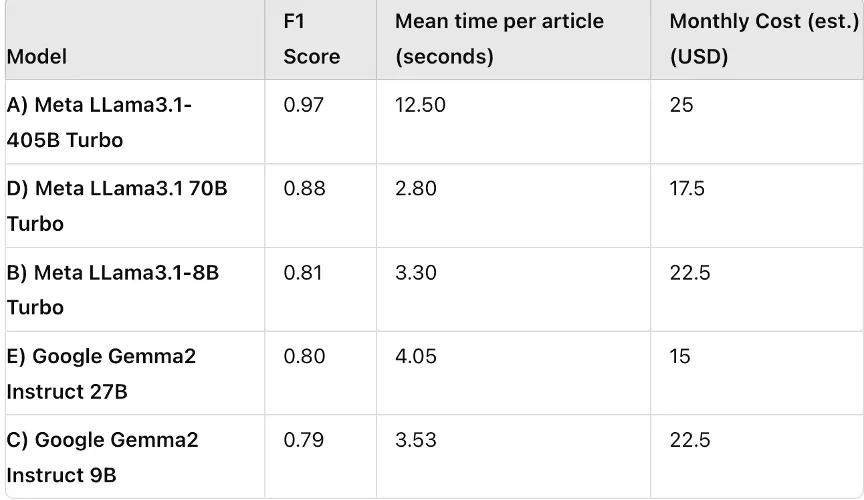
我正在尝试找到合适的模型来从新闻文章中识别人物、地点和组织。在决定使用本地模型之前,我已经尝试了3个Llama模型和2个Gemma模型,以下是我的结果(与人工策划的金标准对比)。
提示应该生成一个干净、有效的JSON,包含三个实体类别及其对应的跨度列表。
关于输出JSON的干净程度,我必须说Gemma模型要好得多,8B和70B的Llama模型经常忘记关闭列表、大括号或在JSON前加上任意文本,尽管我要求不要这样做。
你有什么建议吗?
顺便问一下,有没有一些紧凑的资源,我可以快速了解每个模型的token窗口,以便我能理解是否需要分块输入文本?
非常感谢。
讨论总结
本次讨论主要围绕使用Llama模型进行命名实体识别(NER)展开,涵盖了模型选择、JSON生成问题、工具推荐及性能比较等多个方面。参与者分享了各自的经验和建议,讨论了如何处理错误生成的JSON、选择合适的模型和工具进行推理,以及如何评估模型的性能。此外,还涉及了如何处理长文本输入和选择合适的模型参数等问题。
主要观点
- 👍 使用约束生成技术可以100%解决JSON生成问题
- 支持理由:约束生成技术能够确保输出格式正确,提高数据处理的可靠性。
- 反对声音:暂无。
- 🔥 应根据实体提取的准确性来评估模型,而不是JSON生成
- 正方观点:实体提取的准确性是评估模型性能的关键指标。
- 反方观点:JSON生成问题可以通过技术手段解决,不应成为评估的主要依据。
- 💡 处理错误生成的JSON并不复杂
- 解释:通过简单的代码调整和验证,可以有效处理错误生成的JSON。
- 🌟 需要资源了解模型的token窗口以决定是否需要分割输入文本
- 解释:了解模型的token窗口有助于优化文本处理流程,提高处理效率。
- 🚀 推荐使用vLLM引擎的约束生成功能
- 解释:vLLM引擎提供了强大的约束生成功能,能够有效解决JSON生成问题。
- 🎯 建议使用pydantic schema作为约束生成库的标准输入
- 解释:pydantic schema能够提供清晰的输入格式定义,简化约束生成过程。
金句与有趣评论
- “😂 Use proper constrained generation for JSON to solve that problem 100%, then re-do your tests.”
- 亮点:强调了约束生成技术在解决JSON生成问题中的重要性。
- “🤔 I’d be interested in the score of a basic encoder only model like Bert as a comparison, if you have some training data.”
- 亮点:提出了将BERT模型作为对比基准的建议,增加了讨论的广度。
- “👀 Output only a valid JSON object with three keys: ‘persons’, ‘places’, ‘organizations’. Each key must contain an array of unique strings which can also be empty.”
- 亮点:提供了一个详细的提示模板,有助于理解如何生成格式正确的JSON。
情感分析
讨论的总体情感倾向较为积极,参与者普遍对使用Llama模型进行NER持肯定态度。主要分歧点在于如何评估模型性能和处理JSON生成问题。可能的原因包括技术细节的理解差异和工具选择的偏好。
趋势与预测
- 新兴话题:约束生成技术在NER中的应用可能会成为后续讨论的热点。
- 潜在影响:优化JSON生成和提高实体提取准确性将对NER领域的研究和应用产生积极影响。
详细内容:
标题:关于使用 Llama 进行命名实体识别的热门讨论
近日,Reddit 上有一篇关于使用 Llama 进行命名实体识别的帖子引发了热烈讨论。该帖子展示了不同模型在 F1 分数、每篇文章的平均时间以及月成本等方面的对比数据,并分享了在实验中的一些发现和困惑,获得了众多用户的关注和大量评论。
帖子中提到,在尝试从报纸文章中识别人员、地点和组织时,对 3 个 Llama 模型和 2 个 Gemma 模型进行了实验,并给出了实验结果。同时,还指出在输出 JSON 的整洁度方面,Gemma 表现更好,而某些 Llama 模型存在一些问题。此外,还询问了关于理解每个模型的 token 窗口的资源,以便确定是否需要对输入文本进行分块处理。
讨论的焦点主要集中在如何解决模型输出 JSON 不规范的问题,以及如何选择更适合的模型和工具。有人建议使用适当的约束生成来解决 JSON 问题,比如通过 vLLM 等引擎的特定功能。也有人提到可以定义 pydantic 模式。还有用户分享自己使用 Llama 3.1 进行 NER 的经验,表示虽然存在一些小问题但不难处理,并且可以通过在提示中加入示例来改善输出格式。有人提到可以尝试 instructor 或 GliNER 等工具。有人对基本编码器模型如 Bert 的得分表现出兴趣,希望能进行对比。还有人分享了训练 Lora 适配器的经验。
有人表示:“使用适当的约束生成解决 JSON 问题能百分百解决,然后重新进行测试。LLM 应该根据实体提取的准确性来评判,而不是 JSON 生成。这部分已经解决了。”
也有人说:“我使用 Llama 3.1 进行 NER,从未遇到过输出格式不正确的 JSON 问题。它确实倾向于在 JSON 输出之外包含文本,但这很容易删除。此外,您可以在提示中包含一两个示例以改进它准确输出您想要的 JSON 格式。顺便说一下,我正在使用 Ollama,并开启了 JSON 输出选项。”
在这场讨论中,大家对于解决模型相关问题和探索更优方案各抒己见,为寻求更好的命名实体识别方法提供了丰富的思路和建议。


感谢您的耐心阅读!来选个表情,或者留个评论吧!