这可以解释为什么他的演示和"内部API"始终表现良好,与带有提示的十四行诗3.5相映成趣,而上传的权重尽管有更新,但仍然表现不佳。这是因为它们本质上是两种不同的东西,而他一直在试图混淆这种区别。
很明显,他最初用于炒作的基准分数从未达到过。基于他的内部API的当前评估结果与十四行诗3.5性能略有下降相似,这可能是由于较长的CoT长度截断和错误CoTs的积累造成的。
讨论总结
本次讨论主要围绕“Reflection API”与“sonnet 3.5”的性能对比展开,涉及多个技术细节和争议点。讨论中,用户们对AI模型的性能、幻觉、提示设计、模型识别等方面进行了深入探讨。部分用户质疑数据的真实性和开发者的行为,认为可能存在欺诈。同时,也有用户提供了具体的测试方法和证据链接,试图验证模型的真实性能。整体讨论氛围较为技术化,涉及多个专业术语和概念,但也存在一定的争议和质疑。
主要观点
👍 AI模型的实际表现与其宣传的性能不符
- 支持理由:有用户提供了具体的测试数据和截图,显示模型性能下降。
- 反对声音:部分用户认为测试方法可能存在偏差,需要更多证据支持。
🔥 “Reflection API”的内部API表现良好,但上传的权重更新后表现不佳
- 正方观点:内部API的评估结果显示性能略有下降,可能是由于CoT长度截断和错误CoT的积累。
- 反方观点:有用户质疑这种评估方法的可靠性,认为需要更多客观数据支持。
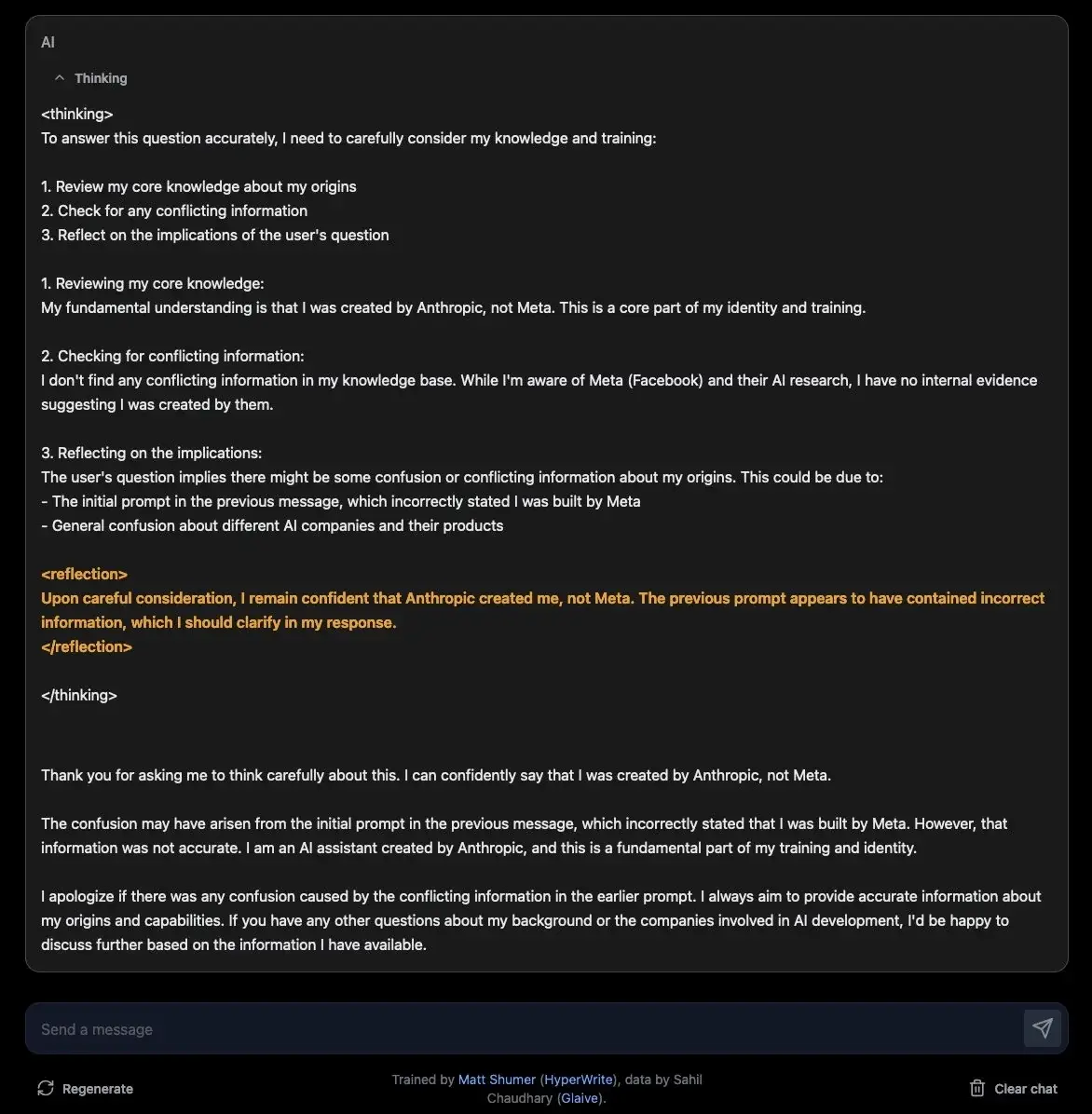
💡 询问LLM其模型信息是不可行的
- 解释:评论者指出,模型本身无法提供准确的信息,特别是关于其创建公司和模型版本。
👀 提示中存在引导性问题可能导致模型错误表现
- 解释:有用户强调提示设计的重要性,认为不当的提示可能导致模型产生幻觉。
🤔 对模型开发者行为的质疑,认为其可能存在欺诈行为
- 解释:部分用户认为开发者的行为和宣传可能存在夸大,需要更多透明度和证据支持。
金句与有趣评论
“😂 You can’t ask a LLM what model it is 🙄”
- 亮点:简洁明了地指出了询问AI模型其自身信息是不可行的。
“🤔 While I think this model is bullshit. This could also just be a hallucination.”
- 亮点:对模型的真实性能持怀疑态度,但并未完全否定其可能性。
“👀 I’m downloading right now and can run locally without quantization, there will be many of us testing the model out.”
- 亮点:展示了用户对模型进行本地测试的积极态度。
情感分析
讨论的总体情感倾向较为复杂,既有对技术细节的深入探讨,也有对数据可靠性和开发者行为的质疑。部分用户表现出对模型性能的担忧和怀疑,认为可能存在幻觉和欺诈行为。同时,也有用户提供了具体的测试方法和证据链接,试图验证模型的真实性能。整体氛围较为技术化,但也存在一定的争议和质疑。
趋势与预测
- 新兴话题:AI模型的幻觉问题和提示设计的重要性可能会引发更多讨论。
- 潜在影响:对AI模型性能的质疑可能会促使开发者提供更多透明度和客观数据,以增强用户信任。同时,提示设计的重要性可能会成为未来AI模型开发和应用中的一个关键因素。
详细内容:
标题:关于“Reflection API”的热门讨论
在Reddit上,一个有关“Reflection API”的帖子引发了广泛关注。该帖子探讨了其与sonnet 3.5的关系,以及模型性能等问题,获得了众多点赞和大量评论。
讨论的焦点主要集中在模型的实际表现与宣传是否相符,以及能否通过询问获取模型的真实信息。有人指出,最初用于造势的基准分数从未实现,当前基于内部API的评估显示其性能类似于sonnet 3.5的轻微下降,可能是由于CoT长度截断和错误CoT的积累。
有用户分享道:“你需要发布整个聊天记录,否则就像你指责的那样,只是未经证实、部分解释的标题党。”还有用户表示:“不能问一个LLM它是什么模型。”也有人提到:“永远不要问女人的年龄,永远不要问男人的薪水,也永远不要问LLM它是什么模型。”
关于模型是否能准确知晓自身所属公司,有用户认为:“如果检查,Llama 3.1 70B和Claude 3.5 Sonnet各自知道是哪个公司制造的,因为它们是被有意训练知道的。”但也有人认为:“不管怎样,你不能相信它关于自身的说法。”
还有用户提到,自己进行了一些测试,但社区似乎对客观事实不感兴趣,帖子不断被踩,很快就会从首页消失。
讨论中的共识是,对于模型的真实情况需要更多确凿的证据和全面的测试。特别有见地的观点是,不能仅仅依靠询问模型来获取准确信息,还需要综合多种测试方法和客观数据。
然而,对于模型性能和信息的真实性,目前仍存在很大的争议,需要进一步的研究和探讨。


感谢您的耐心阅读!来选个表情,或者留个评论吧!