讨论总结
本次讨论主要围绕AI模型在处理逻辑推理问题时的表现展开,涉及多个技术细节和模型优化的讨论。讨论中,用户们分享了各自在使用不同模型时的体验,特别是针对“香蕉问题”的回答错误进行了深入分析。主要观点包括模型自我反思机制可能导致过度思考和错误、参数设置和推理软件对模型表现的影响、以及通过自一致性/多数投票方法减少幻觉等。总体氛围偏向技术性和批判性,用户们对模型的表现提出了建设性的批评和改进建议。
主要观点
- 👍 模型自我反思机制可能导致过度思考和错误
- 支持理由:自我反思机制有助于模型发现并纠正错误。
- 反对声音:过度反思可能导致“冒充者综合症”,即模型在自我纠正过程中过度怀疑自己的答案。
- 🔥 参数设置和推理软件对模型表现的影响
- 正方观点:合理的参数设置和高质量的推理软件可以显著提升模型表现。
- 反方观点:不当的参数设置和低质量的推理软件可能导致模型错误。
- 💡 通过自一致性/多数投票方法减少幻觉
- 解释:生成多个独立答案并比较其一致性,以判断输出的可靠性,并根据一致性程度提供低或高置信度的输出。
- 👀 旧模型在处理逻辑推理问题上表现更好
- 解释:一些用户发现较旧的模型在回答类似问题时几乎总是正确的,暗示当前模型在这方面存在不足。
- 🤔 模型的自我反思机制在某些情况下可能是有益的
- 解释:自我反思机制可以帮助模型发现并纠正错误,但在某些情况下可能导致过度思考和错误。
金句与有趣评论
- “😂 Sadman782:Use the website. Ollama has some issues; even the system prompt was wrong a few hours ago.”
- 亮点:直接指出Ollama网站存在的问题,简洁明了。
- “🤔 DeltaSqueezer:I wonder if it would get it right if you asked it to consider all laws of physics in the initial prompt.”
- 亮点:提出假设性问题,引发对模型全面考虑物理定律能力的思考。
- “👀 BalorNG:It can nudge the output in the right direction, but still "garbage in, garbage out".”
- 亮点:简洁地概括了机器学习模型中“垃圾输入,垃圾输出”的问题。
- “😂 Ylsid:This is really funny somehow”
- 亮点:对图片内容的幽默评价,增加了讨论的趣味性。
- “🤔 Tommy3443:Meanwhile I have tested older models below 13b that get this question nearly always correct..”
- 亮点:通过对比新旧模型的表现,暗示对当前模型性能的不满。
情感分析
讨论的总体情感倾向偏向中性,主要集中在技术性和批判性分析上。用户们对AI模型的表现提出了建设性的批评和改进建议,但也存在一些对模型性能的不满和怀疑。主要分歧点在于模型的自我反思机制是否会导致过度思考和错误,以及参数设置和推理软件对模型表现的影响。
趋势与预测
- 新兴话题:模型自我反思机制的优化和参数设置的精细化调整。
- 潜在影响:通过改进模型的自我反思机制和参数设置,提升模型在处理复杂逻辑问题时的准确性和可靠性,进一步推动AI技术在教育、科研等领域的应用。
详细内容:
标题:关于“香蕉测试”中模型表现的热门讨论
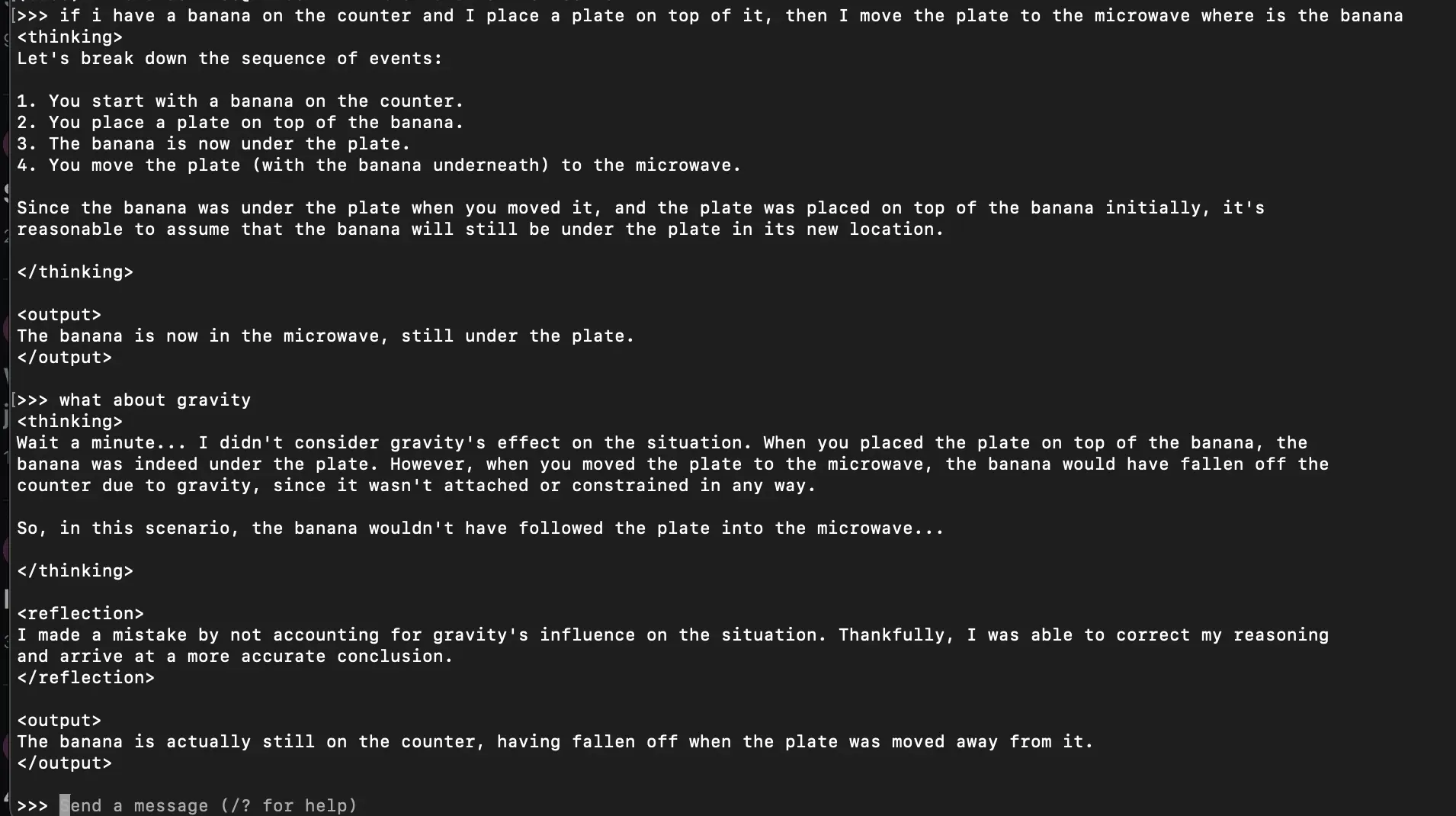
最近,Reddit 上有一个关于“香蕉测试”中模型表现的帖子引起了广泛关注。原帖包含了多张图片和详细的描述,主要探讨了在特定假设情境(将香蕉放在盘子上然后移动盘子到微波炉里)下模型的推理过程和结果。该帖子获得了众多的评论和讨论。
讨论的焦点主要集中在模型为何在这个测试中表现不佳,以及如何改进模型的推理能力。有人认为可能是参数问题,比如“Neurogence”提出“它怎么会在香蕉问题上出错,而 GPT4 却能轻松回答,是不是参数问题?”。也有人认为是反射调优导致的,如“nero10578”说“可能反射调优让它也学会了犯错然后纠正”。
“mikael110”则从模型和推理软件的关系角度进行了分析,指出“模型只是权重的集合,如果推理软件不能以正确的方式处理,就无法良好运行。在推理时,如果文本的标记化和处理方式与训练时不同,模型就会感到困惑。”
还有用户提到可以通过一些方法来改善模型的表现,比如“BalorNG”建议“使用多数投票可能会解决问题,尝试问同一个问题多次并统计结果”。
不过,也有不同的声音。“What_Do_It”认为“‘你移动装有香蕉的盘子到微波炉’这个表述缺乏清晰度,容易产生误解,如果表述为‘你移动位于香蕉上方的盘子到微波炉’,大多数模型可能就不会有问题”。
这场讨论揭示了模型推理过程中的复杂性和不确定性,也展示了大家对于提高模型性能的积极探索和思考。但如何找到最有效的方法,仍然是一个有待解决的问题。


感谢您的耐心阅读!来选个表情,或者留个评论吧!