讨论总结
本次讨论主要围绕AI模型o1-preview在LiveBench AI平台上的性能表现展开,涵盖了编码、推理等多个任务的优劣对比。讨论中,用户们对o1-preview在不同任务上的表现提出了各自的看法,有的认为其在编码任务上表现不佳,有的则对其推理能力表示认可。此外,讨论还涉及了模型命名、未来发展方向等话题,反映了AI领域在技术评估和市场接受度方面的复杂性和多样性。
主要观点
👍 o1-preview在编码任务上表现不佳
- 支持理由:多个用户指出o1-preview在代码生成和代码完成任务上的表现不如其他模型,如3.5 Sonnet和4o模型。
- 反对声音:有用户认为随着训练数据的增加,o1模型的性能会有所提升。
🔥 o1-mini在推理任务上表现出色
- 正方观点:o1-mini在纯推理任务上达到100%的准确率,表现优于o1-preview。
- 反方观点:o1-mini在需要遵循指令的任务上表现较差。
💡 代码生成与代码完成的区别
- 解释:代码生成是基于文本提示生成代码,而代码完成是基于现有代码进行补充。这一区别影响了模型在不同任务上的表现。
🚀 AI模型的命名问题
- 解释:用户普遍对AI模型命名为“o1”表示不满,认为这种命名方式不专业且容易引起混淆。
🌐 AI模型的未来发展方向
- 解释:未来的AI发展可能在于根据上下文动态确定响应和分词策略,甚至可能需要一个模型路由器,根据不同的使用场景选择更专业的模型变体。
金句与有趣评论
“😂 Still much worse than 3.5 Sonnet at coding, even worse than 4o.”
- 亮点:直接指出了o1-preview在编码任务上的不足。
“🤔 Code generation is when Ai is given words as prompt, and generates code. For example: "write me a snake code in Java"”
- 亮点:清晰解释了代码生成与代码完成的区别。
“👀 o1-mini has a very interesting spread. It’s much better than o1-preview at the purest reasoning tasks, but it’s much worse at the tasks that small models typically struggle on.”
- 亮点:指出了o1-mini在推理任务上的优势和不足。
“💬 i fucking hate their naming”
- 亮点:表达了用户对模型命名方式的强烈不满。
“🌟 Crazy that the step up overall is only on par with what Claude sonnet 3.5 was to gpt-4o.”
- 亮点:指出了o1-preview在整体性能提升上的局限性。
情感分析
讨论的总体情感倾向较为复杂,既有对o1-preview性能的失望和批评,也有对其未来改进的期待。主要分歧点在于模型在不同任务上的表现,如编码和推理任务的优劣对比。可能的原因包括模型训练数据的侧重点不同、推理链的使用策略等。
趋势与预测
- 新兴话题:AI模型的命名问题和未来发展方向可能会引发后续讨论。
- 潜在影响:对AI模型性能的深入评估可能会影响未来的研究和开发方向,特别是对于那些希望改进特定任务表现的模型开发者。
详细内容:
标题:Reddit 上关于 o1 在 LiveBench AI 表现的热烈讨论
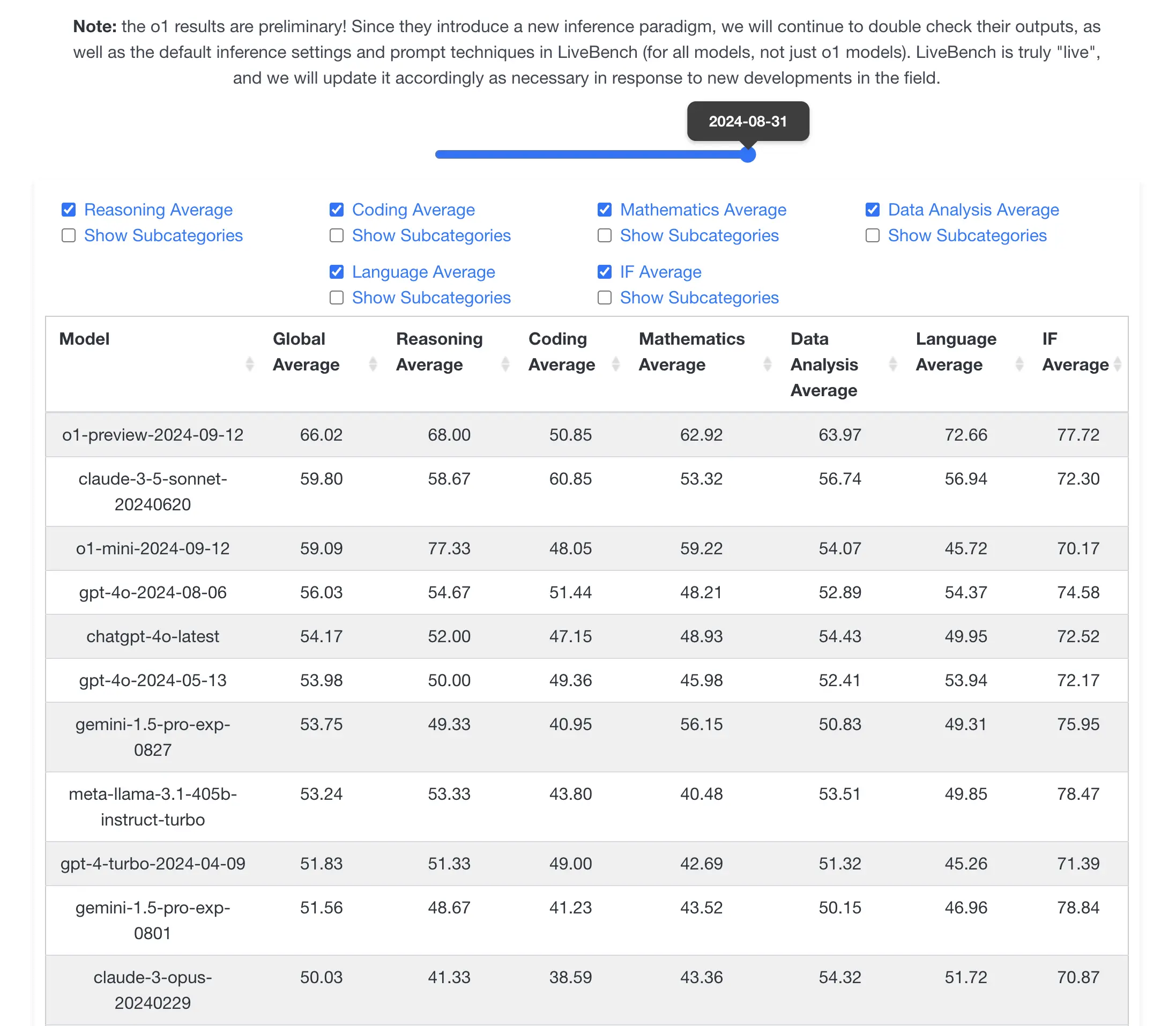
在 Reddit 上,一则关于“o1-preview 在 LiveBench AI 中总体排名第一”的帖子引起了广泛关注。该帖子包含一张展示多个 AI 模型性能指标对比的表格截图,以及众多相关的讨论和观点。截至目前,该帖子获得了大量的点赞和评论。
讨论的焦点主要集中在 o1 模型在不同任务中的表现,尤其是在编码相关任务上。有人指出 o1 在编码生成方面表现出色,但在编码完成方面则差强人意,甚至不如 3.5 Sonnet 和 4o。比如,有用户分享道:“Still much worse than 3.5 Sonnet at coding, even worse than 4o. Surprising. Hopefully they release o1 (non-preview version) soon, as the current o1 preview is worse than o1-mini (the release version) on a lot of benchmarks, even code (shown by OpenAI’s own blog post)”。
对于 o1 模型在编码任务中表现不佳的原因,用户们提出了各种观点。有人认为可能是训练数据或训练方式的问题,比如“auradragon1”提到:“I wonder if it’s because the o1 models are trained on fewer raw tokens and more on human instructions. That might explain why it isn’t as good at coding.” 也有人认为是模型的思维链步骤导致了代码的改变和丢失,从而影响了编码完成任务的表现。
在讨论中,也存在一些共识。比如大家普遍认为 o1 模型在不同任务中的表现存在差异,并且需要进一步的改进和优化。同时,也有一些独特的观点,比如“Hemingbird”详细解释了 o1 采用的新推理范式的创新性:“The idea is pretty simple. You just use RL to improve CoT, which transforms it into a learnable skill. Reasoning is action. That’s the reason why traditional LLMs haven’t been able to crack it. What they’re doing is, essentially, perception; recognizing patterns. Their outputs are similar to filling out our visual blank spots. They can learn patterns arbitrarily well, but what they do is pattern completion (perception) rather than pattern generation (action). CoT + RL means you’re dealing with action rather than perception. You discretize the reasoning process into steps, let the model explore different steps, and reward it based on performance. We’re in AlphaGo territory, in other words. RLHF/RLAIF treats text generation as a single-step process, which is not an ideal approach for solving complex problems. The reason why this is "a new inference paradigm" is that we can now get better results by letting models "think deeper". It’s System 1 vs. System 2. ByteDance published a paper earlier this year along these lines. This paper takes it a step further. When you do a similar thing with VLMs, you can also get performance feedback along the way. This method will probably crush ARC-AGI.”
总的来说,Reddit 上关于 o1 模型的讨论反映了大家对其性能的关注和期待,同时也为 AI 模型的发展和改进提供了有价值的思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!