讨论总结
Reddit上的讨论围绕“Simple Bench”基准测试展开,该测试评估了不同大型语言模型(LLMs)的性能。用户们对测试的透明度、实用性和结果的可靠性提出了质疑,同时也讨论了模型性能和测试方法的改进空间。讨论中涉及了对模型在实际应用中的表现、测试题目的措辞和逻辑性、以及模型在处理包含“惊喜转折”的逻辑谜题时的表现。此外,用户还对人类在测试中的表现表示好奇,并表达了参与测试的兴趣。整体上,讨论反映了用户对AI模型性能的关切和对测试方法的深入探讨。
主要观点
- 👍 需要更多类似Simple Bench的基准测试
- 支持理由:更真实地反映LLMs的表现。
- 反对声音:基准测试的题目应保持私密,以防模型被针对性训练。
- 🔥 基准测试的透明度和结果的可靠性
- 正方观点:用户对测试的透明度和结果的可靠性表示怀疑。
- 反方观点:测试可能由同一团队进行,人类平均得分可能被过高评价。
- 💡 模型在实际应用中的表现和改进方向
- 解释:用户讨论了模型在实际应用中的表现和改进方向,以及模型在处理包含“惊喜转折”的逻辑谜题时的表现。
- 👀 人类在测试中的表现
- 解释:用户对人类在测试中的表现表示好奇,并表达了参与测试的兴趣。
- 🌟 多模态模型的发展趋势
- 解释:讨论了未来多模态模型的发展趋势,特别是如何将语言模型与视频等空间-时间潜在空间相结合。
金句与有趣评论
- “😂 I’d rather have private test suites that can’t be gamed or trained on.”
- 亮点:强调了测试的私密性和防止针对性训练的重要性。
- “🤔 How do they do the human test? I’d love to try it if I can, lol.”
- 亮点:表达了用户对参与人类测试的兴趣和好奇心。
- “👀 Knowledge went up but reasoning went down. This is a reasoning bench.”
- 亮点:指出了知识水平提高但推理能力下降的现象,引发了对基准测试有效性的讨论。
情感分析
讨论的总体情感倾向是质疑和探讨。用户们对“Simple Bench”基准测试的透明度和可靠性表示怀疑,同时也对模型在实际应用中的表现和改进方向进行了深入的探讨。主要分歧点在于测试的公正性和有效性,以及模型性能的实际应用价值。可能的原因包括对AI技术发展的期待与现实之间的差距,以及对测试方法和结果的信任度。
趋势与预测
- 新兴话题:多模态模型的发展和应用,以及AI模型在处理非文本数据时的表现。
- 潜在影响:对AI模型构建者和用户来说,更透明和公正的基准测试将有助于推动模型性能的提升和实际应用的改进。同时,对多模态模型的研究和应用可能会带来新的技术突破和应用场景。
详细内容:
标题:关于 LLM 基准测试的热门 Reddit 讨论
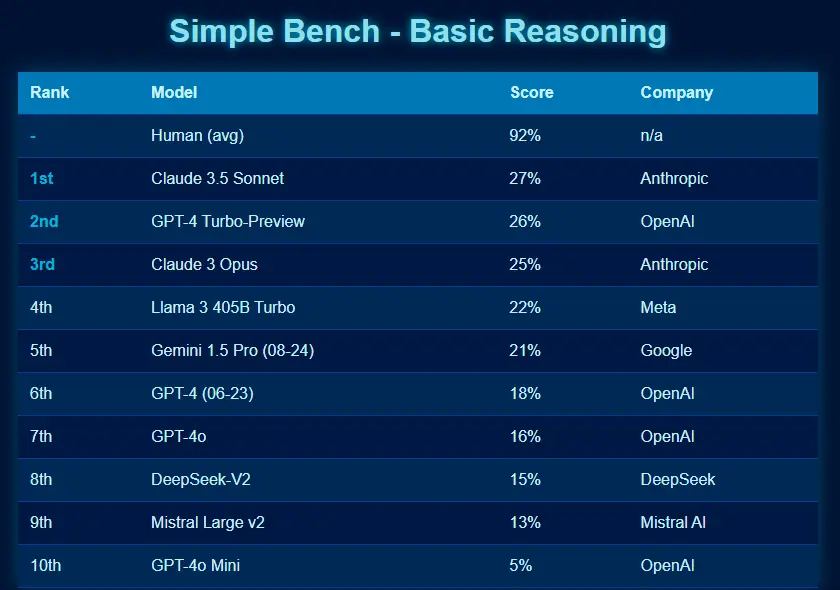
近期,Reddit 上一则有关“Simple Bench (来自 AI Explained YouTuber)与 LLM 在现实世界经验匹配度”的帖子引发了广泛关注。该帖子包含一张展示不同模型在基准测试中得分的排名表格图片,链接为:https://i.redd.it/2iuourvdngkd1.png 。帖子获得了众多点赞和大量评论,主要讨论方向包括对基准测试的有效性、实用性,以及 LLM 与人类在推理能力上的比较等。
讨论焦点与观点分析:
- 有人认为这样的基准测试很有必要,能让人们看到 LLM 在某些方面得分低于人类平均水平。但也有人担忧测试问题被公开可能导致模型被训练从而影响得分。
- 有人觉得无法验证的测试套件可能存在问题,比如作者可能随意设定数据。但也有人认为私人测试套件能避免被操纵,只要信任制作者即可。
- 对于测试结果与之前视频不一致的情况,有人解释这是因为基准测试版本更新以及模型更新。
- 关于测试中的具体问题,如关于煎锅中放冰块的问题,大家争论其表述是否清晰合理。有人认为表述糟糕,有人则认为明确指出煎锅在煎鸡蛋,所以锅必然是热的。
- 对于 LLM 的推理能力,有人认为这类测试更像是在测量与物理现实的时空关联,而非单纯的快慢思考。
- 有人尝试让 LLM 进行慢思考来提高推理能力,但效果不佳,难以有效传达慢思考的方式。
- 对于人类在测试中的高分表现,有人质疑其科学性和普遍性。
总的来说,这次讨论展现了大家对 LLM 基准测试的多角度思考和热烈探讨,也反映了人们对于 LLM 能力评估的关注和思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!