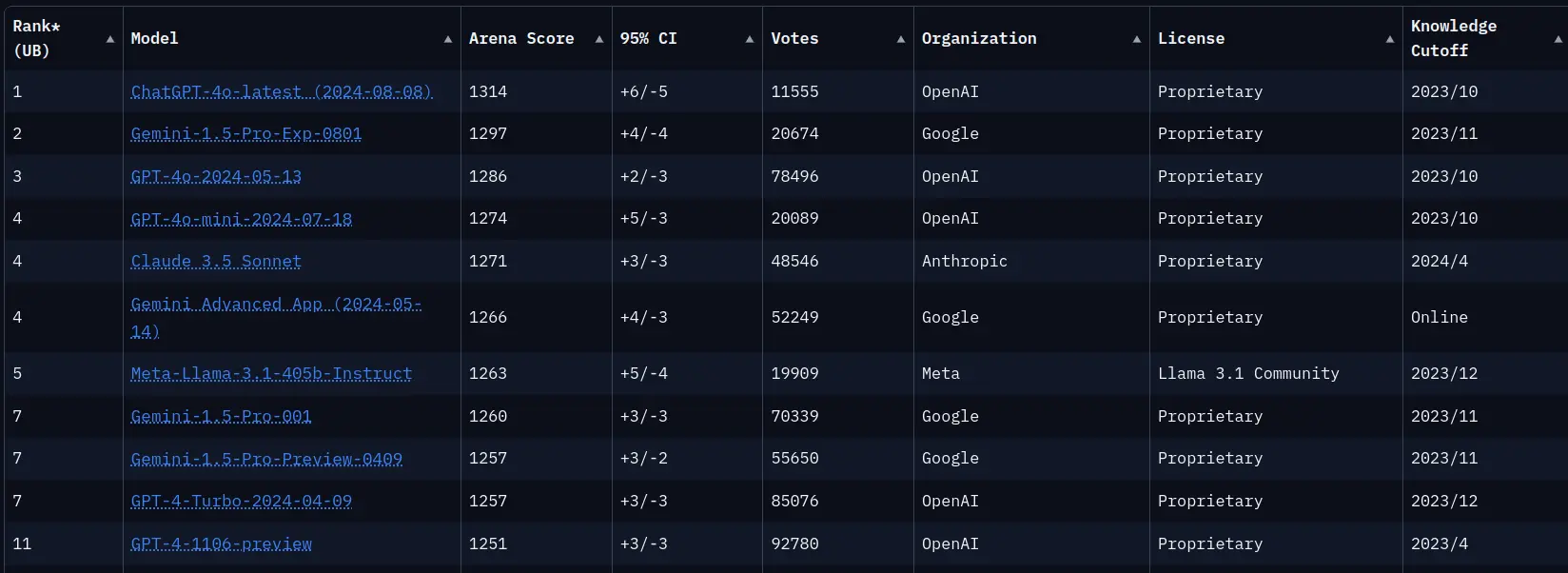
这是lmsys目前的排行榜
我尝试了Claude Sonnet 3.5和GPT-4o最新版本,我无法看出它比之前的版本更好(我至今仍在日常使用Sonnet 3.5)。
我使用该模型进行头脑风暴和编程任务(不涉及角色扮演或数学问题)。是我的判断有误,还是其他人也有同样的经历?
讨论总结
本次讨论主要围绕lmsys arena排行榜的公正性展开,涉及多个模型的性能比较和适用性讨论。评论者普遍质疑排行榜的客观性和公正性,认为可能受到人类偏好和平台偏好的影响。讨论中涉及的主要观点包括使用特定于个人使用场景的基准来评估模型性能、Claude模型在指令遵循和代码编写任务中的优越性、云服务提供商提供多种模型版本的原因、以及某些用户偏爱旧模型的原因。此外,还有评论者建议使用arena battle模式亲自体验模型表现,以确保评估的客观性。总体上,讨论呈现出对排行榜机制的质疑和对模型实际应用性能的关注。
主要观点
- 👍 使用特定于个人使用场景的基准来评估模型性能
- 支持理由:更合理地反映模型在实际任务中的表现。
- 反对声音:可能缺乏普遍性和客观性。
- 🔥 Claude模型在指令遵循和代码编写任务中表现优越
- 正方观点:在特定任务中,Claude模型的性能明显优于其他模型。
- 反方观点:可能存在特定任务的局限性。
- 💡 云服务提供商提供多种模型版本是因为不同模型可能在特定任务上表现更佳
- 解释:满足不同用户的需求和偏好。
- 👀 某些用户可能因为旧模型在特定任务上的表现而偏爱它们
- 解释:旧模型在某些任务上的稳定性和性能得到用户认可。
- 🚀 建议使用arena battle模式亲自体验模型表现
- 解释:确保评估的客观性和带来惊喜。
金句与有趣评论
- “😂 AdHominemMeansULost:you should use a benchmarks thats specific to your use case, if you want instruction following and code this is good and you can see how superior Claude is clear as day”
- 亮点:强调特定任务基准的重要性。
- “🤔 Alive_Panic4461:It’s not rigged, it just shows that human preference is often flawed, especially in such arenas that incentivize shorter prompts and quick comparisons.”
- 亮点:指出人类偏好在评估中的局限性。
- “👀 e79683074:Try using the arena battle mode yourself. It’s blind, you get shown answers side by side and you have to choose what’s the best answer to you.”
- 亮点:建议通过实际体验来评估模型。
情感分析
讨论的总体情感倾向为质疑和不满,主要分歧点在于排行榜的公正性和模型在实际应用中的表现。评论者普遍认为排行榜可能受到人类偏好和平台偏好的影响,导致模型性能的评估不够客观。此外,也有评论者对特定模型的实际表现提出质疑,认为排行榜未能真实反映模型的性能。
趋势与预测
- 新兴话题:对排行榜机制的改进和更客观的评估方法的探讨。
- 潜在影响:改进排行榜机制可能提高用户对模型性能评估的信任度,进而影响模型选择和应用。
详细内容:
标题:关于 lmsys arena 排行榜公正性的热门讨论
在 Reddit 上,有一篇题为“我认为 lmsys arena 排行榜不知怎的被操纵了”的帖子引发了广泛关注。该帖子展示了 lmsys arena 的当前排行榜图片,列出了不同模型的详细信息。发帖者表示尝试了 Claude Sonnet 3.5 和 GPT-4o 最新版,却不觉得后者更好,还称自己目前仍日常使用 Sonnet 3.5,并询问是否有其他人有相同经历。此帖获得了众多点赞和大量评论,主要讨论方向集中在不同模型的性能比较、排行榜的公正性以及使用体验等方面。
讨论焦点与观点分析: 有人认为应根据具体使用场景选择基准测试,以明确 Claude 的优势,比如“你应该使用针对您使用案例的基准测试,如果您想要指令跟随和编码,这很好,您可以清晰地看到 Claude 有多优越”,并提供了相关链接:https://aider.chat/docs/leaderboards/ 。 有人对云提供商众多的模型版本表示疑惑,比如“我完全本地化,对云提供商一无所知。为什么云提供商会有这么多模型版本?所有这些模型都能通过 API 使用并且我们可以从中选择任何一个吗?”得到了肯定的回复。 有人提出不同看法,认为旧模型在某些方面可能更好,比如“因为较旧的模型可能在某些事情上表现更好。您仍然有人们对较旧的 GPT 模型/版本坚信不疑。” 还有人指出,最终升级的模型并非在所有方面都是升级。如果流程与特定模型的提示微调后效果良好,而在新变体上效果不佳,就会欣赏旧模型的保留以便重新调整。 有人认为排行榜没有被操纵,只是人类偏好往往有缺陷,而且 OpenAI 基于 lmsys 偏好进行了数月的微调,比如“它没有被操纵,只是表明人类偏好往往是有缺陷的,特别是在这样激励更短提示和快速比较的领域。并且 OpenAI 已经根据 lmsys 偏好进行了数月的微调,这就是为什么 4o 如此喜欢使用 Markdown,而 3.5 Sonnet 默认使用纯文本。而且 OpenAI 模型的过滤较少。当然,实际上 3.5 Sonnet 是目前最好的全能模型。” 有人认为 Gradio 影响了 Chatbot Arena,加载时间过长,若切换到更快的前端,会使排行榜更能代表现实世界的使用情况。 有人认为 1 对 1 比较难以比较长对话,应实现不同提示和撤销功能。 有人表示不确定竞技场部分的微调,认为 3.5 Sonnet 是目前最好的全能模型。 有人分享了自己的使用经历,比如“我给 Claude 一个提示来更新某些函数并保持另一个函数的结构,它失败了,新的 ChatGPT 也失败了。然后我为两者更新了提示,Sonnet 一次就做对了,但 ChatGPT 尝试了 4 次。” 有人认为新的 4o 在冗长编码方面更好。 有人指出存在审查问题。 有人认为任何成为目标的基准都不再是好的基准。
总之,对于 lmsys arena 排行榜和不同模型的性能,大家观点各异,但都从自身的使用体验和了解的情况出发,丰富了讨论。


感谢您的耐心阅读!来选个表情,或者留个评论吧!