讨论总结
本次讨论主要围绕“平坦的0训练损失”是否意味着模型过拟合展开。评论者普遍认为,即使模型过拟合,损失通常也不会降到0,这可能表明训练过程中存在问题。讨论还涉及学习率设置、模型输出检查及损失计算的合理性,以及模型是否学习到奇怪的重复词汇。总体上,讨论呈现出对模型性能和训练过程的深入分析和质疑。
主要观点
- 👍 即使模型过拟合,损失通常不会降到0。
- 支持理由:这可能意味着训练过程中存在问题。
- 反对声音:无
- 🔥 训练损失为0并不一定意味着模型表现良好。
- 正方观点:需要检查模型的输出是否符合预期。
- 反方观点:模型有时会学习到奇怪的重复词汇,导致损失下降。
- 💡 训练损失为0通常不理想,因为模型可能失去了创造性。
- 解释:模型预测的概率分布必须与目标概率分布完全一致,这通常是一个尖峰分布。
- 💡 学习率乘数(LR multiplier)可能过高。
- 解释:高学习率可能导致训练损失为零。
- 💡 0损失通常对SFT微调不利,但对DPO偏好优化是可以接受的。
- 解释:询问发帖者进行的具体微调类型。
金句与有趣评论
- “😂 Even when overfitted the loss generally never goes to 0.”
- 亮点:指出了过拟合情况下损失通常不会降到0的现象。
- “🤔 It might not be, you should check if the outputs are as expected.”
- 亮点:强调了检查模型输出是否符合预期的重要性。
- “👀 Usually not, as the model should lose all creativity to reach zero loss, since the probability distribution it predicts must be equal to the target probability distribution, which is a delta distribution.”
- 亮点:深入分析了训练损失为0对模型创造性的影响。
情感分析
讨论的总体情感倾向较为谨慎和质疑,主要分歧点在于训练损失为0是否意味着模型过拟合。评论者普遍认为这可能是一个问题,并提出了多种可能的原因,如学习率设置不当、模型输出异常等。
趋势与预测
- 新兴话题:学习率设置对模型训练的影响。
- 潜在影响:对模型微调过程中的参数设置和结果评估有更深入的认识和理解。
详细内容:
标题:关于训练损失为 0 是否良好的热门讨论
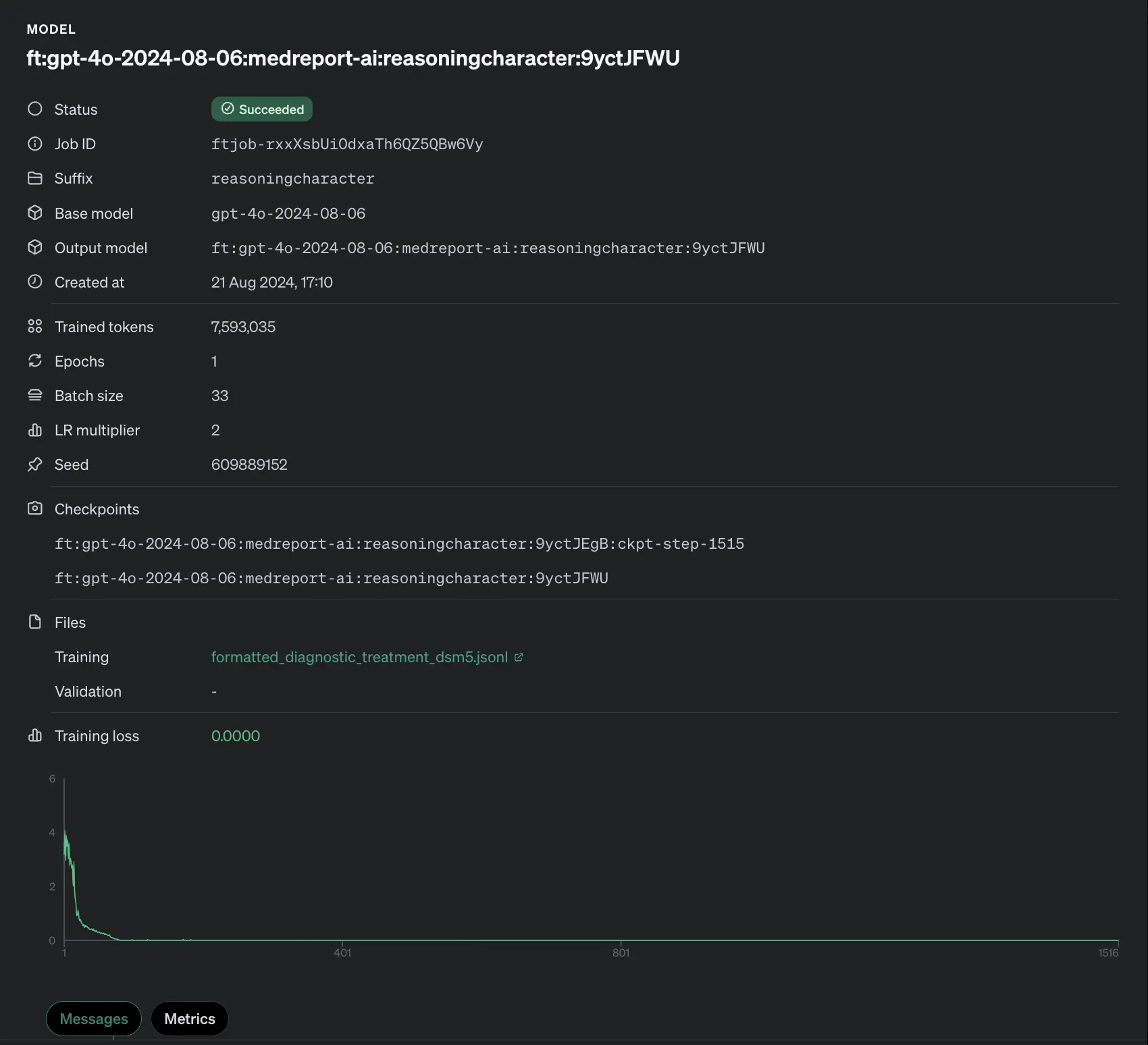
在 Reddit 上,一则关于“Is a flat 0 training loss good? (My second attempt at fine-tuning)”的帖子引起了广泛关注。该帖展示了一张有关“ft:gpt-4o-2024-08-06:medreport-ai:reasoningcharacter:9yctJFWU”详细信息的图片,包括状态、作业 ID 等多项内容。特别值得注意的是,此模型的训练和验证损失均为 0.0000,帖子中的图片还呈现了训练损失的变化情况,图片链接为:https://i.redd.it/1b9rx0qpg6kd1.png 。这一话题引发了大量的讨论。
讨论焦点主要集中在训练损失为 0 是否意味着模型良好。有人指出,即便过度拟合,损失通常也不会到 0,可能存在训练过程的问题。有人认为应该检查输出是否符合预期,有时模型会学习到奇怪的“魔法词汇”并不断重复,导致损失持续下降。还有人表示,通常情况下,训练损失为 0 并非好事,因为这意味着模型失去了所有创造力,其预测的概率分布必须与目标概率分布完全相同,这是一种增量分布。也有人提到,如果模型完全过度拟合到训练数据,实际上是记住了所有数据。我们在句子中添加单词是为了增加信息,所以预测下一个单词应该是有损失的。要让语言模型能够“思考”训练数据之外的内容,就要确保其接受足够的数据训练,使其无法单纯记忆,而是要实施某种通用的演绎过程来更准确地猜测下一个单词。
有人觉得这个学习率乘数看起来非常高,可能导致了这种情况。还有人认为 0 损失通常意味着过度拟合。有人提出自己从未对 OpenAI 模型进行过微调,但一般来说 0 损失对于 SFT 微调不好,对于 DPO 偏好优化则可以。另外,有人指出你的学习率比正常应该的高了约 5 - 6 个数量级,存在过度拟合的情况。通常学习率更接近 2e-4 到 2e-6 。
在这场讨论中,大家的共识是训练损失为 0 往往不是一个好的现象,很可能意味着过度拟合。而不同的观点主要在于对造成这一现象的具体原因的分析和判断。特别有见地的观点是从模型的创造力、概率分布以及学习率等多个角度进行深入剖析,丰富了对于这一问题的讨论。
综上所述,关于训练损失为 0 是否良好的讨论揭示了模型微调中的复杂问题,也为相关研究和实践提供了多角度的思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!