讨论总结
本次讨论主要围绕AI模型在推理任务上的表现展开,特别是对“o1-mini”模型在推理能力上的高度评价。讨论内容涵盖了模型性能、内存需求、模型优化、提示策略等多个方面。参与者对“o1-mini”在特定任务中的表现表示惊讶,并探讨了AI模型是否存在“过度思考”的现象。此外,讨论还涉及了模型大小与推理能力之间的关系,以及内存需求对AI硬件的限制。整体讨论反映了AI领域对模型性能和资源消耗的关注。
主要观点
👍 AI模型可能存在“过度思考”的现象
- 支持理由:评论者认为AI模型在某些任务上可能花费过多时间进行推理,导致性能下降。
- 反对声音:无明显反对声音,但有讨论提出可以通过优化模型来减少这种“过度思考”。
🔥 内存需求是当前AI硬件的主要瓶颈
- 正方观点:评论者普遍认为内存需求限制了AI模型的性能和应用范围。
- 反方观点:无明显反方观点,但有讨论提出可以通过技术手段减少内存需求。
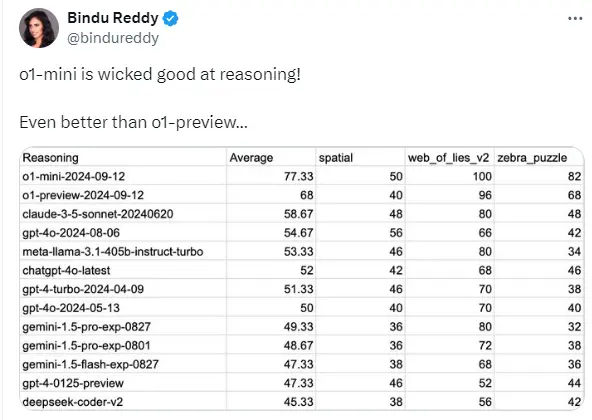
💡 “o1-mini”模型在推理能力上优于“o1-preview”
- 解释:评论者指出“o1-mini”是经过进一步优化和提炼后的版本,因此在推理能力上表现更优。
💡 LLM在空间推理任务上的表现不佳
- 解释:评论者认为LLM的智能是文本分析的涌现属性,而非3D世界的体现。
💡 OpenAI的提示指南建议避免使用链式思维提示
- 解释:评论者提到OpenAI最新的官方提示指南,认为模型已经具备内部推理能力,因此不需要额外的提示来引导推理。
金句与有趣评论
“😂 Makes me think that there may be a such a thing as overthinking for AI models. Funny thought.”
- 亮点:提出了AI模型可能存在“过度思考”的有趣观点。
“🤔 I can easily imagine and the next paradigm shift being "reflection is all you need" and 8b models just deliberating over whatever they just shat out at length.”
- 亮点:探讨了AI模型未来可能的发展方向,提出了“反思”可能成为新的范式。
“👀 Memory is THE bottleneck for AI hardware right now, not just for us but for the big companies too.”
- 亮点:强调了内存需求是当前AI硬件的主要瓶颈,不仅是小公司,大公司也面临同样的问题。
“👀 LLM intelligence is not embodied in a 3D world. It’s all an emergent property of text analysis.”
- 亮点:提出了LLM的智能是文本分析的涌现属性,而非3D世界的体现。
“👀 Just saw OpenAI’s latest official prompting guidelines, and something caught my eye.”
- 亮点:引入了OpenAI最新的提示指南,引发了关于提示策略的讨论。
情感分析
讨论的总体情感倾向较为专业和信息性,参与者对AI模型的性能和优化表现出浓厚的兴趣。主要分歧点在于AI模型是否存在“过度思考”的现象,以及内存需求对AI硬件的限制。这些分歧反映了AI领域对模型性能和资源消耗的关注。
趋势与预测
- 新兴话题:AI模型的提示策略和内部推理能力的进一步优化。
- 潜在影响:随着AI模型性能的提升和内存需求的减少,AI在更多领域的应用将得到扩展,特别是在需要高推理能力的任务中。
详细内容:
标题:关于 AI 模型推理能力比较的热门讨论
近日,Reddit 上一则有关不同 AI 模型推理能力对比的帖子引发了热烈关注。该帖子分享了一张来自 Twitter 的截图,展示了多个 AI 模型在不同任务上的表现数据,获得了众多点赞和大量评论。帖子主要讨论了“o1-mini”和“o1-preview”等模型的推理能力,引发了关于 AI 模型性能、训练方式、应用场景以及未来发展方向等多方面的探讨。
在讨论中,有人认为对于 AI 模型可能存在过度思考的情况,这是一个有趣的想法。也有人指出,更大的模型可能因成本问题而在某些方面的表现进行了调整,可惜我们无法确切知晓。还有人想象未来的范式转变可能是“反思即所需”,8b 模型会对输出结果进行深入思考,这对于内存有限的情况会很便利,但也有人认为大量的内部思考会拉高内存需求。
有人好奇“web_of_lies”模型是什么,并有用户提供了相关链接https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/web_of_lies。对于推理测试,有人表示希望能亲自尝试以感受其成果的惊人程度,并有链接https://arxiv.org/pdf/2406.19314#subsection.2.3供参考。
有人提到“o1-mini”的训练过程,认为从最初的模型到完善版本再到精简的“o1-mini”版本,结果合理。也有人将其与其他模型的使用经验进行对比。还有人认为既然不是在讨论本地 LLM,不如聊聊露营地变得越来越单调,以及餐厅应该为孩子设置更多娱乐区域等话题。
另外,有人分享了 OpenAI 最新的官方提示指南,指出其建议避免思维链提示,这似乎表明模型已进化到新类别,引发大家对提示策略是否需要重新思考的讨论。
总之,这次关于 AI 模型推理能力的讨论,观点丰富多样,既涉及技术细节,也涵盖了实际应用和未来趋势的思考,为我们理解 AI 模型的发展提供了多维度的视角。


感谢您的耐心阅读!来选个表情,或者留个评论吧!