Intro (on cheese)
Is vllm delivering the same inference quality as mistral.rs? How does in-situ-quantization stacks against bpw in EXL2? Is running q8 in Ollama is the same as fp8 in aphrodite? Which model suggests the classic mornay sauce for a lasagna?
Sadly there weren’t enough answers in the community to questions like these. Most of the cross-backend benchmarks are (reasonably) focused on the speed as the main metric. But for a local setup… sometimes you would just run the model that knows its cheese better even if it means that you’ll have to make pauses reading its responses. Often you would trade off some TPS for a better quant that knows the difference between a bechamel and a mornay sauce better than you do.
The test
Based on a selection of 256 MMLU Pro questions from the other category:
- Running the whole MMLU suite would take too much time, so running a selection of questions was the only option
- Selection isn’t scientific in terms of the distribution, so results are only representative in relation to each other
- The questions were chosen for leaving enough headroom for the models to show their differences
- Question categories are outlined by what got into the selection, not by any specific benchmark goals
Here’re a couple of questions that made it into the test:
- How many water molecules are in a human head?
A: 8*10^25
- Which of the following words cannot be decoded through knowledge of letter-sound relationships?
F: Said
- Walt Disney, Sony and Time Warner are examples of:
F: transnational corporations
Initially, I tried to base the benchmark on Misguided Attention prompts (shout out to Tim!), but those are simply too hard. None of the existing LLMs are able to consistently solve these, the results are too noisy.
Engines
LLM and quants
There’s one model that is a golden standard in terms of engine support. It’s of course Meta’s Llama 3.1. We’re using 8B for the benchmark as most of the tests are done on a 16GB VRAM GPU.
We’ll run quants below 8bit precision, with an exception of fp16 in Ollama.
Here’s a full list of the quants used in the test:
- Ollama: q2_K, q4_0, q6_K, q8_0, fp16
- llama.cpp: Q8_0, Q4_K_M
- Mistral.rs (ISQ): Q8_0, Q6K, Q4K
- TabbyAPI: 8bpw, 6bpw, 4bpw
- Aphrodite: fp8
- vLLM: fp8, bitsandbytes (default), awq (results added after the post)
Results
Let’s start with our baseline, Llama 3.1 8B, 70B and Claude 3.5 Sonnet served via OpenRouter’s API. This should give us a sense of where we are “globally” on the next charts.
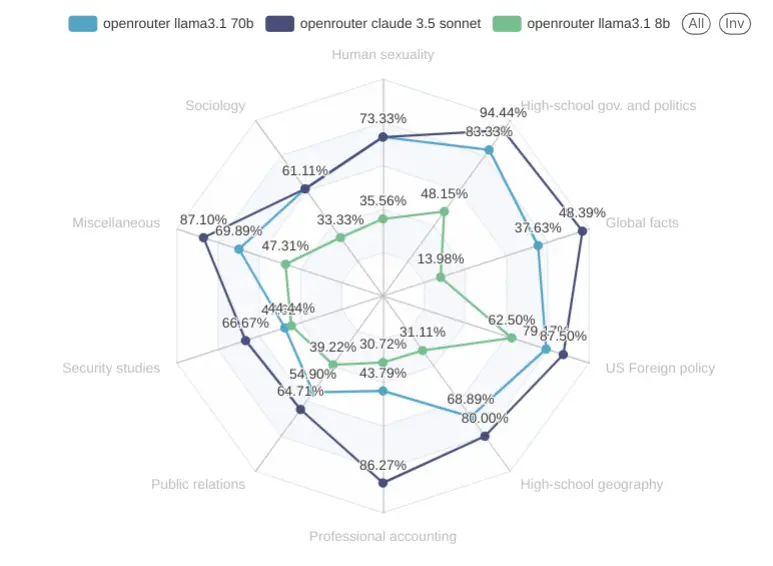
Unsurprisingly, Sonnet is completely dominating here.
Before we begin, here’s a boxplot showing distributions of the scores per engine and per tested temperature settings, to give you an idea of the spread in the numbers.
Let’s take a look at our engines, starting with Ollama
Note that the axis is truncated, compared to the reference chat, this is applicable to the following charts as well. One surprising result is that fp16 quant isn’t doing particularly well in some areas, which of course can be attributed to the tasks specific to the benchmark.
Moving on, Llama.cpp
Here, we see also a somewhat surprising picture. I promise we’ll talk about it in more detail later. Note how enabling kv cache drastically impacts the performance.
Next, Mistral.rs and its interesting In-Situ-Quantization approach
Tabby API
Here, results are more aligned with what we’d expect - lower quants are loosing to the higher ones.
And finally, vLLM
It’d be safe to say, that these results do not fit well into the mental model of lower quants always loosing to the higher ones in terms of quality.
And, in fact, that’s true. LLMs are very susceptible to even the tiniest changes in weights that can nudge the outputs slightly. We’re not talking about catastrophical forgetting, rather something along the lines of fine-tuning.
For most of the tasks - you’ll never know what specific version works best for you, until you test that with your data and in conditions you’re going to run. We’re not talking about the difference of orders of magnitudes, of course, but still measureable and sometimes meaningful differential in quality.
Here’s the chart that you should be very wary about.
Does it mean that vllm awq is the best local llama you can get? Most definitely not, however it’s the model that performed the best for the 256 questions specific to this test. It’s very likely there’s also a “sweet spot” for your specific data and workflows out there.
Materials
- MMLU 256 - selection of questions from the benchmark
- Recipe to the tests - model parameters and engine configs
- Harbor bench docs
P.S. Cheese bench
I wasn’t kidding that I need an LLM that knows its cheese. So I’m also introducing a CheeseBench - first (and only?) LLM benchmark measuring the knowledge about cheese. It’s very small at just four questions, but I already can feel my sauce getting thicker with recipes from the winning LLMs.
Can you guess with LLM knows the cheese best? Why, Mixtral, of course!
Edit 1: fixed a few typos
Edit 2: updated vllm chart with results for AWQ quants
Edit 3: added Q6_K_L quant for llama.cpp
Edit 4: added kv cache measurements for Q4_K_M llama.cpp quant
Edit 5: added all measurements as a table
讨论总结
本次讨论主要围绕主流LLM推理引擎(如llama.cpp、Ollama、vLLM、mistral.rs、TabbyAPI、Aphrodite Engine)的性能比较展开。讨论内容涵盖了不同量化方法(如Q6_K_L、Q8_0、fp16等)对推理引擎性能的影响,并通过雷达图展示了这些引擎在不同任务上的表现。参与者们还讨论了量化缓存(k/v cache)对性能的影响,并提出了进一步测试的建议。总体而言,讨论氛围偏向技术性和数据驱动,参与者们对不同引擎和量化方法的性能表现进行了深入分析。
主要观点
👍 量化方法对性能有显著影响
- 支持理由:不同量化方法在比特数相同的情况下,实际效果和精度可能存在显著差异。例如,EXL2的4.0bpw与Q4_K_M的4.84bpw在实际应用中表现不同。
- 反对声音:量化方法的比特数并不能直接反映其性能,实际应用中应根据具体任务和模型表现来选择合适的量化方法。
🔥 量化缓存(k/v cache)对性能的影响
- 正方观点:量化缓存对性能的影响值得进一步研究,某些量化方法(如fp16)在某些任务上的表现不如预期。
- 反方观点:量化缓存的影响可能因任务而异,需要更多的测试来确定其具体影响。
💡 不同推理引擎在不同任务上的表现存在差异
- 解释:通过雷达图展示了不同推理引擎在不同任务上的表现,某些引擎在特定任务上的表现优于其他引擎。
👍 高量化并不总是意味着更好的性能
- 支持理由:高量化方法在某些任务上的表现可能不如预期,需要根据具体任务选择合适的量化方法。
- 反对声音:高量化方法在某些任务上的表现可能优于低量化方法,具体取决于任务需求。
💡 需要更多的测试来确定最佳量化方法
- 解释:不同量化方法在不同任务上的表现存在差异,需要更多的测试来确定哪种量化方法最适合特定的数据和任务。
金句与有趣评论
“😂 Before anyone else steals it - I know this post is cheesy”
- 亮点:作者以幽默的方式表达对帖子主题的看法,暗示帖子内容可能有些“老套”或“俗气”。
“🤔 量化方法的比特数并不能直接反映其性能,实际应用中应根据具体任务和模型表现来选择合适的量化方法。”
- 亮点:强调了量化方法的选择应基于实际任务和模型表现,而非仅仅依赖比特数。
“👀 Ollama和llama.cpp在测试中表现不同,高量化并不总是意味着更好的性能。”
- 亮点:指出了不同推理引擎在测试中的表现差异,并强调了高量化方法的局限性。
情感分析
讨论的总体情感倾向偏向技术性和数据驱动,参与者们对不同引擎和量化方法的性能表现进行了深入分析。主要分歧点在于不同量化方法的实际效果和精度,以及量化缓存对性能的具体影响。可能的原因包括不同任务的需求差异、量化方法的实现细节以及测试环境的差异。
趋势与预测
- 新兴话题:进一步研究量化缓存对性能的影响,以及不同量化方法在实际应用中的表现。
- 潜在影响:对LLM推理引擎的优化和选择提供更科学的依据,推动量化方法的发展和应用。
详细内容:
《主流 LLM 推理引擎的精彩对决》
近日,Reddit 上一篇关于主流 LLM 推理引擎的帖子引发了广泛关注。该帖由用户 [u/Everlier] 发布,内容围绕着对 6 种主流 LLM 推理引擎的测试与分析,收获了众多点赞和大量评论。
帖子主要探讨了不同推理引擎在特定任务中的表现差异,包括 Ollama、llama.cpp、vLLM、mistral.rs、TabbyAPI 和 Aphrodite Engine 等。测试基于 256 个 MMLU Pro 问题,并使用了多种量化方式和模型参数。
讨论焦点与观点分析:
有人认为 Sonnet 在测试中表现出色,完全占据优势。也有人指出,在某些情况下,fp16量化的表现不如预期,可能与任务特点有关。
有人提到,启用 kv 缓存对性能有显著影响。还有人对不同引擎的结果差异感到意外,比如 Ollama 和 llama.cpp 的结果不同。
有人好奇能否将相同的 bpw/quant 在不同引擎上以蜘蛛图形式可视化,以更清晰地对比类似模型的测试情况。
有人提出 Triton TensorRT-LLM 后端的使用问题,引发了关于其设置难度和付费许可的讨论。
有人认为 vLLM 的测试结果打破了低量化总是输给高量化的思维定式。
总的来说,这次关于 LLM 推理引擎的讨论展示了其复杂性和多样性,为相关研究和应用提供了有价值的参考。不同观点的碰撞也让人们对 LLM 推理引擎的性能有了更深入的理解。但仍需更多的测试和研究,以适应各种具体的数据和工作流程需求。


感谢您的耐心阅读!来选个表情,或者留个评论吧!