Creating an RP dataset often boils down to how many Claude credits you can throw at the problem. And I’m not aware of any open-sourced pipelines for doing it, even if you DO have the credits. So I made an open-source RP datagen pipeline. The idea is that this pipeline creates RP sessions with the themes and inspiration of the stories you feed in — so if you fed in Lord of the Rings, you’d get out a bunch of High Fantasy roleplays.
This pipeline is optimized for working with local models, too — I made a dataset of around 1000 RP sessions using a mixture of Llama 3 70b and Mistral Large 2, and it’s open-sourced as well!
The Links
The pipeline (the new pipeline has been added as a new pipeline on top of the existing Augmentoolkit project)
The Details
RPToolkit is the answer to people who have always wanted to train AI models on their favorite genre or stories. This pipeline creates varied, rich, detailed, multi-turn roleplaying data based on the themes, genre, and emotional content of input stories. You can configure the kind of data you generate through the settings or, better still, by changing the input data you supply to the pipeline. Prompts can be customized without editing code, just YAML files.
Handy flowchart for the visual learners:
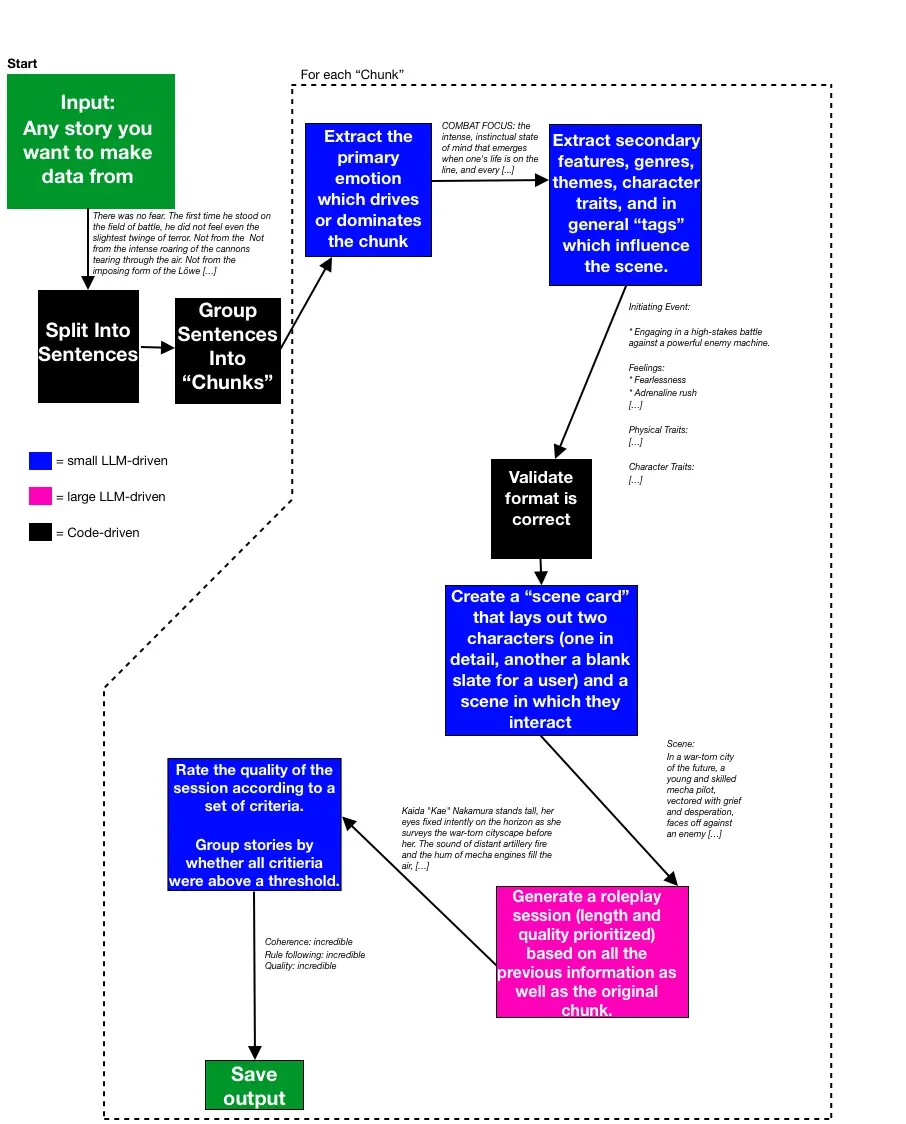
You can run it with a Python script or a GUI (streamlit). Simply add text files to the input folder to use them as inputs to the pipeline.
Any OpenAI compatible API (Llama.cpp, Aphrodite, Together, Fireworks, Groq, etc…) is supported. And Cohere, too.
The writing quality and length of the final data in this pipeline is enhanced through a painstakingly-crafted 22-thousand-token prompt.
The Problem it Solves
While a pipeline to make domain experts on specific facts does exist, when many people think about training an AI on books, they think of fiction instead of facts. Why shouldn’t they? Living out stories is awesome, AI’s well-suited to it, and even if you are a complete cynic, AI RP is still in-demand enough to be respected. But while there are a huge number of good RP models out there, the difficulty of data means that people usually rely on filtering or combining existing sets, hyperparameter tricks, and/or merging to get improvements. Data is so hard for hobbyists to make, and so it sees, arguably, the least iteration.
Back when I first released Augmentoolkit (originally focused on creating factual QA datasets for training domain experts) I made this flowchart:
I think that Augmentoolkit’s QA pipeline has eased the problem when it comes to domain experts, but the problem is still very real for RP model creators. Until (hopefully) today.
Now you can just add your files and run a script.
With RPToolkit, you can not only make RP data, but you can make it suit any tastes imaginable. Want wholesome slice of life? You can make it. Want depressing, cutthroat war drama? You can make it. Just feed in stories that have the content you want, and use a model that is not annoyingly happy to do the generation (this last bit is honestly the most difficult, but very much not insurmountable).
You can make a model specializing in your favorite genre, and on the other hand, you can also create highly varied data to train a true RP expert. In this way, RPToolkit tries to be useful to both hobbyists making things for their own tastes, and *advanced* hobbyists looking to push the SOTA of AI RP. The pipeline can roughly go as wide or as narrow as you need, depending on the data you feed it.
Also, since RPToolkit doesn’t directly quote the input data in its outputs, it probably avoids any copyright problems, in case that becomes an issue down the line for us model creators.
All in all I think that this pipeline fulfills a great need: everyone has some genres, themes, or emotions in entertainment that truly speaks to their soul. Now you can make data with those themes, and you can do it at scale, and share it easily, which hopefully will raise the bar (and increase the personalization) of AI RP a bit more.
That all being said, I’m not the type to promise the world with a new thing, without honestly admitting to the flaws that exist (unlike some other people behind a synthetic data thing who recently made a model announcement but turned out to be lying about the whole thing and using Claude in their API). So, here are the flaws of this early version, as well as some quirks:
Flaws
Flaws:
1. Lack of darkness and misery: the degree to which stories will be lighthearted and cheerful partly depends on the model you use to generate data. For all its smarts, Llama can be… annoyingly happy, sometimes. I don’t know of any gloriously-unhinged high-context good-instruction-following models, which is proabably what would be best at making data with this. If someone recommends me one in the 70b–130b range I’ll see if I can make a new dataset using it. I tried Magnum 70b but its instruction following wasn’t quite good enough and it got incoherent at long contexts. Mistral 123b seemed to acceptably be able to do violent and bleak stories — showing the source chunk during the story generation step helped a lot with this (INCLUDE_CHUNK_IN_PROMPT: True in the config). However, I need to find a model that can really LEAN into an emotion of a story even if that emotion isn’t sunflowers and rainbows. Please recommend me psychopath models. To address this I make make an update with some prompt overrides based in horribly dark, psychological stories as few-shot examples, to really knock the LLM into a different mindset — problem is not many gutenberg books get that visceral, and everything else I’d like to use is copyrighted. Maybe this is more noticed since I really like dark stories — I tried to darken things a bit by making the few-shot example based on Romance of the Three Kingdoms a gruesome war RP, but it seems I need something truly inhuman to get this AI to be stygian enough for my tastes. NOTE: Min P, which Augmentoolkit supports now, seems to alleviate this problem to some extent? Or at least it writes better, I haven’t had the time to test how min_p affects dark stories specifically.
- The story generation prompt is a true masterwork if I do say so myself: 22,000 tokens of handwritten text painstakingly crafted over 3 days… which can make it relatively expensive to runI have a detailed walkthrough help video showing that process). Or use a model like Llama 3 70b with really good settings such as min p: 2/3rds of the demo dataset I shared was generated purely by llama 3 70b via an API, the other third used llama for the easier steps then Mistral 123b with min_p on Aphrodite.
I think I’m doing something wrong with my local inference that’s causing it to be much slower than it should be. Even if I rent 2x H100s on Runpod and run Aphrodite on them, the speed (even for individual requests) is far below what I get on a service like Fireworks or Together, which are presumably using the same hardware. If I could fix the speed of local generation then I could confidently say that cost is solved (I would really appreciate advice here if you know something) but until then the best options are either to rent cheap compute like A40s and wait, or use an API with a cheaper model like Llama 3 70b. Currently I’m quantizing the k/v cache and running with -tp 2, and I am using flash attention — is there anything else that I have to do to make it really efficient?
3. NSFW. This pipeline can do it? But it’s very much not specialized in it, so it can come off as somewhat generic (and sometimes too happy, depending on the model). This more generalist pipeline focused on stories in general was adapted from an NSFW pipeline I built for a friend and potential business partner back in February. They never ended up using it, and I’ve been doing factual and stylistic finetuning for clients since so I haven’t touched the NSFW pipeline either. Problem is, I’m in talks with a company right now about selling them some outputs from that thing, and we’ve already invested a lot of time into discussions around this so I’d feel guilty spinning on a dime and blasting it to the world. Also, I’m legitimately not sure how to release the NSFW pipeline without risking reputational damage, since the prompts needed to convice the LLM to gratuitiously describe sexual acts are just that cursed (the 22-thousand token prompt written for this project… was not the first of its kind). Lots of people who release stuff like this do it under an anonymous account but people already know my name and it’s linked with Augmentoolkit so that’s not an option. Not really sure what to do here, advice appreciated. Keeping in mind I do have to feed myself and buy API credits to fund development somehow.
4. Smart models work really well! And the inverse is true. Especially with story generation, the model needs: high context, good writing ability, good instruction following ability, and flexible morals. These are tough to find in one model! Command R+ does an OK job but is prone to endless repetition once contexts get long. Llama 3 400b stays coherent but is, in my opinion, maybe a bit too happy (also it’s way too big). Llama 3 70b works and is cheaper but is similarly too happy. Mistral 123b is alright, and is especially good with min_p; it does break more often, but validation catches and regenerates these failures. Still though, I want it to be darker and more depressing. And to write longer. Thinking of adding a negative length penalty to solve this — after all, this is only the first release of the pipeline, it’s going to get better.
This is model-dependent, but sometimes the last message of stories is a bit too obviously a conclusion. It might be worth it to remove the last message of every session so that the model does not get in the habit of writing endings, but instead always continues the action.
It can be slow if generating locally.
FAQ:
“How fast is it to run?”
Obviously this depends on the number of stories and the compute you use, as well as the inference engine. For any serious task, use the Aphrodite Engine by the illustrious Alpin Dale and Pygmalion, or a cheap API. If you’re impatient you can use worse models, I will warn though that the quality of the final story really relies on some of the earlier steps, especially scene card generation.
“What texts did you use for the dataset?”
A bunch of random things off of Gutenberg, focusing on myths etc; some scraped stuff from a site hosting a bunch of light novels and web novels; and some non-fiction books that got accidentally added along with the gutenberg text, but still somehow worked out decently well (I saw at least one chunk from a cooking book, and another from an etiquette book).
“Where’s all the validation? I thought Augmentoolkit-style pipelines were supposed to have a lot of that…”
They are, and this actually does. Every step relies on a strict output format that a model going off the rails will usually fail to meet, and code catches this. Also, there’s a harsh rating prompt at the end that usually catches things which aren’t of the top quality.
“Whoa whoa whoa, what’d you do to the Augmentoolkit repo?! THE ENTIRE THING LOOKS DIFFERENT?!”
😅 yeah. Augmentoolkit 2.0 is out! I already wrote a ton of words about this in the README, but basically Augmentoolkit has a serious vision now. It’s not just one pipeline anymore — it can support any number of pipelines and also lets you chain their executions. Instead of being “go here to make QA datasets for domain experts” it’s now “go here to make datasets for any purpose, and maybe contribute your own pipelines to help the community!” This has been in the works for like a month or two.
I’m trying to make something like Axolotl but for datagen — a powerful, easy-to-use pillar that the open LLM training community can rely on, as they experiment with a key area of the process. If Augmentoolkit can be such a pillar, as well as a stable, open, MIT-licensed base for the community to *add to* as it learns more, then I think we can make something truly awesome. Hopefully some more people will join this journey to make LLM data fun, not problematic.
A note that *add to* is key – I tried to make pipelines as modular as possible (you can swap their settings and prompts in and out) and pipelines themselves can be chosen between now, too. There’s also a boilerplate pipeline with all the conventions set up already, to get you started if you want to build and contribute your own datagen pipeline to Augmentoolkit, to expand the capabilities of what kinds of data the open source community can make.
“I tried it and something broke!”
Damnation! Curses! Rats! OK, so, I tried to test this extensively, I ran all the pipelines with a bunch of different settings on macos and linux both, but yeah I likely have missed some things, since I rewrote about half the code in the Augmentoolkit project. Please create an issue on GitHub and we can work together to fix this! And if you find a fix, open a PR and I’ll merge it!
Oh and this is not an FAQ thing, more a sidenote, but either min_p is enabled with fireworks AI or temperature 2 works really nicely with Llama 3 70b — I used the min_p settings with that API and L3 70b to finish off the dataset and it was actually reasonably cheap, very fast and kinda good. Consider using that, I guess? Anyway.
I can’t wait to see what you all build with this. Here’s the repo link again: https://github.com/e-p-armstrong/augmentoolkit?tab=readme-ov-file#rptoolkit
Keep crushing it open model community!
讨论总结
本次讨论主要围绕一个开源的RP数据生成管道展开,讨论内容涵盖了模型推荐、配置文件的使用、工具的更新与错误修复,以及用户对实际应用示例的需求。用户们对这一工具的实际应用效果表现出浓厚兴趣,并提出了一些改进建议。总体上,讨论氛围积极,用户们对工具的潜力表示认可,并期待其进一步的发展和优化。
主要观点
👍 模型推荐
- 支持理由:用户推荐了多个模型,如turboderp/Mistral-Large-Instruct-2407-123B-exl2和Llama 3 70b,认为它们在数据生成方面表现出色。
- 反对声音:Command R+由于其重复性问题而不被推荐。
🔥 配置文件的使用
- 正方观点:RPToolkit仓库中提供了预构建的配置文件,方便用户参考和使用。
- 反方观点:无明显反对意见,用户普遍认为配置文件有助于提高使用效率。
💡 工具的更新与错误修复
- 支持理由:Augmentoolkit从专注于QA转变为包含RP功能,进行了大量的错误修复和性能提升,用户对此表示满意。
👀 实际应用示例的需求
- 支持理由:用户希望看到具体的输入文本和生成的角色扮演数据示例,以验证工具的实际功能和效果。
🤔 改进建议
- 支持理由:有用户建议在管道中加入RAG技术、多跳嵌入向量查询和知识图谱等高级技术,以提高生成效率和质量。
金句与有趣评论
“😂 Heralax_Tekran: "turboderp/Mistral-Large-Instruct-2407-123B-exl2 worked pretty well for me, with min_p."”
- 亮点:简洁明了地推荐了一个高效的数据生成模型。
“🤔 thereisonlythedance:Cool concept and a lot of work has obviously gone into this.”
- 亮点:表达了对工具背后大量工作的认可。
“👀 ironic_cat555:Could you provide an example of a text you fed into the software and the roleplay it generated from the text?”
- 亮点:直接提出了对实际应用示例的需求,体现了用户对工具实际效果的关注。
情感分析
讨论的总体情感倾向是积极的,用户们对工具的潜力表示认可,并提出了一些建设性的建议。主要分歧点在于模型的选择和工具的实际应用效果,但这些问题更多是技术层面的探讨,而非情感上的对立。
趋势与预测
- 新兴话题:RAG技术、多跳嵌入向量查询和知识图谱等高级技术的应用。
- 潜在影响:这些技术的引入可能会显著提升RP数据生成的效率和质量,进一步推动AI在角色扮演游戏领域的应用。
详细内容:
标题:创新的开源角色扮演数据生成管道在 Reddit 引发热议
在 Reddit 上,一则题为“I Made A Data Generation Pipeline Specifically for RP: Put in Stories, Get out RP Data with its Themes and Features as Inspiration”的帖子引起了广泛关注。该帖子获得了众多点赞和大量评论。
帖子主要介绍了作者创建的一个开源角色扮演(RP)数据生成管道。作者指出,创建 RP 数据集通常取决于可投入的资源,而目前缺乏开源的相关管道。于是,作者打造了一个能根据输入故事的主题和灵感生成 RP 会话的管道,并优化了其与本地模型的兼容性。此外,还制作了约 1000 个 RP 会话的数据集并开源。用户可以通过 Python 脚本或 GUI 运行该管道,支持多种 OpenAI 兼容的 API 及 Cohere。通过精心设计的 22000 个标记的提示,提升了最终数据的写作质量和长度。
讨论焦点主要集中在以下几个方面:
- 有用户询问作者推荐用于数据集生成的语言模型(LLM)。有人表示turboderp/Mistral-Large-Instruct-2407-123B-exl2 效果不错,Llama 3 70b 也还行,但有点过于乐观。
- 还有用户推荐 Magnum 123B 用于处理复杂角色和场景。
- 有长期用户询问与原始版本相比的变化,作者总结了包括更新提示和控制流、优化配置、新增分类器创建管道、修复大量 bug 等方面的改进。
- 有人询问能否将其用于创建故事写作数据集,作者表示可以通过两种方式实现。
讨论中的共识在于对这一创新工具的期待和认可,认为其为相关领域的发展提供了新的可能性。
然而,该早期版本也存在一些缺陷和独特之处:
- 缺乏黑暗和悲惨的元素,模型可能过于乐观。
- 故事生成提示精心制作,运行成本相对较高。
- 对 NSFW 内容的处理不够专业。
- 智能模型的表现参差不齐。
- 有时故事的最后一条消息过于像结论。
- 本地生成时可能速度较慢。
总之,这一开源的 RP 数据生成管道为相关领域带来了新的思路和工具,但仍有改进和完善的空间。大家都期待看到更多基于此的创新应用。https://github.com/e-p-armstrong/augmentoolkit?tab=readme-ov-file#rptoolkit


感谢您的耐心阅读!来选个表情,或者留个评论吧!