讨论总结
本次讨论主要围绕Gemma-2-9b-it模型在LMSYS Arena排行榜上超越Llama-3-70b-it的现象展开。评论者们普遍认为,Gemma-2-9b-it之所以能够胜出,部分原因是其在风格投票上的优势,而非纯粹的模型能力。讨论中还涉及了Gemma模型的训练方式、Markdown文本的使用以及其在实际应用中的表现。总体而言,评论者们对Gemma模型的表现给予了肯定,但也指出了其在某些方面可能存在的不足。此外,讨论中还涉及了系统提示、模型整合、上下文长度等技术细节,以及对未来模型发展的期待。
主要观点
👍 Gemma-2-9b-it模型在排行榜上超越Llama-3-70b-it,主要是因为风格投票,而非模型能力。
- 支持理由:评论者普遍认为风格投票在排行榜上的影响较大。
- 反对声音:有评论指出Gemma模型在某些情况下可能不如更大参数的模型。
🔥 人类测试在衡量模型智能方面存在局限性。
- 正方观点:评论者认为人类测试无法全面衡量模型的智能。
- 反方观点:无明显反对声音,但有评论提到模型的“好坏”取决于具体的应用场景。
💡 新模型普遍使用结构化的Markdown文本,提高了响应的质量和实用性。
- 解释:评论中提到Markdown文本的使用提高了模型的响应质量。
🚀 Gemma模型的训练方式可能是其表现优异的原因之一。
- 解释:有评论提到Gemma模型的训练方式对其表现有积极影响。
🤔 在某些情况下,Gemma模型的响应可能不如更大参数的模型,如GPT-4o或Sonnet 3.5。
- 解释:评论中提到Gemma模型在某些特定场景下的表现可能不如其他大型模型。
金句与有趣评论
“😂 dubesor86:its really good for a 9B model, beating some 20B and even 34B models, but it overtaking a 70B such as Llama-3 is purely based on style votes, not capability.”
- 亮点:强调了风格投票在排行榜上的重要性。
“🤔 Unhappy_Project_3723:I see why many people say that human tests aren’t very good at measuring the intelligence of models.”
- 亮点:指出了人类测试在衡量模型智能方面的局限性。
“👀 lucyinada:The triple backtick notation for extended code blocks is supported by a large number of markdown processors, I seriously doubt Reddit is the only site using it.”
- 亮点:讨论了Markdown文本在模型响应中的应用。
“🤯 Finguili:In the end, which model is “better” depends on your specific use case.”
- 亮点:强调了模型优劣取决于具体应用场景。
“😎 KingFain:SimPO is the only example I’ve ever come across where I thought it was better than the original after trying it myself.”
- 亮点:表达了对SimPO技术的积极评价。
情感分析
讨论的总体情感倾向偏向积极,评论者们对Gemma-2-9b-it模型的表现给予了肯定,并对技术进步表示兴奋和期待。主要分歧点在于模型的实际应用效果和风格投票的影响,部分评论者认为Gemma模型在某些情况下可能不如更大参数的模型。
趋势与预测
- 新兴话题:模型微调和系统提示的使用可能会引发后续讨论。
- 潜在影响:Gemma-2-9b-it模型的成功可能会推动更多小型模型的微调研究,以及对系统提示和风格投票的深入探讨。
详细内容:
标题:Gemma-2-9b-it-SimPO 在 LMSYS Arena 排行榜上的表现引发热议
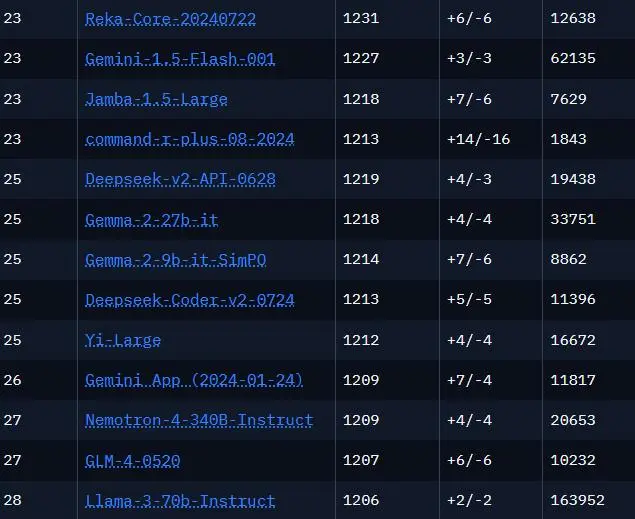
近日,Reddit 上一则关于“Gemma-2-9b-it-SimPO 在 LMSYS Arena 排行榜上超越 llama-3-70b-it”的帖子引发了众多网友的热烈讨论。该帖子获得了较高的关注度,评论数众多。
帖子主要探讨了 Gemma-2-9b-it-SimPO 在排行榜上取得出色成绩这一现象。引发的讨论方向包括模型性能的评估依据、与其他模型的对比、训练方式等。
文章将要探讨的核心问题是:Gemma-2-9b-it-SimPO 超越 llama-3-70b-it 的原因究竟是什么,以及如何客观评估模型的性能。
在讨论中,有人认为对于一个 9B 模型来说,Gemma-2-9b-it-SimPO 能击败一些 20B 甚至 34B 模型非常出色,但超越 llama-3-70b-it 更多是基于风格投票,而非实际能力。有人则表示,虽然人类测试在衡量模型智能方面可能不太完善,但新模型在响应上有诸多改进,如采用结构化的 Markdown 文本、突出主要论点等,这使得大家都从中受益。
还有用户指出,Gemma2 2B 和 9B 并非基于合成数据训练,而是从 Gemma2 27B 蒸馏而来。也有人认为,Gemma 在 lmsys 通用、风格控制等方面表现强劲,在较长查询类别中甚至做得更好。
同时,有人提出缺乏系统提示从安全角度看是可以理解的决定,但这确实让模型更难集成。有人经过测试,确定 Gemma 可以遵循系统提示。有人好奇“it-SimPO”的含义,得到解释“it”代表 instruct(为聊天而调整),并非 SimPO 的一部分,SimPO 指的是 Simple Preference Optimization with a Reference-Free Reward [https://arxiv.org/html/2405.14734v1] 。
讨论中的共识是,对于模型性能的评估需要综合考虑多个因素,不能单纯依据排行榜结果。特别有见地的观点是,不同模型在不同的使用场景中各有优势,最终哪个模型更好取决于具体的需求。
总之,关于 Gemma-2-9b-it-SimPO 在排行榜上的表现,Reddit 上的讨论呈现出多样化和深入化的特点,为我们理解模型性能和评估标准提供了丰富的视角。


感谢您的耐心阅读!来选个表情,或者留个评论吧!