讨论总结
本次讨论主要围绕不同AI模型在各种任务上的表现展开,特别是GPT-4和O1模型的比较。讨论内容涵盖了模型的沟通能力、编码能力、数学推理等多个方面,同时也涉及了对比较方法和模型内部机制的质疑。部分评论对特定模型的表现表示赞赏,而另一些则提出了对模型性能的质疑和不满。整体讨论氛围较为技术性,涉及较多专业术语和模型内部运作机制的讨论。
主要观点
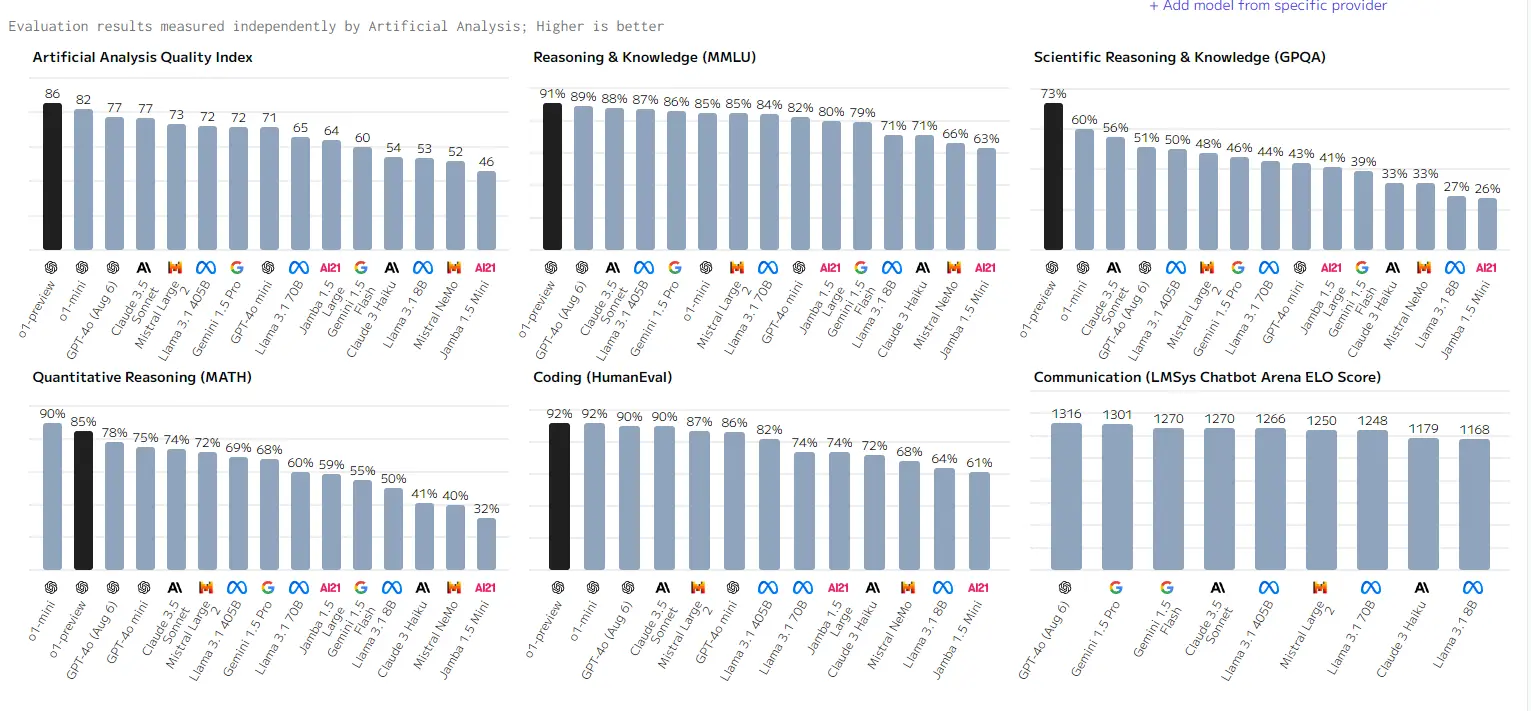
- 👍 O1模型在Chatbot Arena上的结果尚未发布,为何将其与已发布的模型进行比较。
- 支持理由:O1的写作风格与GPT-4相似,这可能是ELO评分的主要驱动因素。
- 反对声音:O1在沟通和编码能力上不如GPT-4。
- 🔥 作者质疑将AI模型与全规模系统进行比较的合理性。
- 正方观点:在比较过程中,可能存在未被考虑的“思维链”和“反思”机制。
- 反方观点:当前的比较方法可能不够全面。
- 💡 Mistral Large 2在特定任务上表现优异。
- 评论者对Mistral Large 2的性能表示赞赏,特别是其在123b参数规模下的表现。
- 💡 Gemini 1.5 flash模型在8B参数规模下的表现令人印象深刻。
- 评论者希望该模型能够公开以证明其确实是8B模型。
- 💡 o1 mini在数学推理测试中表现优于o1 preview。
- 过拟合问题可能是导致表现差异的原因之一。
金句与有趣评论
- “😂 Interesting, but why put Chatbot Arena results on there when O1 hasn’t had any published yet?”
- 亮点:对O1模型结果未发布却进行比较的质疑。
- “🤔 At this point, I don’t see any reason to compare ‘models’ to full scale systems like o1.”
- 亮点:对比较方法的合理性提出质疑。
- “👀 Once again, Mistral Large 2 killing it with 123b”
- 亮点:对Mistral Large 2性能的赞赏。
- “👀 Gemini 1.5 flash is so impressive for an 8B. I hope they can open it to prove it’s an 8B.”
- 亮点:对Gemini 1.5 flash性能的赞赏及公开模型的期望。
- “👀 Why does o1 mini (90%) outperform o1 preview (85%) in the mathematical reasoning (MATH) test?”
- 亮点:对o1 mini和o1 preview在数学推理测试中表现差异的疑问。
情感分析
讨论的总体情感倾向较为技术性和专业性,涉及较多模型性能和内部机制的讨论。部分评论对特定模型的表现表示赞赏,而另一些则提出了对模型性能的质疑和不满。主要分歧点在于对模型比较方法的合理性和模型内部机制的理解。可能的原因是讨论涉及较多专业术语和模型内部运作机制,导致部分评论者对讨论内容感到困惑或不满。
趋势与预测
- 新兴话题:对AI模型内部机制(如思维链、反思机制)的深入讨论可能会引发后续讨论。
- 潜在影响:对AI模型性能的深入讨论可能会影响公众对AI技术发展水平的理解,尤其是对于关心自然语言处理和机器学习领域的人来说。同时,这也可能引发关于AI伦理和安全问题的进一步讨论。
详细内容:
《AI 模型性能大比拼:o1 评估引发的激烈讨论》
在 Reddit 上,一张关于不同 AI 模型性能对比的柱状图引起了广泛关注。该图片清晰地展示了 GPT-4、GPT-3.5、Claude 等模型在推理知识、科学推理知识、定量推理、编码能力以及沟通能力等方面的得分情况。此帖获得了众多点赞和大量评论。
讨论的焦点主要集中在对不同模型性能的分析和评价上。有人指出 Chatbot Arena 结果放在这里不合适,因为 o1 还未公布。还有人认为 o1 在沟通方面不如 GPT-4。有人提到根据自己的尝试,在编码方面也存在类似情况。有人称此时将“模型”与像 o1 这样的全规模系统进行比较没有意义,可能存在很多幕后的协同和反思。有人表示 Mistral Large 2 表现出色。还有人对 o1 mini 在数学推理测试中超越 o1 preview 感到疑惑,有人解释可能是因为过度拟合,也有人提到 o1-mini 可能在后端使用了不同的模型,并且生成了更多的思考痕迹。
在这些讨论中,有人分享道:“作为一名长期关注 AI 领域的研究者,我发现不同模型在不同任务中的表现差异巨大。有时候,一些小型模型反而能在特定领域取得更好的效果,这让我们对模型的优化和选择有了更多思考。”
这场讨论中的共识在于大家都对 AI 模型的性能差异表现出浓厚兴趣,并希望能够更深入地理解其背后的原因。特别有见地的观点是对于模型性能差异原因的深入探讨,这丰富了整个讨论的层次。
总的来说,这次关于 AI 模型性能的讨论让我们更清晰地看到了当前 AI 技术的发展现状和面临的挑战,也为未来的研究和应用提供了更多思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!