大家好!上个月,我们推出了KTransformers项目(https://github.com/kvcache-ai/ktransformers),将本地推理带到了236B参数的DeepSeeK-V2模型。社区的反响非常热烈,充满了宝贵的反馈和建议。基于这一势头,我们很高兴地推出下一个重大更新:本地1M上下文推理!
https://reddit.com/link/1f3xfnk/video/oti4yu9tdkld1/player
近期,ChatGLM和InternLM发布了支持1M令牌的模型,但这些模型通常需要超过200GB的完整KVCache存储,这对LocalLLaMA社区的许多用户来说并不实用。不过,许多研究表明,推理过程中的注意力分布往往是稀疏的,这简化了高效识别高注意力令牌的挑战。
在这次最新更新中,我们讨论了几项关键的研究贡献,并介绍了一个在KTransformers内部开发的一般框架。该框架包括一个高度高效的CPU稀疏注意力操作符,基于H2O、InfLLM、Quest和SnapKV等有影响力的工作。结果令人鼓舞:KTransformers不仅将速度提升了6倍以上,而且在我们的1M“大海捞针”挑战中达到了92.88%的成功率,在128K测试中更是达到了完美的100%——这一切仅在一台24GB GPU上实现。
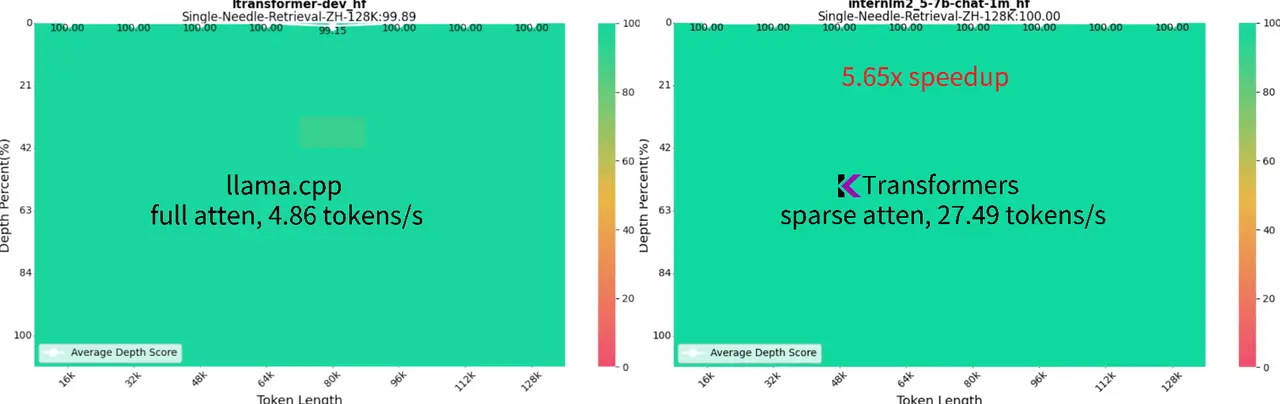
深入了解更多技术细节,请访问:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/long_context_tutorial.md 和 https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/long_context_introduction.md
此外,自我们开源以来,我们根据您的反馈实施了许多改进:
- 2024年8月28日:通过4bit MLA权重,将236B DeepSeekV2所需的DRAM从20GB减少到10GB。我们认为这也是一个巨大的进步!
- 2024年8月15日:加强了注入和多GPU教程。
- 2024年8月14日:增加了对’llamfile’作为线性后端的支持,允许将任何线性操作符卸载到CPU。
- 2024年8月12日:增加了多GPU支持和新的模型;增强了GPU反量化选项。
- 2024年8月9日:增强了原生Windows支持。
我们迫不及待想看到您下一步的需求!给我们一颗星,以保持所有更新的关注。即将推出:我们将深入研究视觉-语言模型,如Phi-3-VL、InternLM-VL、MiniCPM-VL等。敬请期待!
讨论总结
本次讨论主要围绕KTransformers项目的最新进展,特别是本地1M上下文推理的实现。讨论中涉及了技术改进、内存优化、多GPU支持等多个方面。社区成员对项目的开源性质和基于反馈的持续改进表示赞赏,同时也提出了关于模型安全和集成问题的关注。整体上,讨论反映了技术社区对高性能AI模型需求的增加以及对技术进步的积极响应。
主要观点
- 👍 KTransformers项目通过稀疏注意力操作符提高了处理速度和效率
- 支持理由:新模型在1M令牌的挑战中达到了92.88%的成功率,在128K测试中达到了100%的成功率。
- 反对声音:Uhlo质疑InternLM2.5的实际有效上下文长度。
- 🔥 项目根据社区反馈进行了多项技术改进
- 正方观点:如减少内存需求、增强多GPU支持等。
- 反方观点:用户davesmith001在安装过程中遇到404错误。
- 💡 项目已开源,并持续根据用户反馈进行更新和优化
- 解释:社区成员对项目的开源性质和基于反馈的持续改进表示赞赏。
- 👀 KTransformers项目是否能集成到lmstudio中?
- 解释:用户bblankuser询问集成可能性,CombinationNo780提供了与Ollama兼容的API。
- 🤔 使用中国模型进行政府或专有工作存在安全风险
- 解释:评论者指出无法保证源站点不会提供修改过的模型以绕过安全措施。
金句与有趣评论
- “😂 InternLM 20B is so underrated.”
- 亮点:评论者认为InternLM 20B在128K上下文长度下表现极为出色,但被低估了。
- “🤔 What is your response to the effective use of context length with a more realistic use of the context?”
- 亮点:Uhlo质疑InternLM2.5的实际有效上下文长度,引发讨论。
- “👀 Using Only 24GB VRAM and 130GB DRAM”
- 亮点:Normal-Ad-7114强调KTransformers项目在有限硬件资源下的高效性能。
- “😂 Remember yesterday, when we were proud of reaching 8000 tokens context length? Lmao!”
- 亮点:LuluViBritannia讽刺地回忆过去对8000个token的自豪感,现在显得微不足道。
- “🤔 Could this be integrated in lmstudio?”
- 亮点:bblankuser询问KTransformers项目是否能集成到lmstudio中,引发技术集成的讨论。
情感分析
讨论的总体情感倾向积极,社区成员对KTransformers项目的最新进展表示赞赏和兴奋。主要分歧点在于模型的实际有效上下文长度和安全性的担忧。这些分歧可能源于对新技术的不确定性和对潜在风险的警惕。
趋势与预测
- 新兴话题:未来可能会有更多关于视觉-语言模型的讨论,如Phi-3-VL, InternLM-VL等。
- 潜在影响:KTransformers项目的进展可能会推动AI模型在本地运行的高效性和可用性,对相关领域或社会的技术发展产生积极影响。
详细内容:
标题:KTransformers 项目带来本地 1M 上下文推断的重大突破
在 Reddit 上,一篇关于 KTransformers 项目的帖子引发了热烈讨论。该帖子获得了众多关注,众多用户纷纷发表评论。原帖主要介绍了 KTransformers 项目在本地 1M 上下文推断方面的新进展,包括高效的稀疏注意力操作器、性能提升、内存需求减少以及一系列的功能增强等。
这个帖子引发了多个方面的讨论。有人对中国在相关领域的情况提出疑问,比如[JeffieSandBags]表示不清楚中国政府在此方面的支持情况以及美国公司是否有被研究限制。也有人对模型的实际效果和应用提出了问题,如[Uhlo]询问对实际使用中上下文长度的有效利用情况。还有人关心模型的支持范围和运行条件,像[Lissanro]希望能添加更多支持的模型,[LeBoulu777]询问自己的硬件配置能否运行。
有人称赞这一成果令人印象深刻,比如[u/FrostyContribution35]就表示这个项目追踪起来很令人兴奋。但也有人表达了担忧,[3-4pm]提醒不要将中国模型用于政府或专有工作,担心存在安全风险,引发了与[Didi_Midi]等人的争论。
有用户分享道:“我也是个电子爱好者,中国曾有很多创新成果。听到对 AI 芯片、工具和软件的禁令,我很难过,因为中国肯定会推出一些创新产品,进一步推动竞争。”
在讨论中,[CombinationNo780]对许多问题进行了回应。他指出,对于[Uhlo]关于有效上下文长度的疑问,会在之后尝试 RULER;对于能否在特定硬件配置下运行的问题,比如[LeBoulu777]提到的 2 个 RTX 3060,他表示是有可能的,因为 KTransformers 支持基于 PP 的多 GPU 推断,并提供了相关描述链接。
关于内存需求的问题,[CombinationNo780]解释说,稀疏注意力操作器能够选择性地扫描 KVCache 的部分内容,从而加快解码速度,在 128K 上达到 100%,在 1M 上达到 92.88%。
对于安全方面的担忧,各方观点不一。有人认为目前开源趋于安全,也有人认为超级大国的资源可能使很多事情成为可能,存在潜在风险。
总的来说,KTransformers 项目的这一进展引发了广泛而深入的讨论,涉及技术效果、应用范围、安全问题等多个方面,充分展示了社区对这一领域的关注和思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!