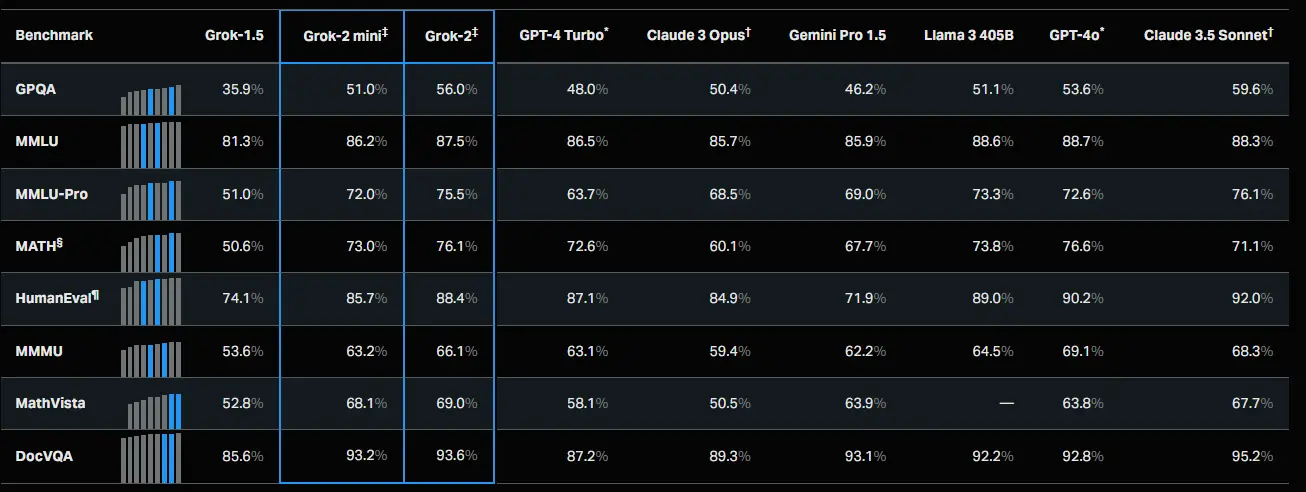
讨论总结
本次讨论主要围绕“Grok-2 and Grok-2 mini benchmark scores”这一帖子展开,帖子内容展示了一系列AI模型在多个基准测试中的性能指标。评论者们对各个模型在特定基准上的表现差异进行了深入讨论,特别是对Claude 3.5 Sonnet+模型在表格中的位置和性能表现持有不同看法。讨论中还涉及了对基准测试结果的怀疑、对模型参数规模的讨论、以及对开源问题的关注。整体氛围既有技术性的深入分析,也不乏幽默和讽刺的元素。
主要观点
- 👍 Claude 3.5 Sonnet+模型在表格中的位置引起了评论者的注意
- 支持理由:评论者对Sonnet+模型的性能表现持有不同看法,有人认为其表现不错。
- 反对声音:有人则认为其表现不佳,对其API价格和使用限制表示了关注。
- 🔥 Grok 2 Mini在所有主要基准测试中优于Claude 3 Opus和Gemini 1.5 Pro
- 正方观点:这种性能表现被评论者形容为“疯狂的”。
- 反方观点:无明显反对声音,多数评论者对此表示惊讶和赞叹。
- 💡 对x.AI的基准测试结果持怀疑态度
- 解释:评论者不仅因为这是x.AI的内容,而且对任何人挑选的基准测试结果都持怀疑态度。
- 👀 评论者对表格的展示方式感到困惑
- 解释:通常这种表格用于展示最佳得分,但实际得分未达到预期的高分,因此感到惊讶。
- 🚀 xAi正在快速发展
- 解释:评论者对xAi未来发展持乐观态度,认为xAi正在快速发展。
金句与有趣评论
- “😂 MandateOfHeavens:I like how Sonnet 3.5’s scores are all the way to the right.”
- 亮点:评论者对Sonnet+模型在表格中的位置表示了幽默和讽刺。
- “🤔 jpgirardi:Grok 2 Mini being better than Claude 3 Opus and Gemini 1.5 Pro in all of the main benchmarks is just madness!”
- 亮点:评论者对Grok 2 Mini的性能表现表示惊讶和赞叹。
- “👀 Downtown-Case-1755:And not just because it’s x.AI, I don’t trust cherry picked benchmarks from anyone lol.”
- 亮点:评论者对基准测试结果的怀疑态度。
- “😂 Puzzleheaded_Mall546:Claude 3.5 Sonnet is still in the top of the game in my use cases”
- 亮点:评论者对Claude 3.5 Sonnet在其特定应用中的优势表示认可。
- “🤔 Only-Letterhead-3411:Elon Musk keeps talking about how AI needs to be open source. So, where’s the weights?”
- 亮点:评论者对Elon Musk关于AI开源的言论表示质疑。
情感分析
讨论的总体情感倾向较为复杂,既有对模型性能的惊讶和赞叹,也有对基准测试结果的怀疑和幽默讽刺。主要分歧点在于对特定模型性能的评价和对开源问题的看法。可能的原因包括对技术细节的理解差异和对Elon Musk言论的不同解读。
趋势与预测
- 新兴话题:对模型参数规模的讨论和对开源问题的关注可能引发后续讨论。
- 潜在影响:对模型性能的深入讨论可能影响未来AI模型的开发方向和市场策略。
详细内容:
标题:关于模型性能基准得分的Reddit热门讨论
最近,Reddit上有一个关于不同模型性能基准得分的帖子引起了广泛关注。该帖子包含了一张表格,展示了如 Grok-1.5、Grok-2 mini+、GPT-4 Turbo+等众多模型在多个基准上的百分比得分,其链接为:https://i.redd.it/8ewcikif0qid1.png 。此帖获得了大量的点赞和众多评论,引发了对模型性能表现的热烈讨论。
讨论的焦点主要集中在以下几个方面:
- 对于 Sonnet 3.5 的位置和表现,看法不一。有人觉得它被放在角落是一种失败,会引起注意;有人则认为能被纳入就已经不错了。
- 关于 Grok-2 的表现,有人认为它在某些基准上超过了 Claude 3.5 Sonnet,而有人则认为这可能存在问题。
- 对于模型的参数和规模,大家也充满好奇,如 Grok mini 的参数估计以及 Grok 2 的大小等。
- 还有人对模型的开源、可用性、适用性以及是否存在作弊等问题进行了探讨。
有用户分享道:“作为一名长期关注模型发展的研究者,我发现这些基准得分并不能完全反映模型在实际应用中的表现。例如,某些模型在特定基准上得分高,但在实际场景中可能并不实用。” 还有用户提供了一个相关的分析链接:www.example.com/model-performance ,进一步支持了这一观点。
在争议点方面,有人对基准测试的公正性表示怀疑,认为可能存在作弊行为;也有人对某些模型的宣传和实际表现之间的差距提出了质疑。
不过,讨论中也有一些共识。大家普遍认为,这些数据有助于了解各个模型的优缺点和适用范围。
特别有见地的观点是,有人指出不能仅仅依据基准得分来评价模型,还需要考虑实际应用中的多种因素。这一观点丰富了讨论,提醒大家要全面、客观地看待模型的性能。
总的来说,这次Reddit上的讨论让我们对不同模型的性能有了更深入的了解,也促使我们更加审慎地看待模型评估的结果。


感谢您的耐心阅读!来选个表情,或者留个评论吧!