讨论总结
本次讨论主要围绕“Reflection-70B”AI模型的性能提升展开,涵盖了多个专业领域的话题。讨论者们关注了该模型在接受度评分上的显著提升,以及其在复杂推理和创意写作等任务中的表现。此外,讨论还涉及了模型的微调效果、硬件需求、基准测试的公平性以及实际应用中的用户体验等问题。总体上,讨论氛围专业且信息量大,参与者们对模型的性能和技术细节进行了深入探讨。
主要观点
👍 “Reflection-70B”模型在接受度评分上有显著提升
- 支持理由:从41.2%提升到50%,增加了9个百分点。
- 反对声音:有评论者对基准测试结果表示怀疑,认为其超出了合理范围。
🔥 该模型可能引发公司间的竞标战
- 正方观点:评论者认为该模型的优秀表现会吸引公司竞相投资。
- 反方观点:有评论者对模型的实际应用效果持怀疑态度。
💡 “Reflection-70B”在处理长系统提示时存在困难
- 解释:尝试了包含数千个token的自定义系统提示,但未能成功。
👍 微调模型通常优于同规模的基础模型
- 支持理由:评论者认为微调模型在性能上通常表现更优。
- 反对声音:有评论者对微调模型的实际效果表示怀疑。
🔥 基准测试的公平性受到质疑
- 正方观点:评论者认为基准测试结果应反映模型的实际性能。
- 反方观点:有评论者认为基准测试容易被操纵,不应过分依赖。
金句与有趣评论
“😂 next-choken:Lmao gotta love seeing one random guy’s name hanging out with the titans of AI industry.”
- 亮点:幽默地评论了“Reflection-70B”模型在AI行业中的地位。
“🤔 LiquidGunay:I feel like this might end up being similar to WizardLM 8x22B, better reasoning but extremely verbose outputs which make real world usage difficult.”
- 亮点:指出了模型在实际应用中的潜在问题。
“👀 Chongo4684:It’s consistently been true that fine tunes are better than base models of the same size.”
- 亮点:强调了微调模型在性能上的优势。
“😂 Downtown-Case-1755:Look at WizardLM hanging out up there.”
- 亮点:幽默地评论了“WizardLM”模型的表现。
“🤔 meister2983:So basically something is improved, but the posted benchmarks are way out of range.”
- 亮点:对基准测试结果表示怀疑。
情感分析
讨论的总体情感倾向偏向专业和信息性,参与者们对模型的性能和技术细节进行了深入探讨。主要分歧点在于对基准测试结果的信任度,部分评论者认为基准测试容易被操纵,不应过分依赖。此外,对于模型的实际应用效果,也有不同的看法和怀疑。
趋势与预测
- 新兴话题:微调模型与基础模型的性能比较,以及基准测试的公平性问题可能会引发后续讨论。
- 潜在影响:对AI模型的性能评估方法可能会产生影响,促使行业更加关注基准测试的可靠性和公平性。
详细内容:
标题:Reflection 70B 在独立基准测试中的出色表现引发Reddit热议
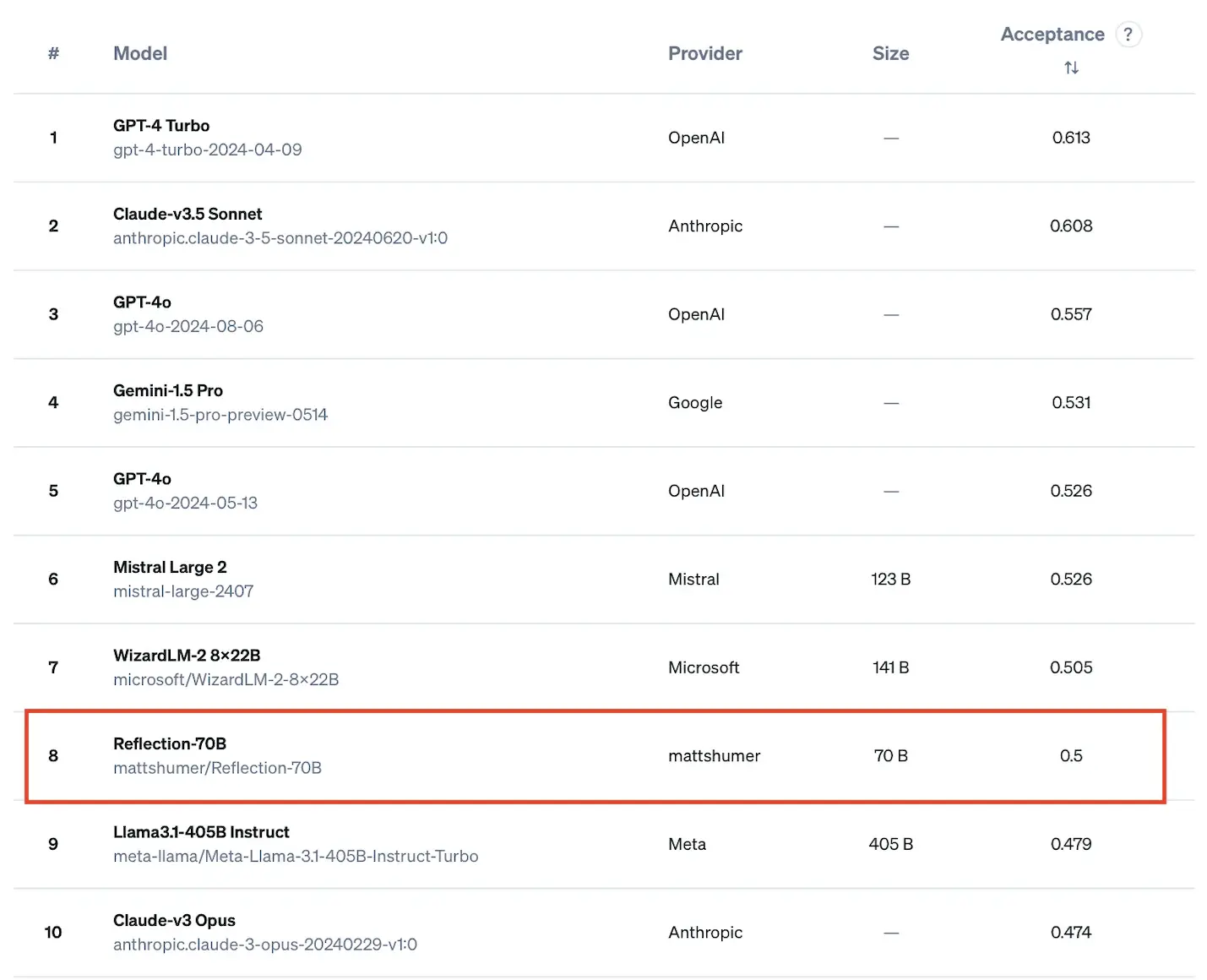
最近,Reddit上一个关于Reflection 70B的帖子引起了广泛关注。原帖指出,Reflection 70B在首次独立基准测试(ProLLM StackUnseen)中表现出色,其性能较基础的llama 70B模型提高了9个百分点(从41.2%提升至50%)。该帖子包含一张展示不同AI模型性能的表格图片,图片链接为:https://i.redd.it/tuawfbwms3nd1.png 。帖子获得了众多点赞和大量评论,引发了关于Reflection 70B的性能、应用以及与其他模型比较等多方面的热烈讨论。
讨论焦点与观点分析: 有人表示对Reflection 70B的出色表现感到惊讶,认为这可能会引发科技公司之间的人才争夺。 有人质疑Reflection 70B的基准测试结果,认为与其他大型模型的比较可能不够公平,比如有人提出它只是对llama 3.1-70b的微调,不能与未微调的版本直接对比。 有人探讨了运行这些模型所需的硬件条件,如对于70b模型,可能需要一张4090显卡和32GB内存;对于405b模型,则需要强大的资金支持来建立小型数据中心。 对于Reflection 70B在创意写作方面的表现,存在不同看法。有人认为它可能有助于提升写作的连贯性和准确性,但也有人认为过度的自我批判和提示可能导致输出质量下降。 有人认为Reflection 70B的成功可能会给大型科技公司带来冲击,促使它们采用类似的技术或改进现有模型。 还有人担心基准测试结果可能被操纵,或者存在数据泄露等问题。
总的来说,Reddit上关于Reflection 70B的讨论展现了大家对AI模型发展的关注和思考,也反映了在新技术出现时所存在的各种疑虑和期待。


感谢您的耐心阅读!来选个表情,或者留个评论吧!