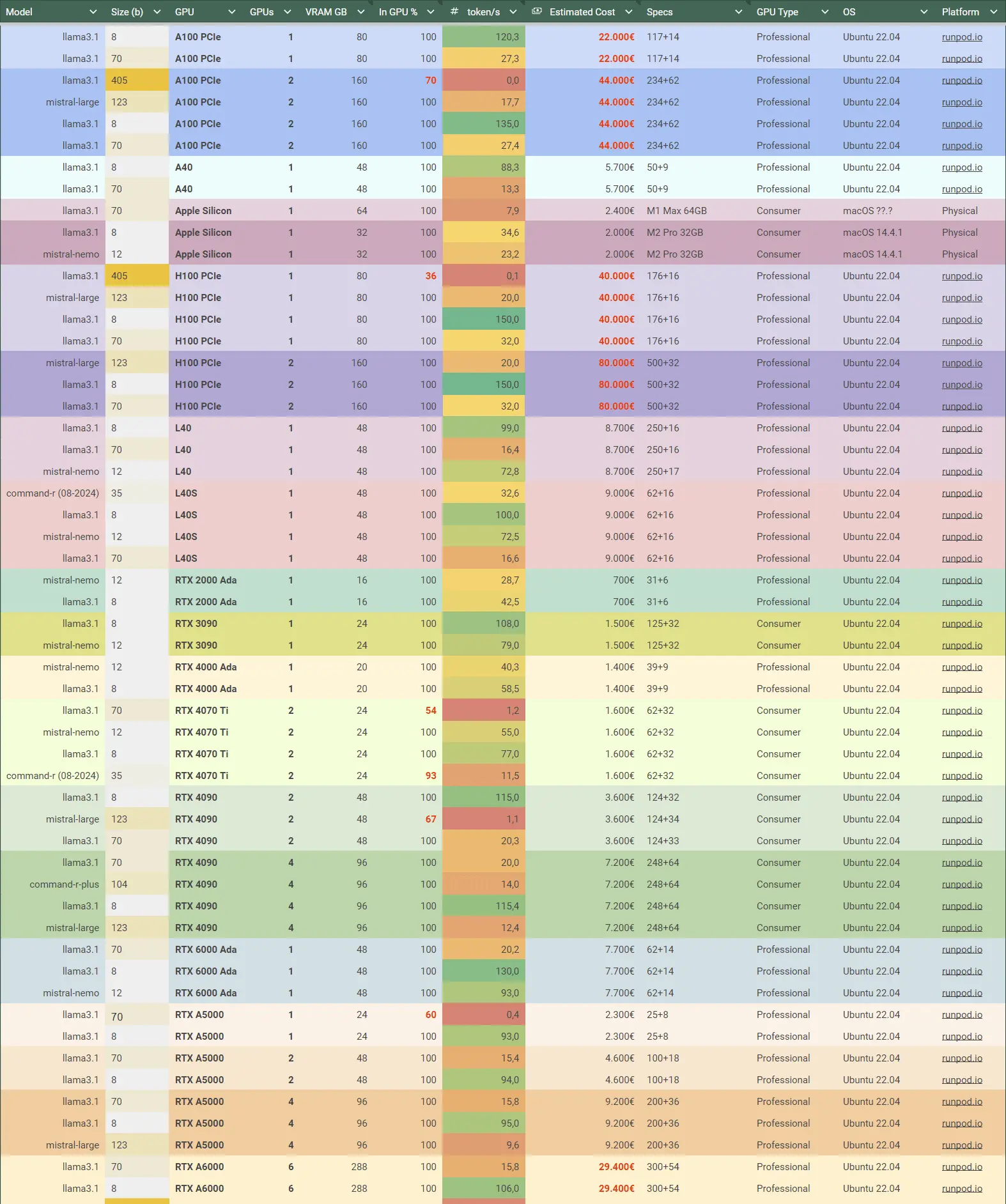
为了深入了解GPU和AI模型的性能,我在runpod.io上花费了30美元,并在那里对几个AI模型运行了Ollama。
请注意,这并不是一个学术性的LLM基准测试。相反,我想了解实际性能,并专注于Ollama的eval_rate(来自ollama run --verbose)。我认为这可能会引起你们中一些人的兴趣。
值得注意:
- 我对每个模型运行了几个问题,包括一些导致较长回答的问题。当然,eval_rate变化很大,所以我从3-4个回答中取了平均eval_rate。
- 此表中的模型选择相当小且不一致。我选择了我感兴趣的模型作为8b/70b等的基准。我发现这些数字可以很好地转移到其他模型或GPU上,例如…
- 不出所料,llama3.1:8b在2x和4x RTX4090上运行得几乎相同
- mistral-nemo:12b比lama3.1:8b慢约30%,command-r:35b比llama3.1:70b快约两倍,依此类推…
- 对于较小的模型,L40与L40S以及A5000与A6000之间没有太大差异
- 所有测试均使用Ollama 0.3.9进行
- 所有模型均从Ollama库中默认获取,这些模型为Q4(例如,llama3.1:8b为8b-instruct-q4_0)。
- 价格仅根据GPU计算,基于2024年9月德国的价格。我没有花太多时间寻找最优惠的价格
- runpod.io会根据所选GPU和GPU数量自动调整系统内存和vCPUs。很难判断这对基准测试的影响,但似乎影响不大
- 有些列标题可能一开始看起来不太有用。请查看单元格注释以获取更多信息。
我希望这对你有帮助,点击这里查看表格。
欢迎反馈。我很乐意根据你的输入扩展此表格。
讨论总结
本次讨论主要围绕在不同GPU上运行Ollama LLM的性能测试展开。作者分享了在runpod.io上进行的实验,重点关注了Ollama的eval_rate,并提供了详细的模型性能数据。讨论中涉及了不同模型的文件大小、所需的VRAM大小、量化版本的使用以及模型在不同GPU上的表现差异。此外,评论者们还讨论了上下文大小、响应大小对模型速度的影响,以及如何在成本和性能之间找到最佳平衡点。总体而言,讨论氛围较为技术性,主要集中在性能分析和成本效益上。
主要观点
👍 Ollama LLM在不同GPU上的性能表现
- 支持理由:作者提供了详细的性能数据,帮助用户了解不同GPU对模型性能的影响。
- 反对声音:部分用户认为测试中缺乏某些GPU型号的数据,如AMD MI300X。
🔥 量化版本的使用
- 正方观点:量化版本可以显著降低模型所需的VRAM,提高运行效率。
- 反方观点:有用户认为量化版本可能会影响模型的质量,建议使用Q8或fp16版本。
💡 上下文大小和响应大小对模型速度的影响
- 解释:上下文和响应大小显著影响模型的处理速度,特别是在高上下文时,速度会显著下降。
👍 性价比分析
- 支持理由:有用户建议增加成本和性能指标的计算,如每小时的成本、每秒每十亿参数的标记数,以评估最佳性价比。
- 反对声音:部分用户认为在不同模型之间比较性价比可能没有意义。
💡 提示评估速度的重要性
- 解释:提示评估速度对于构建有用的应用(如RAG、代理、对话等)至关重要,因为它影响预处理速度。
金句与有趣评论
“😂 No_Palpitation7740:nice work. Could you had a column "required VRAM" for each model? Did you use a quantized version?”
- 亮点:用户建议增加“所需VRAM”列,以便更清楚地了解每个模型的资源需求。
“🤔 SomeOddCodeGuy:Do you happen to know how much context you sent in and how big the responses were? GGUFs change speeds based on that.”
- 亮点:用户询问上下文和响应的具体大小,以进一步分析模型性能。
“👀 LockoutNex:No MI300X tested?”
- 亮点:用户对测试中未包含AMD MI300X表示疑问,引发了对测试中缺乏AMD GPU的讨论。
“😂 Orolol:Maybe you can include some calculations, like cost per hour, tokens per second per billion parameters (so we can evaluate which model/ GPU combo would give us the best value in term of speed / quality, even if parameters aren’t a real indicator of quality), etc..”
- 亮点:用户建议增加成本和性能指标的计算,以评估最佳性价比。
“🤔 mgr2019x:The prompt evaluation speed is crucial for all the things you do if you want to build something useful.”
- 亮点:用户强调提示评估速度在构建有用应用中的重要性。
情感分析
讨论的总体情感倾向较为积极,大部分用户对作者提供的性能数据表示赞赏,并提出了建设性的建议。主要分歧点在于量化版本的使用和性价比的评估,部分用户认为量化版本可能会影响模型质量,而另一些用户则认为性价比的比较在不同模型之间没有意义。这些分歧可能源于用户对模型性能和成本的不同关注点。
趋势与预测
- 新兴话题:可能会有更多关于AMD GPU在AI模型性能上的讨论,特别是随着AMD MI300X等新GPU的推出。
- 潜在影响:随着AI模型的不断发展,对GPU性能和成本效益的讨论将更加深入,可能会推动GPU厂商在性能和成本上的优化。
详细内容:
标题:Ollama LLM 在不同 GPU 上的性能基准测试引发 Reddit 热议
近日,Reddit 上一篇关于 Ollama LLM 在不同 GPU 上的性能基准测试的帖子引发了众多关注。该帖子作者在 runpod.io 上花费 30 美元对 Ollama 与一些 AI 模型进行了测试,并分享了详细的测试结果。帖子获得了大量的点赞和众多评论。
主要的讨论方向包括对测试模型的具体分析、对测试方式的建议和补充,以及对不同 GPU 性能表现的看法。文章将要探讨的核心问题是如何更全面准确地评估不同 GPU 与 Ollama LLM 组合的性能。
在讨论中,有人称赞作者的工作出色,并建议增加“所需 VRAM”列,还有人分享自己不使用 Q4 而是 Q8 或 fp16 的情况。有人认为作者对不同模型比较的详细拆解很有价值,尤其是对特定使用场景下模型选择有帮助。也有人希望作者能添加如 Tesla V100 等较旧的 GPU 型号。
有人询问测试中的上下文和响应大小,作者回应称会先通过一些闲聊预热模型,比如问候和询问状况,而导致模型产生较大响应的问题通常是“为什么天空是蓝色的?”,所有模型对此的回答在 300 到 500 个 tokens 之间。
有人提到不同品牌 GPU 混合使用的情况,也有人指出如果多人共享单个 GPU 实例,可能无法获得如 H100 那样的完整性能。还有人对没有测试 AMD 的 MI300X 提出疑问,作者表示测试时出现错误。有人建议加入成本、每秒 tokens 与参数数量等相关计算。也有人强调了 prompt 评估速度和预填充速度的重要性。
总的来说,这次的讨论展示了大家对 GPU 与 AI 模型性能评估的深入思考和关注,为相关领域的研究和应用提供了有价值的参考和思路。


感谢您的耐心阅读!来选个表情,或者留个评论吧!