讨论总结
本次讨论主要围绕Mistral Large 2在SEAL Coding Leaderboard上的表现展开,涵盖了模型性能比较、量化级别、安全性、评估方法等多个技术话题。评论者们对Mistral Large 2的性能表示赞赏,并与其他模型如CodeLlama 34b、Claude Sonnet 3.5等进行对比。讨论中还涉及了本地模型与托管模型的优缺点、量化级别对模型性能的影响、以及评估方法的透明性和可重复性等问题。总体上,讨论氛围专业且充满技术讨论,评论者们分享了各自的使用经验和见解,提供了丰富的技术信息和观点。
主要观点
- 👍 Mistral Large 2在SEAL Coding Leaderboard上的表现令人印象深刻
- 支持理由:评论者认为Mistral Large 2在本地模型中达到了专业级水平,性能优越。
- 反对声音:无明显反对声音,但有评论提到Mistral Large 2在本地运行时对Mac的性能要求较高。
- 🔥 量化级别在AI模型性能比较中至关重要
- 正方观点:不同量化级别的模型在实际任务中的表现可能大不相同,基准测试应包括量化级别以提供更准确的比较。
- 反方观点:无明显反方观点,但有评论提到量化级别(如Q6)可能不足以充分发挥Mistral Large的性能。
- 💡 本地模型与托管模型的优缺点
- 支持理由:本地模型在已有硬件的情况下成本较低,能够保证使用完整的上下文大小,避免在高峰时段被简化。
- 反对声音:本地模型的速度可能不如托管模型,但可以通过技术手段提高。
- 🔍 评估方法的透明性和可重复性是关键问题
- 支持理由:评估的透明性和可重复性是关键问题,小型和新进入者在评估中面临不公平竞争。
- 反对声音:闭源评估在防止模型“作弊”方面有其必要性。
- 🚀 Mistral Large 2的优化进展
- 支持理由:Mistral Large Instruct 模型通过预量化至 4bit,实现了 4 倍更快的下载速度,减少了 1-2GB 的 VRAM 使用。
- 反对声音:无明显反对声音,但有用户询问 Exl2 格式的优化效果是否同样显著。
金句与有趣评论
- “😂 SomeOddCodeGuy:This honestly doesn’t surprise me; this model is so good. In terms of local models, this is probably the first that I honestly felt was proprietary tier for coding.”
- 亮点:评论者对Mistral Large 2的性能表示高度认可,认为其在本地模型中达到了专业级水平。
- “🤔 RobotDoorBuilder:Their annotation service is one of the worst out there. Their eval is entirely biased by the quality of their annotation platform.”
- 亮点:评论者对Scale公司的评估方法提出了批评,认为其标注服务质量差,导致评估结果偏颇。
- “👀 danielhanchen:I also managed to pre-quantize Mistral Large Instruct to 4bit for 4x faster downloads and 1-2GB of less VRAM use due to less fragmentation!”
- 亮点:评论者分享了Mistral Large Instruct模型的优化进展,展示了技术优化的成果。
- “😅 Lynorisa:What code would be on the NSFW side? Illegal / malicious code or raunchy variable names? 😅”
- 亮点:回复者幽默地询问NSFW代码的具体含义,增加了讨论的趣味性。
- “💡 FrostyContribution35:Moving forward I feel the community needs to include the quant level in the benchmarks.”
- 亮点:评论者强调了量化级别在AI模型性能比较中的重要性,提出了改进基准测试的建议。
情感分析
讨论的总体情感倾向偏向正面,评论者们对Mistral Large 2的性能表示赞赏,并积极参与技术讨论。主要分歧点在于评估方法的透明性和可重复性,以及量化级别对模型性能的影响。可能的原因包括对技术细节的不同理解和对评估方法的不同期待。
趋势与预测
- 新兴话题:量化级别在AI模型性能比较中的重要性可能会引发后续讨论,特别是在基准测试中如何更准确地反映模型的实际表现。
- 潜在影响:对评估方法透明性和可重复性的讨论可能会推动评估标准的改进,从而促进AI模型评估的公平性和准确性。
详细内容:
标题:Mistral Large 2 在 SEAL 编码排行榜上的崛起引发热议
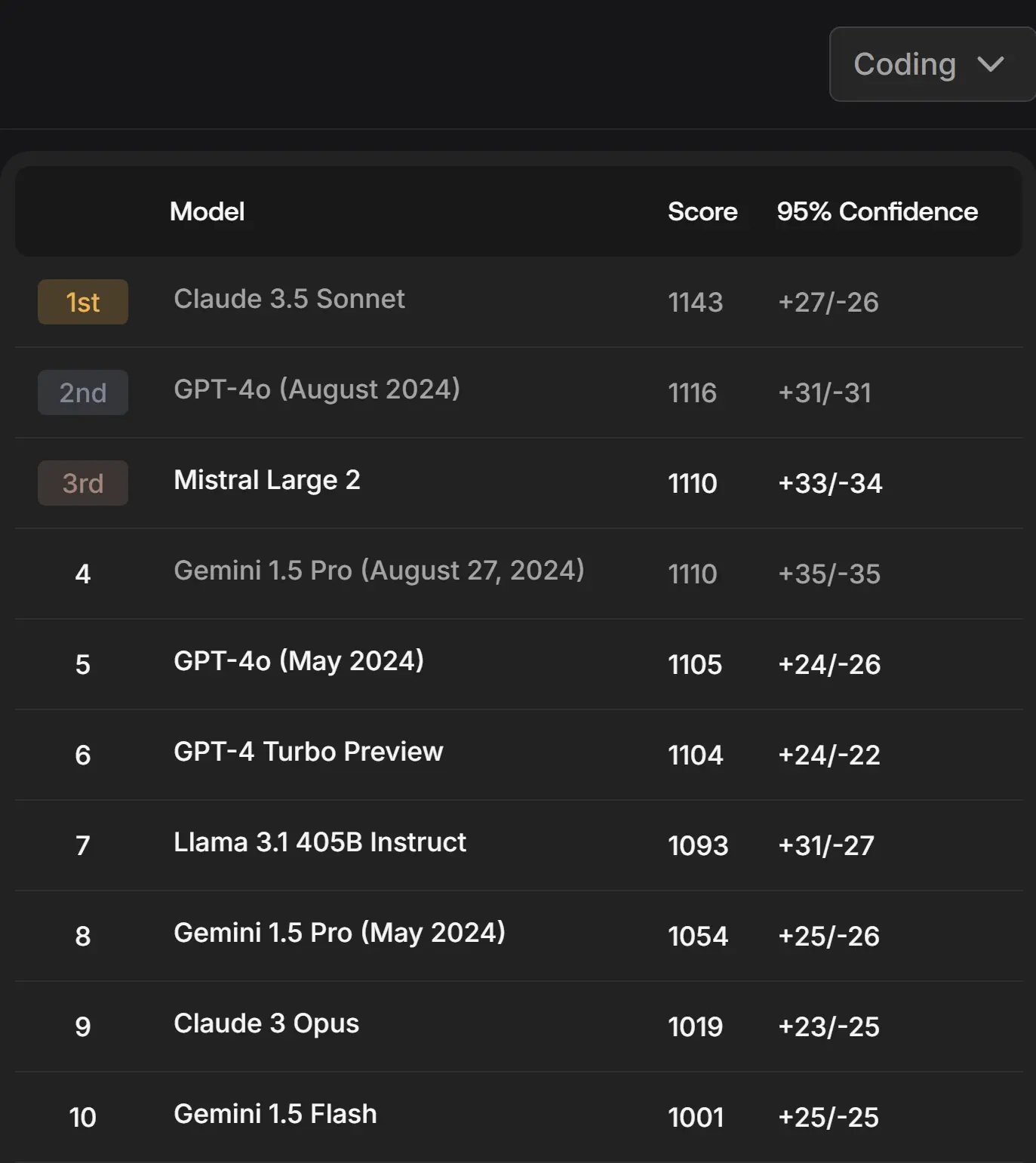
Reddit 上一则关于“Mistral Large 2 现在在 SEAL 编码排行榜上排名第三”的帖子引发了众多网友的热烈讨论。该帖子包含了一张详细展示不同 AI 模型性能比较的表格图片,获得了大量的关注,评论数众多。帖子主要探讨了 Mistral Large 2 在编码领域的出色表现以及其与其他模型的对比。
讨论焦点与观点分析: 有人认为 Mistral Large 2 表现出色,是一款非常优秀的模型。比如有人说:“这模型太棒了,在本地模型中,它可能是首个达到专有级别编码能力的。”也有人指出通过与 CodeLlama 34b 对比,更能凸显 Mistral Large 2 的优势。 还有人分享了自己经常查看的其他编码相关的排行榜链接。 对于模型的性能,有人提到在多 GPU 系统上本地运行 Mistral Large 2 的体验,称新的 exllamav2 张量并行处理能力很强。 关于模型的速度,有人表示对于 50k 令牌的初始大型输入,其处理速度还不错。 有人喜欢 Mistral Large 2 是因为它在本地运行时能保证总上下文大小,且不会在高峰时段被降低性能。 同时,也有对排行榜本身的质疑,认为其评估可能存在偏差、不客观,比如只评估了部分提供商的模型等。 对于模型的量化水平,有人认为社区在进行基准测试时应包含这一因素,否则会影响人们对模型的选择。
总的来说,这次关于 Mistral Large 2 在编码排行榜上的讨论十分丰富,大家从不同角度发表了自己的看法,为深入了解这一模型提供了多样的视角。


感谢您的耐心阅读!来选个表情,或者留个评论吧!