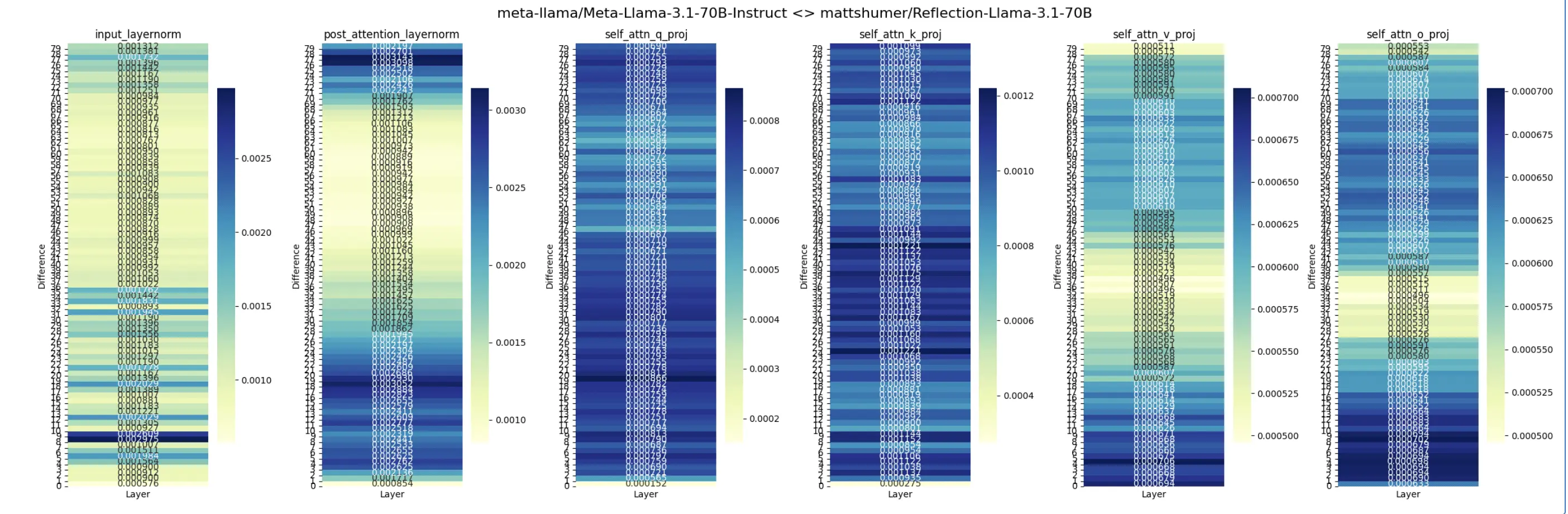
经过测量差异,这个模型似乎是应用了LoRA调优的Llama 3,而不是Llama 3.1。
作者甚至不知道他调优的是哪个模型。
我喜欢这个。
讨论总结
本次讨论主要围绕“Reflection-Llama-3.1-70B”模型的真实性展开,涉及多个技术细节和争议点。讨论的核心在于该模型是否实际上是Llama-3经过LoRA调优的版本,而非官方声称的Llama-3.1。参与者们通过技术分析、配置文件对比、性能测试等方式,试图验证模型的真实身份。讨论中还涉及到模型的性能提升、基准测试的公平性、以及技术炒作和真实性问题。整体氛围既有严谨的技术探讨,也有对模型作者专业性的质疑和幽默的调侃。
主要观点
👍 模型实际上是Llama-3经过LoRA调优
- 支持理由:通过热力图和配置文件分析,发现模型参数与Llama-3更为接近。
- 反对声音:部分评论者认为缺乏第三方验证,仍需进一步证据。
🔥 模型性能提升显著
- 正方观点:LoRA调优能够显著提升模型性能,尤其是在特定任务上。
- 反方观点:性能提升的真实性仍需验证,可能存在数据集污染等问题。
💡 基准测试的公平性问题
- 解释:讨论中提到基准测试可能存在不公平性,因为比较的是不同类型的模型。
💡 技术炒作与真实性问题
- 解释:部分评论者质疑模型的炒作是否合理,认为宣传主要来自开发者本人,缺乏第三方验证。
💡 配置文件的准确性
- 解释:配置文件的名称已经明确表明了该模型是Llama-3,而非Llama-3.1。
金句与有趣评论
“😂 Extract the lora so we don’t have to d/l fuckloads of gigs.”
- 亮点:幽默地表达了对于数据处理的需求。
“🤔 Isn’t it why it have only 8k context?”
- 亮点:提出了对模型性能的质疑,引发进一步讨论。
“👀 How did you get this diagram? Just curious.”
- 亮点:对技术细节的好奇心,推动了更多技术讨论。
“😂 I love it.”
- 亮点:幽默地表达了对模型作者的讽刺。
“🤔 If I was you, I’d switch jobs. The way you described it nobody in this setting knows what they’re doing.”
- 亮点:对模型开发团队的质疑,带有一定的幽默感。
情感分析
讨论的总体情感倾向较为复杂,既有对技术细节的严谨探讨,也有对模型作者专业性的质疑和幽默的调侃。主要分歧点在于模型的真实性和性能提升的真实性。可能的原因包括缺乏第三方验证、技术炒作的嫌疑以及配置文件的准确性问题。
趋势与预测
- 新兴话题:技术炒作与真实性问题的进一步讨论,以及LoRA调优在其他模型中的应用。
- 潜在影响:对模型开发者和研究者的诚信提出更高要求,推动更严格的第三方验证机制。
详细内容:
标题:关于 Reflection-Llama-3.1-70B 模型的热门讨论
在 Reddit 上,一张关于 Reflection-Llama-3.1-70B 模型的热力图引发了热烈讨论。该帖子包含了对模型参数差异的详细分析,获得了众多关注和大量评论。讨论主要围绕模型的真实版本、性能差异、训练方式等方面展开。
在讨论中,有人提出提取模型的 LoRA 以减少下载量。还有人分享了获取图表的链接,并介绍了自己使用 2TB 内存的机器来处理相关数据。对于模型性能的提升,看法不一。有人认为如果以特定方式衡量,性能提升幅度较大;但也有人认为基准测试存在问题,比如对不同模型应用了不同的系统提示。
有用户质疑模型最初获得大量关注的原因,认为是发布者的自我夸赞。也有人认为这种事件往往前期获得大量媒体关注,后期的质疑和揭露却鲜为人知。
关于模型是否为 Llama 3.1 以及其性能提升的真实性仍存在争议。有人指出 LoRA 训练方式能带来性能飞跃,但也有人对此表示怀疑。还有人怀疑模型权重出现问题的原因,认为发布者解释不清。
总的来说,Reddit 上关于 Reflection-Llama-3.1-70B 模型的讨论充满了质疑和争议,各方观点激烈交锋,模型的真实情况仍有待进一步明确。


感谢您的耐心阅读!来选个表情,或者留个评论吧!