it in other formats like EXL2, AWQ, GPTQ, or HQQ for faster inference or lower precision using AutoQuant.
- Deploy it on a Hugging Face Space with ZeroChat for models that have been sufficiently trained to follow a chat template (~20k samples).
Full blog: https://huggingface.co/blog/mlabonne/sft-llama3
讨论总结
本次讨论主要围绕Maxime Labonne在Hugging Face上发布的关于如何高效微调Llama 3.1模型的指南展开。讨论内容涵盖了LoRA技术的使用、信息损失问题、模型定制的需求以及实验中遇到的具体问题。参与者们对指南表示感谢,并就如何在不使用LoRA的情况下微调特定层进行了深入的技术探讨。此外,还有用户提出了对简化调优工具的需求,以及在实验中使用特定数据集进行DPO训练后模型性能下降的问题。
主要观点
- 👍 感谢Maxime Labonne的指南
- 支持理由:指南被认为是一个优秀的资源,对微调模型提供了详细的指导。
- 反对声音:无
- 🔥 关于LoRA技术的讨论
- 正方观点:LoRA技术在参数高效微调中表现出色,减少了内存使用和训练时间。
- 反方观点:有用户提出在不使用LoRA的情况下微调特定层的需求,担心信息损失和对预训练网络的覆盖。
- 💡 信息损失问题的讨论
- 解释:用户分享了关于预训练过程中信息损失的讨论,提供了相关博客文章链接。
- 💡 对简化调优工具的需求
- 解释:有用户认为现有的调优过程过于复杂,需要一个更简单直观的拖放式工具。
- 💡 实验中遇到的问题
- 解释:用户在实验中使用特定数据集进行DPO训练后,发现模型性能下降,寻求可能的原因解释。
金句与有趣评论
- “😂 Thanks Maxime for making such an excellent guide!”
- 亮点:直接表达了对指南的赞赏和感谢。
- “🤔 Is there a way to fine-tune a specific layer without using LoRA?”
- 亮点:提出了一个具体的技术问题,引发了关于模型定制的讨论。
- “👀 By now with the advancements I believe there should be a drag and drop tuning tool.”
- 亮点:提出了对简化调优工具的需求,反映了用户对技术进步的期待。
情感分析
讨论的总体情感倾向是积极的,大多数用户对指南表示感谢和赞赏。然而,也有用户提出了具体的技术问题和实验中遇到的挑战,这表明在实际应用中仍存在一些技术和操作上的难题。主要分歧点在于如何在不使用LoRA的情况下微调特定层,以及如何简化调优过程。
趋势与预测
- 新兴话题:简化调优工具的需求可能会引发对更直观、用户友好的微调工具的开发。
- 潜在影响:随着技术的进步和用户需求的增加,未来可能会出现更多针对特定需求的微调技术和工具。
详细内容:
标题:深入探讨如何高效微调 Llama 3.1 并部署至 Hugging Face
一、引言以及帖子内容概述
在 Reddit 上,一篇关于如何高效微调 Llama 3.1 并部署至 Hugging Face 的帖子引起了广泛关注。该帖子由 Maxime Labonne 撰写,详细介绍了使用 Unsloth 进行监督微调的方法。帖子获得了众多点赞和评论,引发了关于微调技术、参数设置、优势与局限性等方面的热烈讨论。
文章将要探讨的核心问题包括:不同微调技术的效果和适用场景,如何解决在微调过程中可能遇到的问题,以及如何更好地利用微调后的模型。
二、讨论焦点与观点分析
- 微调技术的选择
- 全微调(Full fine-tuning)能提供最佳结果,但计算资源需求高,且可能导致灾难性遗忘。
- 低秩适应(LoRA)是一种高效的参数微调技术,能大幅减少参数训练量和内存使用。
- QLoRA 则在内存节省方面更进一步,适合 GPU 内存受限的情况,但训练时间较长。 例如:有用户分享道:“Full fine-tuning 虽然效果好,但对于一般用户来说,计算资源要求实在太高了。”
- 特定层的微调
- 用户 [sspsr] 提出是否有办法在不使用 LoRA 的情况下微调特定层,认为 LoRA 存在信息损失和过度覆盖预训练网络的问题。
- 有观点认为可以通过冻结不想训练的层来实现,如 [IngratefulMofo] 所说:“is this basically just freezing certain layers that you dont want to train, and unfreezing the other?”
- 相关链接如 http://pytorch.org/docs/master/notes/autograd.html#locally-disabling-gradient-computation 被提及以提供更多参考。
- 工具的发展与期望
- 用户 [Playful_Criticism425] 认为随着技术进步,应该有拖放式的微调工具。
- [yoracale] 回应称下周或下下周将推出 Unsloth UI。
- 实践中的问题
- 用户 [blepcoin] 提出使用文中提到的 orpo-dpo-mix-40k 数据集进行 DPO 训练后,模型在各方面表现显著变差,询问原因。
讨论中的共识在于大家都对高效、便捷的微调方法充满期待,同时也认识到不同技术各有优劣,需要根据实际情况选择。
特别有见地的观点如对特定层微调的思考,丰富了讨论的深度和广度。
总之,Reddit 上关于此话题的讨论展现了人们对 Llama 3.1 微调技术的关注和探索,为相关领域的研究和实践提供了有价值的参考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!