讨论总结
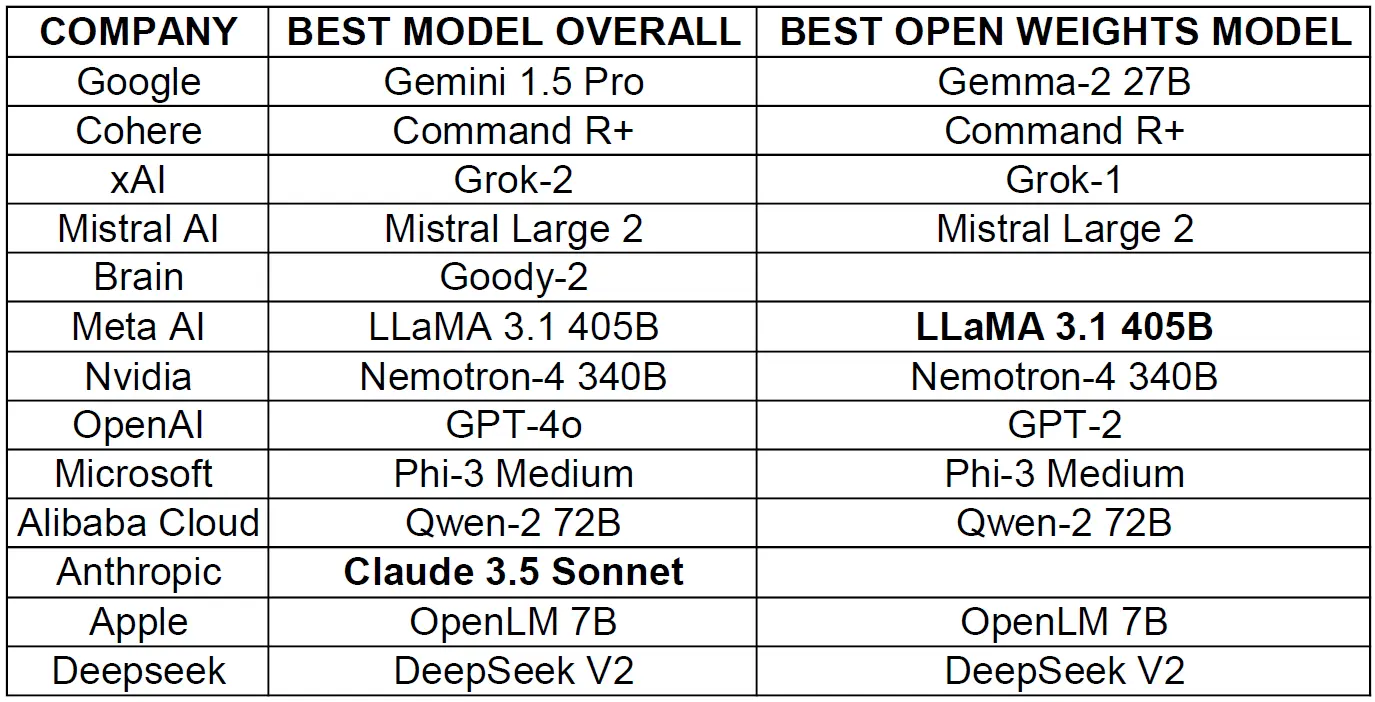
本次讨论主要围绕一张列出不同公司及其最佳模型的表格展开,涉及模型的性能、开源性、安全性及硬件需求等多个方面。讨论中,用户们对OpenAI的GPT-2模型表示了认可,并讨论了Sam Altman推广的眼球扫描技术。此外,还有关于Gemma-2 27b模型的性能和适用性、Anthropic公司的模型策略、LLaMA 3.1 405B模型的使用成本和性能等话题。整体上,讨论涵盖了模型选择、显存限制、技术实现和安全性等多个关键话题,反映了用户对AI模型性能和应用的深入关注。
主要观点
- 👍 OpenAI的GPT-2模型表现良好
- 支持理由:用户对GPT-2表示了幽默的认可,认为其性能可靠。
- 反对声音:无明显反对声音,多数用户持认可态度。
- 🔥 Gemma-2 27b模型因其能够在24GB显存上运行而受到推崇
- 正方观点:Gemma-2 27b在某些情况下表现出色,是用户的首选模型。
- 反方观点:有用户指出Gemma-2 27b在上下文大小方面可能存在挑战。
- 💡 Anthropic公司通过发布关于模型潜在恶意的研究来为其封闭权重模型辩护
- 解释:评论者认为开放源代码项目由于广泛的审查和多样化的参与者,可以提高模型的安全性和安全性。
- 🌟 Mistral Large 2是目前100b级别的冠军模型
- 解释:评论者认为Mistral Large 2具有131k的上下文长度和高度智能,已经进行了Lumimaid和Tess的微调。
- 🚀 结合几个开源模型可以超越GPT-4o和Sonnet 3.5
- 解释:评论者推荐尝试Groq-moa,并指出在推荐设置下,该模型在逻辑推理方面几乎能击败所有其他模型。
金句与有趣评论
- “😂 Lol at GPT-2, nice. It’s true.”
- 亮点:用户对GPT-2的幽默认可,展现了模型的受欢迎程度。
- “🤔 If you enjoyed using GPT-2, please make sure you get your eyeball scanned by Sam Altman.”
- 亮点:幽默地提及Sam Altman的眼球扫描技术,增加了讨论的趣味性。
- “👀 WizardLM2 is not better than Phi-3?”
- 亮点:对WizardLM2和Phi-3的比较,引发了对模型性能的深入讨论。
情感分析
讨论的总体情感倾向较为积极,多数用户对模型的性能和应用表示认可。然而,也存在一些争议点,如Anthropic公司的模型策略和眼球扫描技术的安全性。这些争议主要源于对模型开放性和个人隐私保护的担忧。
趋势与预测
- 新兴话题:模型大小和性能的平衡,以及开源模型的安全性。
- 潜在影响:对AI模型的发展和应用产生深远影响,特别是在模型选择和安全性方面。
详细内容:
标题:Reddit 上关于公司最佳模型的热门讨论
近日,Reddit 上有一个关于不同公司所使用的最佳模型的热门帖子引发了广泛关注。该帖子以一张详细的表格展示了各公司的最佳整体模型和最佳公开权重模型,包括 Google、Cohere、xAI 等众多知名公司。此帖获得了大量的点赞和众多评论。
讨论的焦点主要集中在不同模型的性能、适用性以及开源情况等方面。有人认为 Gemma-2 27b 非常出色,也有人指出某些模型在特定情况下仍存在问题。比如,有用户提到“我仍然在前三小模型(L3.1、Nemo、Gemma2)之间切换,真希望能最终确定一个默认模型。”
对于开源问题,观点各异。有用户称“我喜欢这样,当一个开源项目被世界各地成千上万不同背景的人关注时,它可以并且已经在安全性和安全性方面带来了更好的结果。他们说他们关注安全,但完全忽视了开放权重/开源模型在提高安全性方面可能带来的机会?”
在模型的选择和使用方面,一些用户分享了自己的经验。比如,“你可以在谷歌云中免费获得 llama3.1,但说实话,它并不是那么好。你必须非常小心地提示它才能获得最佳结果。” 还有用户讨论了模型运行的硬件和成本问题,“要运行 LLAMA 3.1 405B 以 FP16 运行,得花 65000 美元买 5 个 MI300X(或 3 个 MI325X)。”
同时,也有用户对某些模型的表现感到困惑,不知道该如何选择。
总的来说,这次关于公司最佳模型的讨论展现了大家对人工智能模型的高度关注和深入思考,同时也反映出在选择和使用模型时所面临的各种挑战和困惑。未来,随着技术的不断发展,相信这些问题会逐渐得到解决。


感谢您的耐心阅读!来选个表情,或者留个评论吧!