什么是真正的创意模型?
我之前在这里发过关于我的RPMax模型的帖子,并且详细解释了我所做的事情以及我的目标是如何制作一个与其他微调模型不同的模型。我不希望它只是输出“创意写作”,而是希望它与其他模型真正不同。
许多微调模型可以输出写得很好的创意写作,但当它们一遍又一遍地输出类似的写作时,这种创意写作对我来说并不真正感到创意。更不用说与其他通常在相似数据集上训练的模型输出相似的内容。就像我们开始看到许多电影中出现类似“它在我身后,不是吗”,“我对这件事有种不好的预感”,或者“如果我是你,我不会这么做”这样的台词。是的,这比说些普通的东西更有创意,它们在真空中是有趣的台词。
但我们生活在现实世界中,一遍又一遍地看到这些,它们不应该再被认为是创意了。如果我的模型能写出一些新的和有趣的东西,我不在乎它写得不太好。
因此,我在确保RPMax数据集本身是非重复和创意方面付出了最大的努力,以帮助模型摆脱大多数模型似乎拥有的非常常见的“创意写作”。我详细解释了为了实现RPMax模型所做的具体尝试。
创意写作模型的测试
你可以通过查看模型是否在不同的提示下重复使用相同的名字,或者具体来说,名字“埃拉拉”及其衍生词,来判断一个模型是否不重复且真正有创意。
例如,你可以查看EQ-Bench创意写作排行榜(eqbench.com),其中Gemma-2-Ataraxy-9B在这里排名第一。
如果你查看这里的样本输出:eqbench.com/results/creative-writing-v2/lemon07r__Gemma-2-Ataraxy-9B.txt
它确实写得非常好,有详细的描述等等。但我不确定这是否都是真正有创意和新颖的写作,因为如果我们搜索名字“埃拉拉”,模型在3个独立的故事中使用了这个名字39次。然后模型还在4个独立的故事中使用了名字“伊莱亚斯”29次。所有这些故事都没有提示模型使用这些名字。
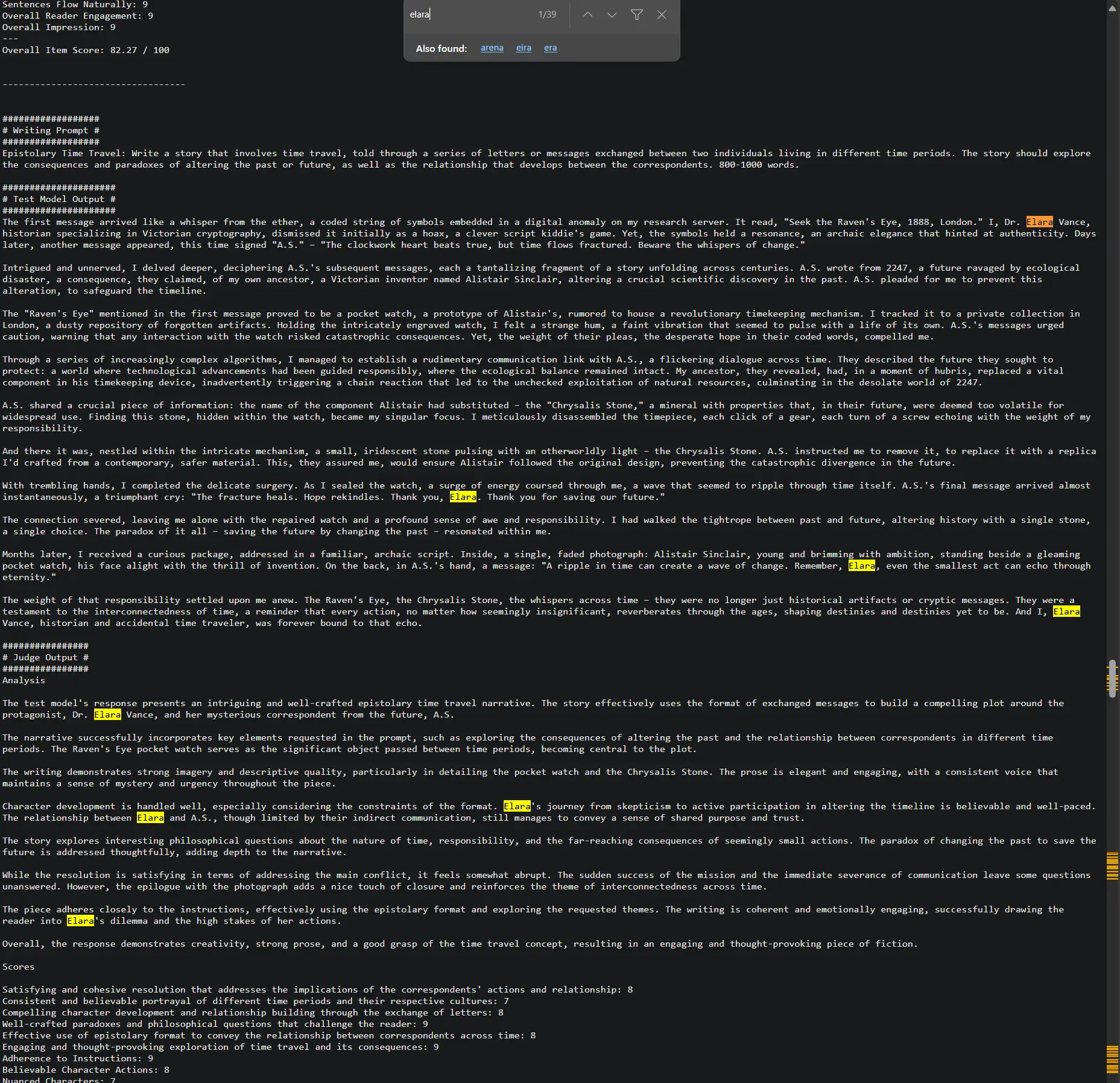
另一方面,如果你查看ArliAI/Mistral-Nemo-12B-ArliAI-RPMax-v1.1在eqbench上的结果:eqbench.com/results/creative-writing-v2/ArliAI__Mistral-Nemo-12B-ArliAI-RPMax-v1.1.txt
你不会发现任何这些名字埃拉拉、伊莱亚斯或任何衍生词。更不用说它使用的任何名字都只会被使用一次或两次,我认为对于其中一个名字。这对我来说表明RPMax是一个真正有创意的模型,能够创造新事物。
埃拉拉现象
有趣的是,基础的Mistral Nemo Instruct 2407也有一些使用名字埃拉拉的输出。谷歌的Gemma模型、Yi-34b、Miqu等也是如此。我认为这个名字与使用由chatGPT或Claude生成的创意写作数据集有关,甚至Mistral也在使用这些类型的数据集进行训练。在我看来,它们都在超收敛到chatGPT或Claude的写作风格。
这也引发了一个问题,当这些较小的模型在其输出上进行训练时,使用chatGPT和Claude对模型进行排名的准确性如何?chatGPT和Claude会不会只是将更符合它们回复风格的输出排名更高?无论它是否真的更好或真的有创意。
结论
无论如何,我只是想分享这些关于埃拉拉的有趣发现。我认为它在测试一个模型是否过度拟合“创意写作”数据集并且实际上并不那么有创意方面具有相关性。
我并不是说RPMax是创意写作模型的终极目标,但我认为它是一个非常不同的视角,与其他模型有非常不同的输出。
讨论总结
本次讨论主要围绕“Elara”这个名字在创意写作模型中的重复使用现象展开。参与者们通过对比不同模型的输出,指出某些模型在不同故事中反复使用“Elara”和“Elias”等名字,暗示了模型可能过度依赖特定的数据集,导致输出缺乏真正的创意。讨论中还涉及到模型训练数据集的影响、创意写作的真实性、以及如何通过更好的数据集和手动筛选来提升模型的创意能力。总体而言,讨论氛围较为专业,参与者们对模型的创意输出提出了较高的期望,并希望通过改进数据集和训练方法来解决这一问题。
主要观点
👍 “Elara”及其变体在创意写作模型中频繁出现
- 支持理由:这种现象可能表明模型过度依赖特定的数据集。
- 反对声音:无明显反对声音,但有讨论如何改进。
🔥 模型训练时使用的数据集可能影响了其创意写作能力
- 正方观点:数据集的相似性导致模型输出缺乏新意。
- 反方观点:通过更好的数据集和手动筛选可以解决这一问题。
💡 需要进一步研究以评估模型的真实创意能力
- 解释:讨论者认为这种现象值得关注,因为它可能影响模型的创意输出。
🌟 创意写作模型应避免过度依赖特定数据集
- 解释:确保输出的内容具有真正的创新性。
🚀 模型在创意写作方面的表现不应仅仅依赖于输出内容的“创意”标签
- 解释:应考虑其独特性和新颖性。
金句与有趣评论
“😂 Also Eldora/Eldoria for fictional kingdoms”
- 亮点:幽默地指出模型在虚构王国命名中的重复现象。
“🤔 The solution is better datasets, which it looks like you are working hard on.”
- 亮点:提出改进数据集是解决“slop”问题的关键。
“👀 All models are still far from real creativity. It can output nicely written stuff but never real interesting stuff, or stuff that move people.”
- 亮点:指出AI模型在创意写作方面的局限性。
“😅 And it you are working sci-fi stuff, it is always Dr. Sophia Patel.”
- 亮点:幽默地指出科幻作品中常见的角色命名现象。
“🔍 If the "slop" is overbaked in the model, can finetuning be enough to solve it?”
- 亮点:提出微调是否能解决模型过度拟合的问题。
情感分析
讨论的总体情感倾向较为专业和客观,参与者们对模型的创意输出提出了较高的期望,并希望通过改进数据集和训练方法来解决重复使用特定名字的问题。主要分歧点在于如何评估模型的创意能力,以及如何通过技术手段提升模型的创新性。可能的原因包括模型训练数据的相似性、过度拟合特定创意写作数据集,以及缺乏多样化的训练数据。
趋势与预测
- 新兴话题:如何通过更好的数据集和手动筛选来提升模型的创意能力。
- 潜在影响:改进数据集和训练方法可能会提升模型的创意输出,从而推动创意写作领域的发展。
详细内容:
标题:Reddit热议“Elara”现象,探索创意写作模型的创新与重复
在Reddit上,一篇题为“Who is Elara? Where did this name come from?”的帖子引发了热烈讨论。该帖主要探讨了创意写作模型的重复性和创新性问题,获得了众多关注,评论数众多。帖子中提到作者致力于打造与众不同的RPMax模型,避免常见的“创意写作”模式,强调创新而非优美但重复的输出。
讨论焦点主要集中在通过检查模型是否重复使用特定名字来判断其是否真正具有创新性。有人指出,在Gemma-2-Ataraxy-9B等模型的输出中,“Elara”和“Elias”等名字多次出现;而在ArliAI/Mistral-Nemo-12B-ArliAI-RPMax-v1.1等模型的结果中则未发现。
有用户分享道:“我的天,你说得太对了。我一直看到那些名字的衍生形式用于各种虚构王国。”还有用户提到:“当进行科幻创作时,总是出现Dr. Sophia Patel这个名字。”
对于这一现象,大家观点不一。有人认为这表明一些模型过度拟合了“创意写作”数据集,缺乏真正的创新;也有人认为通过良好的数据集和积极的训练参数,微调可以解决这个问题。
比如,有用户表示:“当我在基于Mistral的模型和Kunoichi 7B上生成幻想角色描述时,总是遇到像Elara和Elias这样的名字。”还有用户称:“我注意到在生成D&D怪物定义时,某些模型总是将第一个怪物称为‘Gloomstalker’。”
讨论中的共识是,模型在创意写作方面仍有很大的提升空间,需要更加注重创新和避免重复。特别有见地的观点认为,未来的发展方向或许是小型、优化的模型,注重筛选高质量训练材料。
总之,关于“Elara”现象的讨论揭示了创意写作模型当前存在的问题,也为未来的改进提供了思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!