嘿 r/LocalLLaMA! 微软今天发布了 Phi-3.5 mini,具有 128K 上下文,是从 GPT4 蒸馏而来,并在 3.4 万亿个令牌上进行了训练。我上传了 4bit bitsandbytes quants,并在 Unsloth https://github.com/unslothai/unsloth 上提供了 2倍更快的微调 + 50% 更少的内存使用。
由于 Phi-3 将 QKV 合并为一个矩阵,门和上合并为一个,这影响了微调的准确性,因为 LoRA 将为 Q、K 和 V 训练一个 A 矩阵,而我们需要 3 个独立的矩阵来提高准确性,所以我不得不 ‘Llama-fy’ 模型以提高微调的准确性。下图显示了训练损失 - 蓝线总是低于或等于原始融合模型的微调损失:
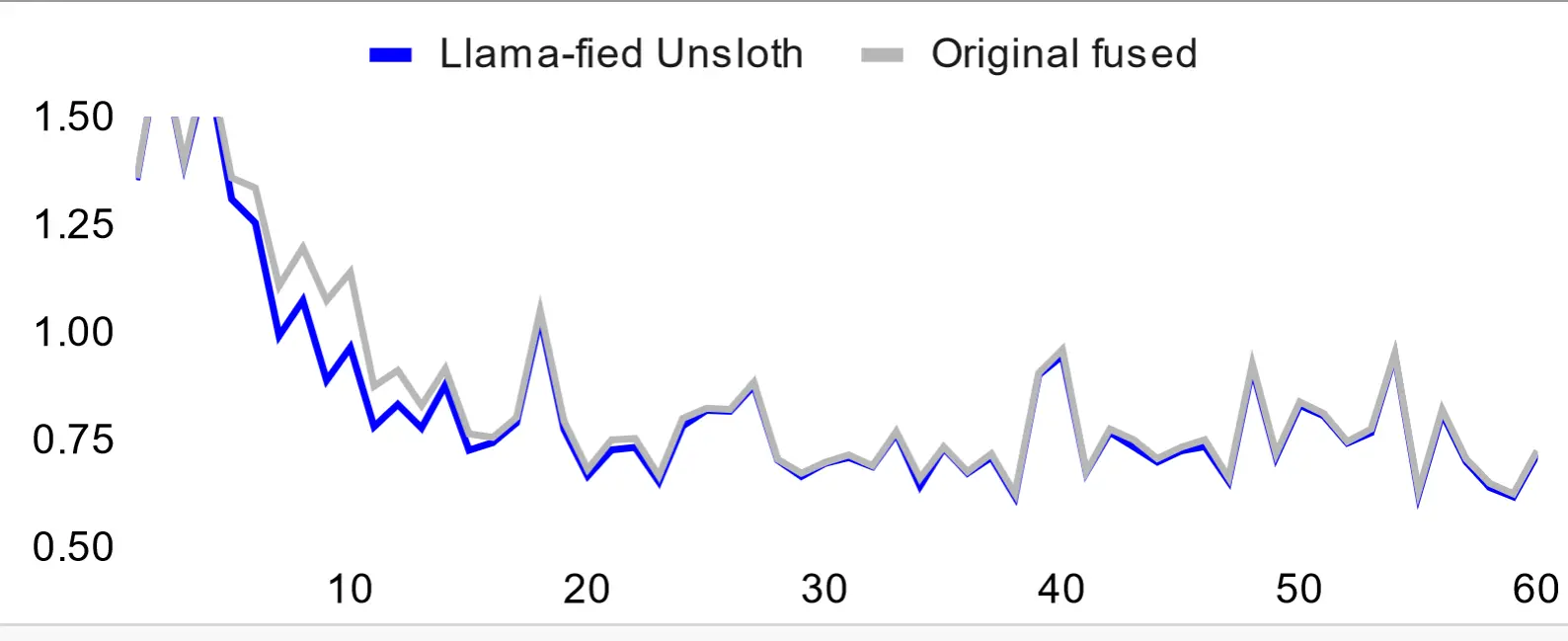
这里是 Unsloth 的免费 Colab 笔记本,用于微调 Phi-3.5 (mini):https://colab.research.google.com/drive/1lN6hPQveB_mHSnTOYifygFcrO8C1bxq4?usp=sharing。
Kaggle 和其他 Colabs 在 https://github.com/unslothai/unsloth
Llamified Phi-3.5 (mini) 模型上传:
https://huggingface.co/unsloth/Phi-3.5-mini-instruct
https://huggingface.co/unsloth/Phi-3.5-mini-instruct-bnb-4bit。
其他更新方面,Unsloth 现在支持 Torch 2.4、Python 3.12、所有 TRL 版本和所有 Xformers 版本!我们还添加和修复了许多问题!请通过以下方式更新 Unsloth:
pip uninstall unsloth -y
pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
讨论总结
本次讨论主要围绕微软发布的Phi-3.5模型及其在Unsloth平台上的应用展开。帖子内容详细介绍了Phi-3.5模型的特性,包括其从GPT4中提炼出来,具有128K上下文,并进行了3.4万亿个令牌的训练。此外,作者还提到了通过“Llama-fy”处理来提高微调的准确性,并提供了相关的GitHub链接和Colab笔记本。评论中,社区成员对模型的改进表示赞赏,并就模型的性能、微调支持、用户体验等方面进行了深入讨论。整体氛围积极,社区成员间的互动和支持体现了良好的社区精神。
主要观点
- 👍 Phi-3.5模型的改进
- 支持理由:模型从GPT4中提炼,具有128K上下文,经过3.4万亿个令牌的训练,提供了2倍更快的微调和50%更少的内存使用。
- 反对声音:无明显反对声音,社区普遍表示赞赏。
- 🔥 “Llama-fy”处理的重要性
- 正方观点:通过“Llama-fy”处理,可以提高微调的准确性,并减少VRAM使用。
- 反方观点:无明显反方观点,社区普遍认同这一改进。
- 💡 社区互动和支持
- 解释:社区成员对作者的工作表示赞赏,并积极互动,如自动点赞和感谢回应,体现了社区的积极氛围。
- 👀 模型性能和用户体验
- 解释:讨论了模型在不同硬件上的性能表现,以及用户体验的改进,如期待更多优化的版本和更好的微调支持。
- 🤔 技术好奇和未来展望
- 解释:社区成员对模型的技术细节表示好奇,并探讨了模型的未来发展,如是否可以合并不同模型的知识。
金句与有趣评论
- “😂 I see /u/danielhanchen post, I instantly upvote.”
- 亮点:体现了社区成员对作者工作的认可和赞赏。
- “🤔 Thanks for all of your work. I’ve been trying to evangelize everyone at my work to join the church of unsloth.”
- 亮点:表达了用户对Unsloth平台的推广和期待。
- “👀 We’re like bloody seagulls on the beach, to a handful of potato chips. 🍟”
- 亮点:幽默地表达了社区成员对新技术的渴望。
- “😂 Daniel is GOAT”
- 亮点:社区成员对作者的高度评价。
- “🤔 Are you just trying to match the parameters of the original model and transfer the weights?”
- 亮点:社区成员对模型转换技术的好奇和探讨。
情感分析
讨论的总体情感倾向积极,社区成员对Phi-3.5模型的改进和Unsloth平台的支持表示赞赏。主要分歧点在于模型的性能对比和用户体验的改进,但这些讨论都是建设性的,旨在推动技术的进步和社区的发展。
趋势与预测
- 新兴话题:模型性能的进一步优化和用户体验的提升。
- 潜在影响:Phi-3.5模型的改进和Unsloth平台的支持将进一步推动AI技术的发展,特别是在微调和内存优化方面。
详细内容:
标题:Phi 3.5 模型的优化与创新引发Reddit热议
在Reddit的r/LocalLLaMA版块,一篇关于Phi 3.5模型的帖子引起了广泛关注。该帖子介绍了微软新发布的Phi-3.5 mini,它具有128K的上下文,由GPT4提炼并在3.4万亿个令牌上进行训练。作者还提到已将其进行4bit bitsandbytes量化,并通过Unsloth使其能够实现2倍更快的微调以及节省50%的内存使用。为了提高微调的准确性,作者对模型进行了“Llama-fy”处理。帖子中提供了相关的图片、链接和多个模型的上传地址,还提到了Unsloth对Torch 2.4、Python 3.12等的支持以及更新方式。此帖获得了众多点赞和大量评论。
在评论区,主要的讨论焦点和观点包括:
- 有人表达了对作者工作的感谢和支持,比如[lumierenoir]称一直在向同事宣传Unsloth,并期待用新的Phi模型进行微调,特别是实现函数调用功能。
- 关于GGUFs和ARM优化的问题,有人提到当前的GGUFs在某些前端可直接使用,还有人期待作者上传相关内容。
- 对于Unsloth是否支持VLM的微调,有人表示目前不支持但正在开发中。
- 关于“蒸馏”的定义和Phi 3.5模型是否属于真正的蒸馏存在争议,有人认为其只是在合成数据集上进行训练。
- 对于为何要对Phi进行“Llama-fy”处理,作者解释称Phi 3.5将QKV融合在一个矩阵中,这会限制LoRA微调的自由度和准确性,分离后能提高微调的准确性并减少VRAM的使用。有人对这一解释表示虽然不完全理解但有帮助。
- 关于Phi 3.5与其他模型的比较,有人认为llama 3.1更好,也有人表示根据微软的研究Phi 3.5在很多基准测试中表现更优。
总的来说,这次关于Phi 3.5模型的讨论展现了大家对新技术的热情和深入思考,也反映了在模型优化和应用方面的多种观点和期待。


感谢您的耐心阅读!来选个表情,或者留个评论吧!