大家好,
引用我之前帖子中的内容:
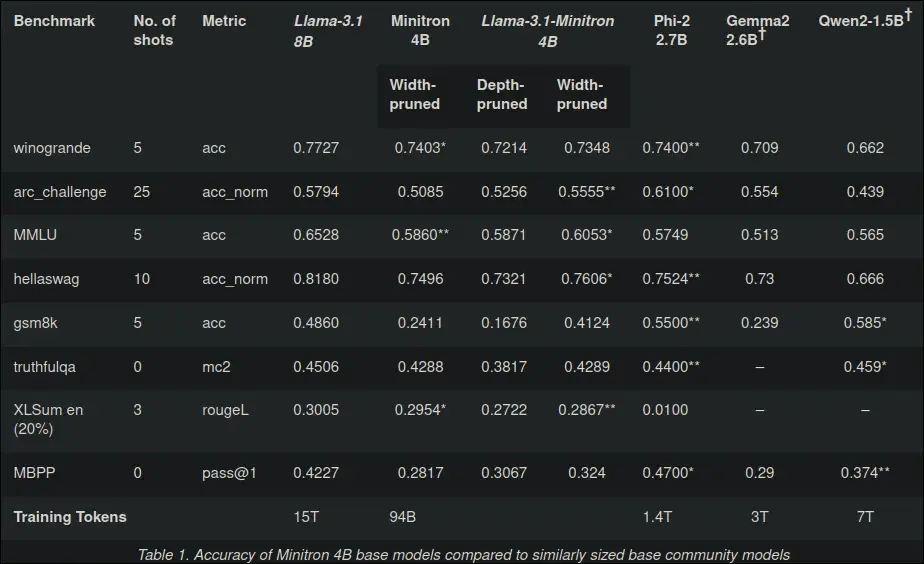
Nvidia研究团队开发了一种方法,可以将大型语言模型(LLMs)提炼/剪枝成更小的模型,同时性能损失最小。他们尝试在Llama 3.1 8B上应用这种方法,以创建一个4B模型,这无疑将是该尺寸范围内最好的模型。研究团队正在等待公开发布的批准。
他们做到了!这里是HF仓库链接:https://huggingface.co/nvidia/Llama-3.1-Minitron-4B-Width-Base
技术博客:https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model/
GGUF, Q8_0:https://huggingface.co/NikolayKozloff/Llama-3.1-Minitron-4B-Width-Base-Q8_0-GGUF
GGUF, 所有其他量化(目前正在量化…):https://huggingface.co/ThomasBaruzier/Llama-3.1-Minitron-4B-Width-Base-GGUF
编辑:您需要最新版本的llama.cpp来在GGUF中运行它,因为模型架构昨天才合并。
讨论总结
Reddit社区对Nvidia发布的Llama-3.1-Minitron-4B-Width-Base模型表现出浓厚兴趣,讨论主要集中在模型的性能、应用潜力以及与其他开源模型的比较。用户们探讨了模型精简技术如何帮助在不同硬件配置上运行,特别是对手机、Raspberry Pi和小型服务器的适应性。此外,量化技术、模型兼容性和潜在的崩溃问题也是讨论的热点。整体上,讨论氛围积极,用户们对新模型的发布表示期待,并提出了许多有见地的观点和建议。
主要观点
- 👍 Nvidia成功将Llama 3.1 8B模型精简为4B模型,性能损失极小。
- 支持理由:用户认为这种精简技术有助于在资源受限的设备上运行大型模型。
- 反对声音:有用户担心精简可能导致某些功能的损失。
- 🔥 用户希望类似技术能应用于70B模型,以适应24GB VRAM的硬件。
- 正方观点:这种技术的应用可以大幅降低硬件需求,使更多用户能够使用高性能模型。
- 反方观点:有人担心大规模模型的精简可能会牺牲太多性能。
- 💡 有用户建议将模型进一步精简至30B,以减轻硬件负担。
- 解释:这种建议反映了用户对更高效、更轻量级模型的需求。
- 👍 讨论了不同量化级别(如2.5bpw和4.0-5.0bpw)对模型性能的影响。
- 支持理由:量化技术是减少模型大小和提高性能的有效方法。
- 反对声音:低于Q4_K_M的量化可能导致性能显著下降。
- 🔥 用户对更大规模模型(如405B)的精简表示期待。
- 正方观点:精简技术可以使这些大型模型在更多设备上运行。
- 反方观点:精简过程可能会引入新的技术挑战和性能问题。
金句与有趣评论
- “😂 I hope they do that to the 70B model too.”
- 亮点:反映了用户对更大规模模型精简的期待和幽默感。
- “🤔 Is this better than Gemma 2 2B?”
- 亮点:提出了一个关键的比较问题,引发了对新模型性能的深入讨论。
- “👀 Waiting for the day when LLMs with good quality output will be able to run on normal Laptops with 8GM ram & i3 processor (poor man’s laptop)”
- 亮点:表达了用户对未来技术普及化的乐观态度和期待。
情感分析
讨论的总体情感倾向是积极的,用户们对新模型的发布表示兴奋和期待。主要分歧点在于模型的性能和兼容性问题,部分用户担心精简可能导致性能下降或兼容性问题。这些分歧主要源于对新技术的不确定性和对现有解决方案的依赖。
趋势与预测
- 新兴话题:模型精简技术和量化方法可能会引发更多关于如何在不同设备上优化和运行大型模型的讨论。
- 潜在影响:新模型的发布可能会推动更多研究和开发,特别是在移动设备和边缘计算领域。
详细内容:
标题:Nvidia 发布 Llama-3.1-Minitron-4B-Width-Base 模型,引发 Reddit 热烈讨论
近日,Reddit 上一则关于 Nvidia 发布 Llama-3.1-Minitron-4B-Width-Base 模型的帖子引发了广泛关注,获得了众多点赞和大量评论。帖子介绍了该模型,并提供了相关的技术博客、模型链接等丰富信息。
讨论的焦点主要集中在该模型与其他模型的性能比较、适用场景以及优化改进等方面。有人希望能对 70B 模型也进行类似处理,以在较小的硬件上运行。还有人关心模型的量化版本在性能和速度上的表现,比如探讨 4B 8bit 是否优于 8B 4bit 等。
有用户表示,Gemma 2 2B 在某些方面表现出色,仍能坚守自己的地位。也有人提出疑问,比如该模型与 AQLM 相比有何不同,是否比 Gemma 2 2B 更好,以及能否在特定软件中运行等。
有人认为,对于手机、RPIs 和小型服务器而言,该模型的出现非常酷。但也有人质疑,2-5 个百分点的性能提升是否值得模型尺寸的减小。不过,也有人指出量化仍是减小模型尺寸、提高性能和解决 VRAM 限制的最佳方式。
特别有用户提到,自己在手机上对小型模型的微调取得了一定成功,期待 Llama-3.1 4b minitron 能成为移动设备上高质量、可微调的基础模型新冠军。
总之,关于 Nvidia 发布的这个新模型,Reddit 上的讨论呈现出多样性和复杂性,大家从不同角度探讨了其潜在的价值、局限性以及未来的应用前景。


感谢您的耐心阅读!来选个表情,或者留个评论吧!