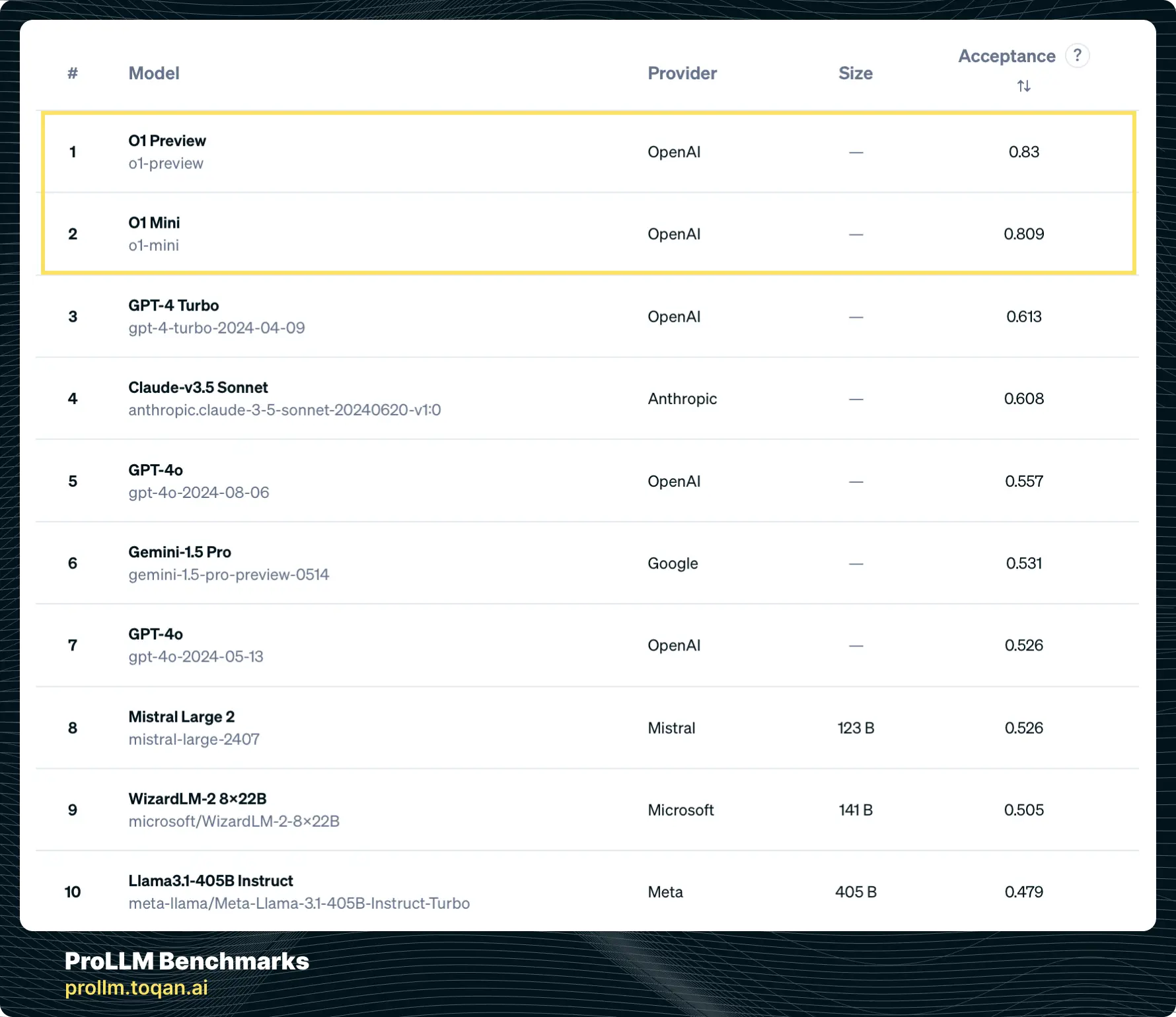
我们在 StackUnseen 基准测试中对新的 OpenAI O1-Preview 和 O1-Mini 模型进行了基准测试,并观察到与之前的最佳 SOTA 相比,性能提升了 20%。我们将在其他基准测试中进行更深入的分析,以了解该模型的优势。请继续关注更全面的评估。在此之前,欢迎查看排行榜:https://prollm.toqan.ai/leaderboard/stack-unseen
讨论总结
本次讨论主要围绕OpenAI的新模型O1在ProLLM StackUnseen Benchmark上的表现展开。评论者们对O1模型的性能提升表示关注,并深入探讨了模型评估的方法和潜在问题。讨论中涉及了使用GPT-4 Turbo进行自动评估的合理性、评估样本可能存在的污染问题、LLM作为评估者的可行性,以及如何确保评估的准确性和公正性。此外,评论还涉及了O1模型在编程竞赛中的表现,以及其是否能替代初级开发者的问题。总体而言,讨论氛围技术性强,评论者们对O1的潜力表示肯定,但也对其可能带来的职业影响表示担忧。
主要观点
👍 O1模型在ProLLM StackUnseen Benchmark上表现优异,超越了之前的SOTA模型。
- 支持理由:数据和基准测试结果显示O1模型的性能提升了20%。
- 反对声音:有评论者质疑“100倍更强大”与20%性能提升之间的逻辑关系。
🔥 使用GPT-4 Turbo进行自动评估可能存在问题,因为该模型性能不如O1。
- 正方观点:自动评估的准确性受到评估模型自身性能的限制。
- 反方观点:有人提出使用人类专家进行评估,以确保评估的公正性和准确性。
💡 O1的链式思维能力通过强化学习得到了显著提升。
- 解释:评论者提到O1的链式思维能力在编程竞赛中表现出色,达到了89百分位。
👀 O1的性能提升可能使其成为“创业杀手”,对初级开发者构成威胁。
- 解释:评论者认为O1的智能已经超越了许多人类,尤其是在编程领域。
🤔 评估样本可能存在污染问题,特别是样本来自今年春季。
- 解释:评论者讨论了评估样本的来源和可能的污染问题,影响评估的准确性。
金句与有趣评论
“😂 Homeschooled316:Kind of funny that the auto evaluation is now being done by a worse model than the top scorer.”
- 亮点:讽刺性地指出了自动评估模型性能不如被评估模型的尴尬情况。
“🤔 ResidentPositive4122:So … who judges the judge that judges the judge? :D”
- 亮点:幽默地提出了评估过程中的循环依赖问题,引发思考。
“👀 chemistrycomputerguy:89th percentile in codeforces is insane”
- 亮点:强调了O1模型在编程竞赛中的惊人表现。
“😂 Mr_Nice_:so 100x more powerful = 20% improvement”
- 亮点:讽刺性地质疑了官方宣称的“100倍更强大”与实际20%性能提升之间的逻辑关系。
“🤔 Next_Program90:Because they are finally allowing inner thought processes / reasoning that’s not out in the open.”
- 亮点:提出了O1模型性能提升可能是因为允许内部思维过程和推理,引发了对技术细节的讨论。
情感分析
讨论的总体情感倾向偏向于技术性和信息性,评论者们对O1模型的性能提升表示肯定,但也对其可能带来的职业影响表示担忧。主要分歧点在于模型评估的方法和准确性,以及O1模型是否能替代初级开发者的问题。可能的原因包括技术细节的复杂性和对未来职业影响的担忧。
趋势与预测
- 新兴话题:O1模型的内部思维过程和推理机制可能成为后续讨论的热点。
- 潜在影响:O1模型的发布可能会促使其他公司如Meta和Mistral加快研发步伐,同时也可能引发对AI模型评估方法和职业影响的进一步探讨。
详细内容:
标题:OpenAI O1 模型在基准测试中表现出色,引发 Reddit 热议
近日,Reddit 上一则关于 OpenAI O1 模型在 ProLLM StackUnseen 基准测试中性能大幅提升的帖子引起了广泛关注。该帖子指出,新的 OpenAI O1-Preview 和 O1-Mini 模型在测试中相比以往最先进的模型性能提升了 20%,并附上了相关的表格和详细信息,获得了众多点赞和大量评论。
讨论的焦点主要集中在以下几个方面: 有人认为自动评估由不如顶级模型的模型来进行有些滑稽甚至是错误的。也有人指出,虽然这是一个进步,但仍存在一些问题,比如知识截止时间以及可能的评估偏差。 对于模型的性能提升,有人认为这是巨大的突破,比如在代码forces 中表现出色,甚至比大多数活人都聪明。但也有人持谨慎态度,等待热潮过去再做判断。还有人担忧这是否意味着初级开发者会被取代。 关于模型的训练和改进,有人认为其不仅改进了思维链能力,还可能通过生成大量候选响应并选择,或迭代优化答案等方式提升性能。
有人分享道:“作为一名在 AI 领域研究多年的学者,我深知模型的性能提升并非一蹴而就。这次 O1 模型的突破虽然令人瞩目,但还需要更多实际应用和时间的检验。” 有人提供了相关的研究链接:https://arxiv.org/abs/2407.16557 ,进一步支持了关于模型评估的观点。
讨论中的共识在于大家都认可 O1 模型的性能提升是显著的,但对于其未来的影响和实际应用效果还存在不同看法。
特别有见地的观点如:有人认为虽然模型强大,但它仍然只是一个数字矩阵,不能完全替代人类的思考和经验。这一观点提醒我们在看待 AI 技术发展时要保持理性和客观。
这场关于 OpenAI O1 模型的讨论反映了人们对 AI 技术快速发展的关注和思考,也让我们更加期待未来 AI 技术在各个领域的应用和发展。


感谢您的耐心阅读!来选个表情,或者留个评论吧!