这是一个关于实际最大显存利用率与从大型语言模型中获得的实际上下文大小之间的快速比较。
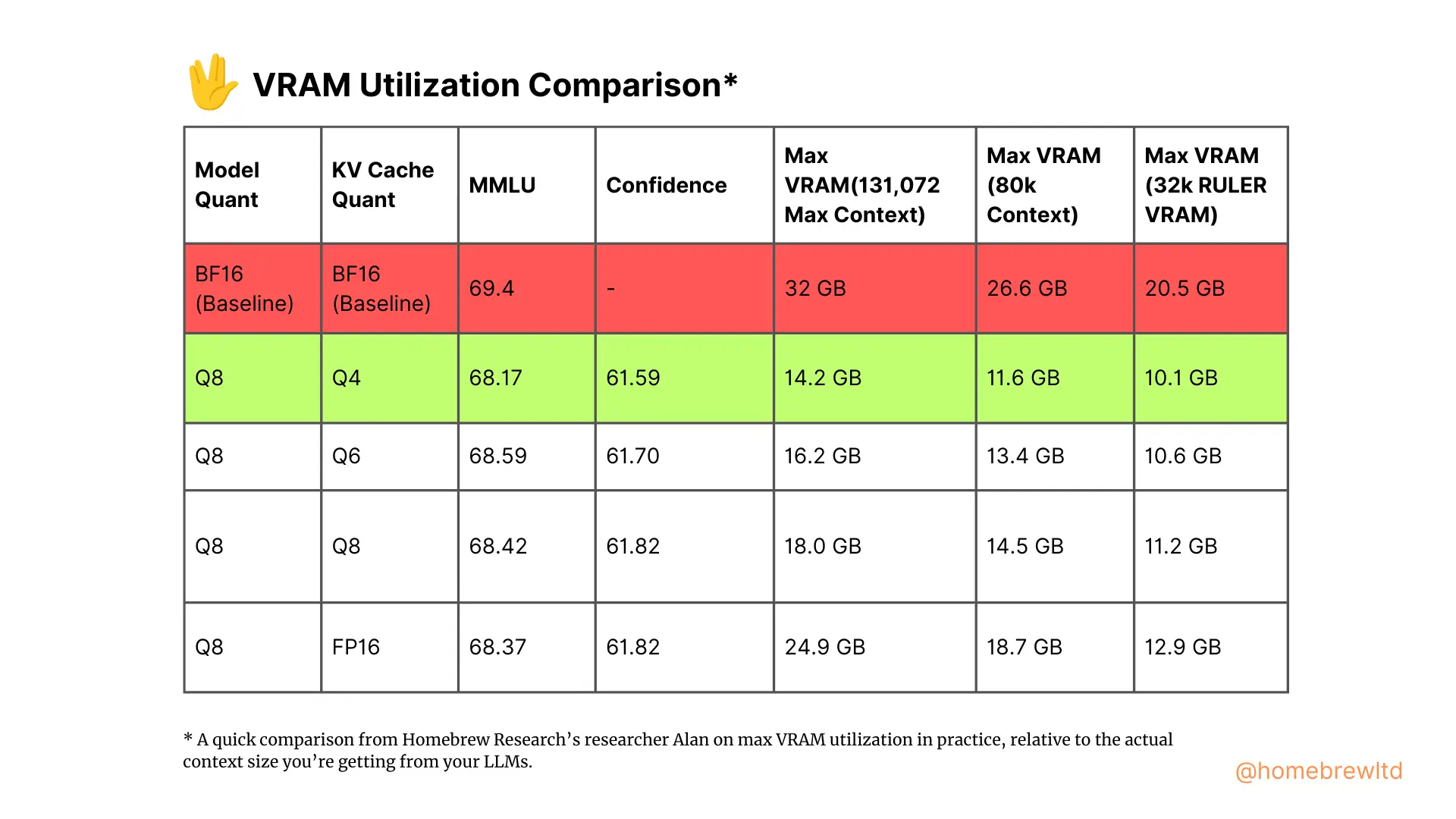
通常情况下,llama3.1 8bn BF16至少需要24GB显存才能运行。
但llama3.1 8b在Q8和Q6 KV缓存量化下实际上可以在12GB显存中运行。它可以在2000美元以下的消费级PC上运行。
在性能方面,Q8模型与Q6 KV(MMLU 68.59)接近BF16基线(69.4)。你将获得模型作者最初设想的性能水平!
这是工具包:https://github.com/hsiehjackson/RULER
这个实验灵感来自RULER论文,它为我们提供了一种测量长上下文语言模型实际上下文大小的方法:https://arxiv.org/pdf/2404.06654
–
提醒一下:我们所有的模型训练和测试都在X上公开进行。我们希望在那里见到你:https://x.com/homebrewltd
讨论总结
本次讨论主要聚焦于不同量化级别下机器学习模型的VRAM利用率和性能优化。参与者讨论了如Mistral Nemo、Gemma 9B、InternLM 20B和Deepseek Code V2 Lite等模型在不同量化设置下的运行情况,以及这些设置对推理速度和上下文大小的影响。讨论中涉及的主要观点包括量化技术在速度与质量之间的权衡、不同量化级别的实际应用效果,以及如何根据具体工作负载选择最优的量化方法。总体上,讨论氛围偏向技术性和实用性,参与者提供了丰富的技术细节和实际操作建议。
主要观点
- 👍 量化技术在有限VRAM中的应用
- 支持理由:多个模型如Mistral Nemo和Gemma 9B在合理量化下表现良好。
- 反对声音:量化级别的选择应根据具体工作负载来确定。
- 🔥 Q4和Q6量化级别在推理速度和上下文大小方面的优势
- 正方观点:Q4和Q6相比于Q8能提供更好的性能,且损失最小。
- 反方观点:应考虑每秒处理的令牌数(tk/s)作为性能指标。
- 💡 量化技术在速度与质量之间的权衡
- 解释:在不考虑输出质量的情况下,Q4量化级别的模型执行速度可能比Q8/FP16快。
- 👍 量化级别的灵活性和优化空间
- 支持理由:可以为KV缓存使用不同的量化方法,提供了优化VRAM利用率的可能性。
- 反对声音:默认的量化设置可能不是最佳选择。
- 🔥 量化技术在实际应用中的性能影响
- 正方观点:询问不同量化级别的生成时间数据,探讨更量化的KV缓存对处理提示时间的影响。
- 反方观点:量化级别的优化应根据具体工作负载来确定。
金句与有趣评论
- “😂 Everlier:Indeed, you can also run Mistral Nemo, Gemma 9B, and a lot of cool fine-tunes at a decent quant in the same VRAM.”
- 亮点:展示了量化技术在有限VRAM中的广泛应用。
- “🤔 Temporary-Size7310:I disagree, in terms of inference speed and context size you can do better with Q4, Q6 than Q8 with minimal loss, your table should show tk/s.”
- 亮点:提出了对量化级别性能评估的新视角。
- “👀 keepthepace:Wow, I knew Q8 worked but only with minimal context window. I had not realized you can have a different quant for the KV cache!”
- 亮点:揭示了量化技术在实际应用中的新发现。
情感分析
讨论的总体情感倾向偏向于技术性和实用性,参与者对量化技术在VRAM利用率和模型性能优化方面的讨论表现出浓厚的兴趣。主要分歧点在于不同量化级别的实际应用效果和性能优化策略,部分参与者对量化级别的灵活性和优化空间表示赞赏,而另一些则强调量化级别的选择应根据具体工作负载来确定。
趋势与预测
- 新兴话题:量化技术在不同工作负载下的最优配置。
- 潜在影响:量化技术的优化将进一步推动机器学习模型在有限VRAM环境下的应用,可能影响硬件设计决策,例如如何分配和管理GPU上的VRAM资源。
详细内容:
标题:Reddit 上关于 VRAM 利用率和模型量化的热门讨论
在 Reddit 上,有一个关于 VRAM 利用率和模型量化的热门帖子引起了广泛关注。该帖子展示了一张关于不同量化级别下模型的 VRAM 利用率对比图表,并进行了详细分析。帖子获得了众多点赞和大量的评论。
讨论主要围绕着不同量化级别对 VRAM 利用率和模型性能的影响展开。有人认为,在相同的 VRAM 条件下,可以运行诸如 Mistral Nemo、Gemma 9B 等模型的合适量化版本。也有人提到 InternLM 20B 或 Deepseek Code V2 Lite 能够很好地适应。
对于量化级别的选择,存在不同观点。有人认为在推理速度和上下文大小方面,Q4、Q6 可能比 Q8 表现更好,且损失较小,不过也有人认为应该根据具体工作负载来选择最优的量化级别。
还有用户指出,Q6/Q6 也值得关注。对于 Q4 和 kv16 的情况,有用户认为如果制作表格并声称“过度量化”,应该在表格中呈现相关数据点。
有用户分享道:“在我的经验中,Q8 到 Q5 的性能差异基本可以忽略不计,并且您会获得很好的 T/s 提升。对于更大的模型(30B 以上),Q8 到 Q4 的情况也是如此。但这并不意味着 Q8 对于您的使用情况是最佳的。像帖子标题这样的笼统陈述通常是错误的。”
也有用户提到,操作系统和应用程序对 VRAM 的使用情况较为复杂,不能简单地一概而论。
这场讨论的核心问题在于如何在保证模型性能的前提下,选择最合适的量化级别以优化 VRAM 的利用率。不同的用户根据自己的经验和研究,提出了各自的见解,为相关研究和开发人员提供了丰富的参考和思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!