之前我一直为自己和一个LLM API服务工作,但由于我的想法和努力被忽视,我与该服务分道扬镳。现在,我正在为我的LLM推理API项目Arli AI制作模型。创建自己的模型只是个附加好处,哈哈。我在r/ArliAI上有更多详情。
ArliAI/Llama-3.1-8B-ArliAI-Formax-v1.0 · Hugging Face
ArliAI/Llama-3.1-8B-ArliAI-Formax-v1.0-GGUF · Hugging Face
ArliAI/Llama-3.1-8B-ArliAI-Indo-Formax-v1.0 · Hugging Face
ArliAI/Llama-3.1-8B-ArliAI-Indo-Formax-v1.0-GGUF · Hugging Face
为Arli AI创建的第一个新模型,我重用了之前用于创建ArliAI/ArliAI-Llama-3-8B-Formax-v1.0 · Hugging Face的相同数据集。
Llama 3.1 8B Formax
Formax数据集的目标是使模型更好地遵循系统提示中定义的输出格式指令。在Llama 3上,模型过于强调用户提示,经常忽视系统提示中的格式指令,因此Formax解决了这个问题,同时也改进了其指令遵循能力。在Llama 3.1上,它从一开始就明显更聪明,所以我认为即使是Meta的普通Instruct模型在遵循输出格式指令方面也已经做得很好。
你也可以在训练图中看到这一点,损失并没有真正下降很多,但它也没有波动或变得不稳定。这通常意味着模型已经很好地泛化,并且在正在训练的任务上表现良好。
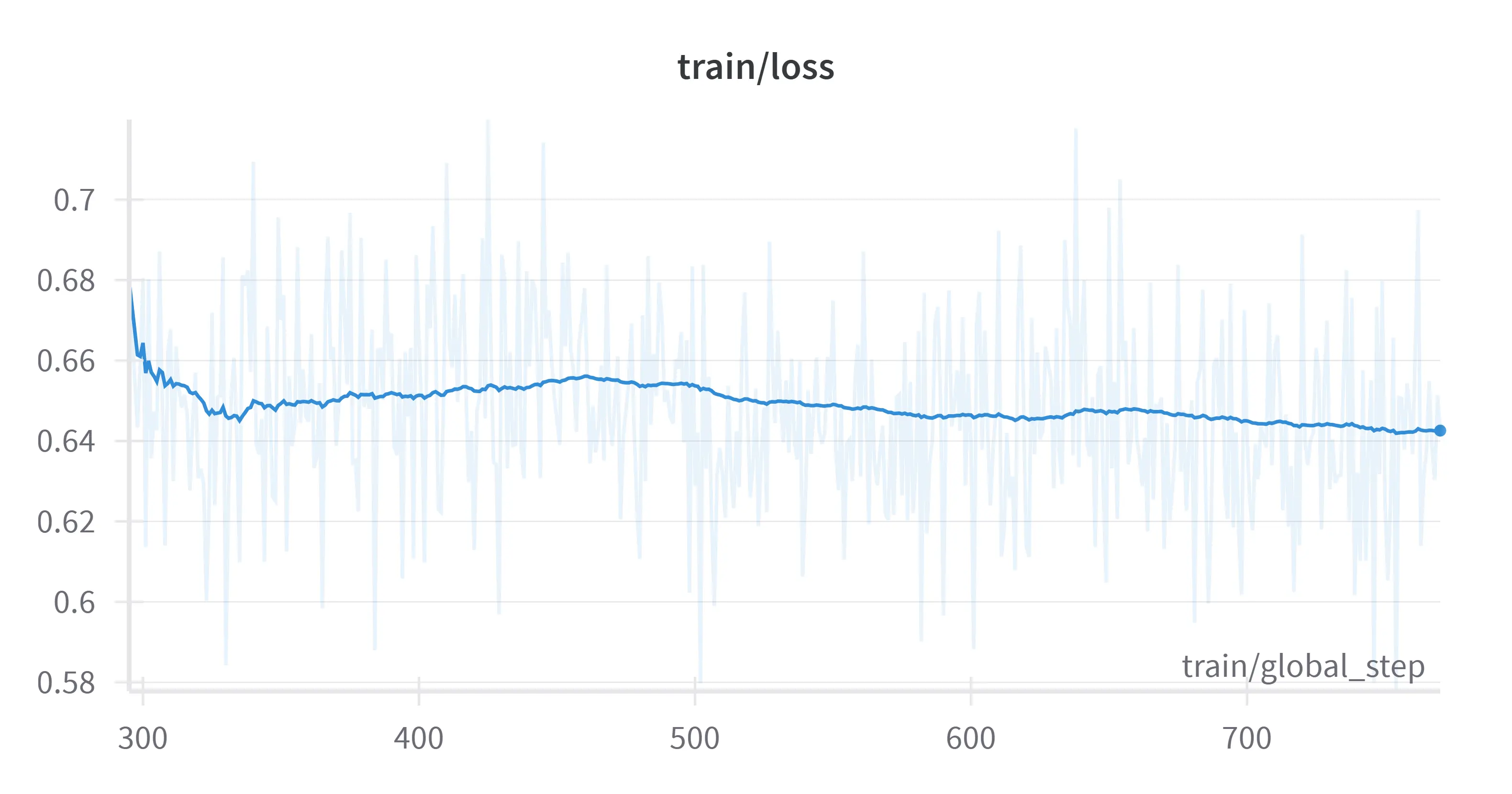
然而,由于Formax数据集也基于Eric Hartford的海豚数据集,除了由Llama 3.1 70B(以及我手动处理的部分)去掉了一些杂乱内容,Formax未经审查,愿意遵循任何用户请求。事实上,它比其他一些所谓的“未经审查”模型更少受到审查,响应也更少“警告”。所以我认为这是用Formax训练它的更大优势。
哦,另一个好处是,我现在至少在8K上下文上训练我的模型,因为你们中有一些人抱怨说,当我在4K上下文上训练时,性能在4K上下文以上会受到影响。
Llama 3.1 8B Indo-Formax
我的另一个目标是制作一个印尼语言版本,它能够很好地遵循指令,也能正确遵循格式。再次,在Llama 3.1上,即使是在普通的Instruct模型上,印尼语也已经相当不错了。但对我来说,经过Indo-Formax训练后,它仍然明显改善了。
对于Indo-Formax模型,我还继续用我从任何地方找到的高质量印尼语文本进行了0.5T令牌的预训练,这令人惊讶地甚至在Formax数据集训练部分之前就已经提高了指令性能。
Llama 3.1 8B Indo Formax v1.0训练损失
Llama 3.1 8B Indo Formax v1.0评估损失
预训练大致就是我划定的界限,正如你所见,模型已经在稳定地降低损失。即使在评估损失中,它使用的评估数据集仅来自Indo-Formax数据集。因此,即使没有在Indo-Formax风格的印尼语SFT数据集上训练模型,仅通过印尼语预训练就已经提高了性能。
对我来说,这意味着Llama 3.1 8B可以通过仅用大量该语言的完整文本进行预训练,轻松地在特定语言上得到改进。它不会扼杀指令性能,而是在你训练它的特定语言中提高它。
然而,通过用更多英语文本进行预训练以期望提高性能是行不通的,这里有一些当我尝试用大量英语维基百科进行预训练时的训练图。
这里我使用了Formax数据集作为评估数据集,你可以看到尽管训练损失稳定下降,但评估损失立即上升了很多。所以模型在生成维基百科文章方面变得更好,但在指令性能方面变得更差。我想这种与用印尼语预训练相比的行为差异可能是因为Meta已经在这个模型中填充了太多英语令牌,以至于用更多英语进行预训练已经没有意义了。
我希望r/LocalLLaMA能发现这个帖子有趣,如果有人想尝试训练特定语言,或者想尝试我的Arli AI LLM推理API项目,那就太好了:)
你可以在reddit上问我关于训练LLM的问题,或者通过[email protected],或者通过我的联系邮箱[email protected]关于Arli AI的问题。
讨论总结
本次讨论主要聚焦于作者nero10578如何通过预训练方法显著提升Llama 3.1模型在特定语言(尤其是印尼语)上的表现。作者分享了他们在创建和改进模型过程中的经验,包括使用高质量的印尼语文本数据和Formax数据集。此外,作者还介绍了他们的新项目Arli AI,一个LLM推理API,并邀请社区成员参与测试和反馈。讨论中还涉及了模型的训练技术、使用的硬件资源以及对模型性能的评估。
主要观点
- 👍 预训练可以显著提升特定语言的模型性能
- 支持理由:通过使用高质量的印尼语文本数据进行预训练,模型在特定语言任务上的表现得到了显著提升。
- 反对声音:预训练使用英语文本效果不佳。
- 🔥 Formax和Indo-Formax模型通过特定的数据集训练,能够更好地遵循输出格式指令
- 正方观点:这些模型在遵循系统提示中的格式指令方面表现出色。
- 反方观点:无明显反对意见。
- 💡 作者正在开发自己的LLM推理API项目Arli AI
- 解释:作者公开了相关模型的链接,并邀请社区成员参与测试和反馈。
金句与有趣评论
- “😂 nero10578:I will be uploading it in the ArliAI huggingface shortly.”
- 亮点:作者积极分享和更新他们的工作进展。
- “🤔 Bowler_No:Since you are using wiki scraped data the language are going to be so formal xD (am indonesian btw and might test this)”
- 亮点:用户对模型的语言风格提出有趣观察。
- “👀 Bowler_No:it did well in some eye test i done, stuff like recipe, answering question about province. but yeah cant code lol”
- 亮点:用户分享了模型在实际应用中的表现,特别是在编程任务上的不足。
情感分析
讨论的总体情感倾向积极,主要集中在对模型性能的提升和作者开放分享的态度上。争议点主要在于预训练数据的选择和模型在特定任务(如编程)上的表现。
趋势与预测
- 新兴话题:可能会有更多关于如何优化特定语言模型性能的讨论。
- 潜在影响:Arli AI项目可能会吸引更多开发者参与,推动LLM在多语言环境下的应用。
详细内容:
标题:Llama 3.1 的特定语言训练改进及热门讨论
最近,Reddit 上有一篇关于改进 Llama 3.1 在特定语言中 instruct 性能的帖子引起了广泛关注。这篇帖子获得了众多点赞和大量评论。
原帖作者介绍了自己为 Arli AI 创建新模型的经历,包括 Llama 3.1 8B Formax 和 Llama 3.1 8B Indo-Formax 模型,并分享了相关训练数据和成果。作者指出,Formax 数据集旨在改善模型遵循系统提示中的输出格式指令,而 Indo-Formax 模型则是为了提升印尼语的指令遵循能力。作者还提到,通过特定语言的预训练可以有效提升 Llama 3.1 8B 在该语言中的性能,同时不会损害 instruct 性能。
讨论焦点主要集中在以下几个方面:
- 关于数据集的获取,有用户询问数据集在哪里,作者回复将很快上传至 ArliAI huggingface。
- 有用户提到巴西葡萄牙语也需要这样的模型,并提供了相关语言的 LLM 排行榜链接。
- 有用户询问训练所使用的 GPU 以及训练时长,作者表示使用了 2x3090Ti 与 LORA,约 5 天完成一轮训练。
- 对于印尼语数据集的准备,作者使用了原始文本数据,并通过 Axolotl 进行处理,未对输入文本进行分块。
- 关于 0.5T 令牌数据集的整理,作者主要使用了维基百科和在 Hugging Face 上能找到的印尼语数据集。
- 有用户认为使用维基百科数据会使语言过于正式,作者表示也混入了印尼论坛和推特的内容。
- 经过测试,模型在一些方面表现良好,如食谱和回答有关省份的问题,但在编码方面有所不足。
在这场讨论中,我们看到了不同用户对于模型训练的关注和疑问,也看到了作者的分享和回应。这不仅丰富了我们对模型训练的认识,也为相关领域的探索提供了有价值的参考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!