大家好!
想分享一下我们在初创公司(Aryn.ai)一直在构建的一些东西。我们遇到的最大挑战之一是从PDF文件中可靠地提取数据(表格、图像、文本)。例如,许多以PDF形式呈现的财务文件(如10-K、10-Q等)都以难以提取数据而著称。
我们训练的模型在处理10-K文件方面相当成功。在我深入介绍我们的方法细节之前,想先展示一下这个模型能做什么。
这里有一个例子,它检测10-K文件中页面的各个组件:
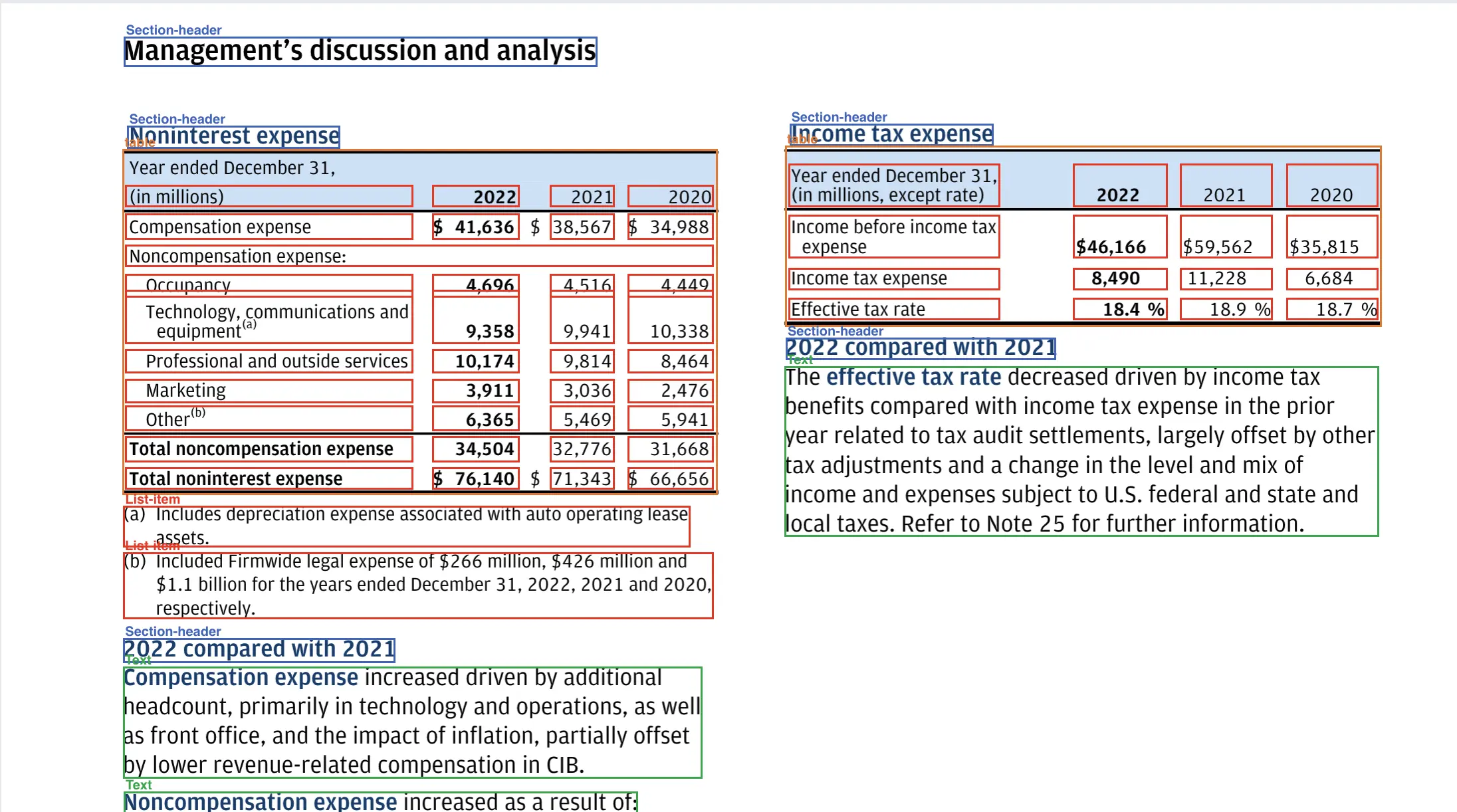
因为模型既能检测又能解释表格,我们可以将PDF中的表格转换为pandas数据框。这里有一个例子,我们从JP Morgan的10k文件第54页提取了第一个表格:
这里还有一个例子,它准确地检测到了图像、标题和页脚(来自Tesla的powerwall pdf):
这个的好处是,一旦提取了这些信息,你可以在向量数据库中索引这些元素,用于RAG类型的工作流程。如果你将标题与图像关联,或者生成图像的文本摘要,这可以实现更好的检索。
训练方法:
PDF文件难以分析,因为布局不一致、元数据质量差(段落、标题和表格的语义)以及格式通常很复杂。我们的开源模型是基于DocLayNet数据集训练的可变形DETR(查看模型)。训练方法首先将PDF转换为图像,然后运行卷积主干提取特征。提取特征后,我们通过编码器/解码器变换器架构运行这些特征,输出边界框(模型在PDF中检测到的元素)和标签(图像、标题、表格等)。我们将这些与真实值(我们使用DocLayNet进行训练)进行比较,并应用匈牙利匹配算法来优化匹配我们模型检测到的边界框与真实值边界框的损失。然后,为了优化标签的损失,我们应用交叉熵损失函数,这有助于我们优化模型的参数。
最后,为了实际检测模型检测到的所有元素(标题、文本框等)中的文本,我们使用OCR。
通过浏览器这里(完全免费注册!)尝试所有这些,以可视化标签和边界框。你还可以查看这个Colab笔记本,通过我们的SDK开始。我们输出边界框、标签和实际文档/表格文本为JSON(可用于构建聊天机器人、代理等)。我们正在寻求反馈,并希望听到你的想法!
讨论总结
本次讨论主要围绕Aryn.ai开发的PDF分割/分块技术展开,该技术旨在从PDF文档中可靠地提取数据,特别是在处理金融文档时表现出色。讨论中涉及了模型的技术细节、与其他解决方案的比较、商业化前景以及用户对数据安全的关注。总体上,讨论氛围较为技术性和探索性,用户对技术的实际应用和潜在改进表现出浓厚兴趣。
主要观点
- 👍 Aryn.ai开发的PDF分割/分块技术
- 支持理由:该技术在处理金融文档时表现出色,能够检测和解释表格,将其转换为pandas数据框。
- 反对声音:暂无明显反对声音,但有用户询问是否可以商业化并在本地运行。
- 🔥 技术比较
- 正方观点:有用户询问Aryn.ai的模型是否优于Surya,认为Surya是目前最好的即用型解决方案。
- 反方观点:暂无明显反方观点,但有用户建议进行基准测试。
- 💡 数据安全与商业化
- 用户关注数据安全,询问技术是否可以商业化并在本地运行。
金句与有趣评论
- “😂 Is it better than Surya”
- 亮点:直接提出了技术比较的问题,简洁明了。
- “🤔 Do tables in PDFs always come as images, or does it happen that text is placed by coordinates on the page? Meaning do you really always need OCR?”
- 亮点:深入探讨了PDF表格的处理方式和OCR技术的必要性。
- “👀 Is this available commercially and can it run local? What are your plans from that prospective?”
- 亮点:关注技术的商业化前景和本地运行能力。
情感分析
讨论的总体情感倾向较为积极和探索性,用户对技术细节和实际应用表现出浓厚兴趣。主要分歧点在于技术比较和商业化前景,用户希望了解更多关于与其他解决方案的比较以及技术的商业化计划。
趋势与预测
- 新兴话题:技术比较和商业化前景可能会引发更多讨论。
- 潜在影响:该技术在金融文档处理领域的应用可能会对相关行业产生积极影响。
详细内容:
标题:探索PDF分割与提取的创新方法
在Reddit上,一篇关于PDF分割和提取新方法的帖子引起了广泛关注。该帖由ARYN.AI的团队分享,主要介绍了他们在可靠地从PDF中提取数据(如表格、图像、文本)方面所面临的挑战以及所训练的模型。此帖获得了众多点赞和大量评论。
帖子中展示了该模型在检测10-K财务报表中的各种组件、提取JP摩根10-K文档中的表格、检测特斯拉Powerwall PDF中的图像、标题和页脚等方面的成功案例。并且提到,提取出的信息可以在向量数据库中索引,用于RAG类型的工作流程。
在训练方法上,他们将PDF转换为图像,通过卷积骨干提取特征,再经过编码器/解码器的Transformer架构,输出边界框和标签,最后使用OCR检测文本。
讨论焦点主要集中在该模型与其他类似模型的比较、在PDF格式处理中的适用性以及商业应用的可能性等方面。
有用户表示“非常酷,感谢分享”,也有人询问是否比Surya更好,还有人对PDF中的表格呈现形式以及是否总是需要OCR提出疑问。另外,有人关心该技术是否可商业应用且能否在本地运行,以及与YOLO + DocLayNet的方法比较等。
例如,有用户分享道:“我在想像Florence 2这样的新模型是否会让这一过程更简单。鉴于PDF的布局多样性,我可以想象通过上下文示例,它们可以应用于更多文档类型。”
讨论中的共识在于大家对这一创新方法表现出了浓厚的兴趣,并期待其在实际应用中的效果。特别有见地的观点是关于不同模型在处理PDF时的优势和局限性的探讨,这丰富了对于该技术的全面理解。
总的来说,这一关于PDF分割与提取的讨论展示了技术创新的探索以及对于实际应用的思考,为相关领域的发展提供了有价值的参考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!