几天前,MistralAI 通过种子文件发布了 Pixtral。我很兴奋。终于,一家拥有大量资金的大型西方公司推出了开源视觉语言模型(VLM)。终于有机会获得一个不是仅仅在 OpenAI 的输出上微调的模型了。
发布几天后,我成功运行了它。我给它输入了一张可爱的橡皮鸭图片,问“描述这张图片”,并得到了回复。
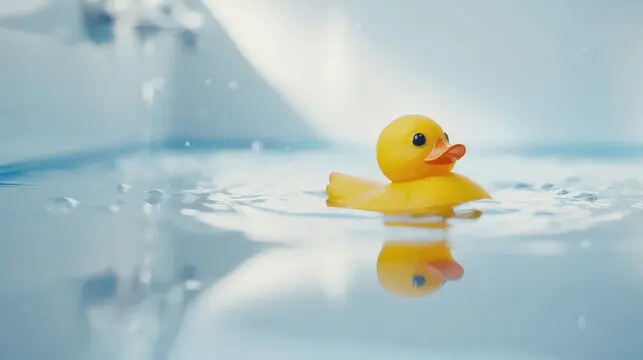
图片中,一只鲜艳的黄色橡皮鸭是主要主题,快乐地漂浮在浅蓝色的水面上。鸭子面向图片的右侧,似乎在阳光下晒太阳,正如水面反射的明亮光线所示。背景是较深的蓝色,营造出深度感,增加了场景的整体宁静感。图片散发出一种平和与宁静的感觉,鸭子是唯一的焦点。
…
该死。
对于那些没有花时间研究 GPT4V 的人来说,这可能看起来是一个不错的小标题。并非如此。它充满了经典的 GPT4V 风格,主观性和无用的废话,自从 OpenAI 发布他们的关于 dalle3 的技术报告以来,我一直对此感到不满。
众所周知,ChatGPT 真的,真的,喜欢使用某些短语,我认为这个问题在 GPT4V 的图片描述中仍然存在。
考虑到这一点,让我们来看看 ShareGPT4V 数据集,这是一个包含大量 GPT4V 输出的集合。由于最近 HF 数据集添加了 SQL 查询功能,这项任务相对容易。
首先,总行数:102025
接下来,我搜索了一些在我 Pixtral 输出中引起我注意的短语。
一种感觉:26376(25%)
相对位置:12071(11%)
表明:3426(3.3%)
散发出一种感觉:3419(3.3%)
在某个时刻:2457(2.4%)
没有明显的文字:2432(2.3%)
和谐平衡:2124(2%)
增加整体:1867(1.8%)
场景元素:1580(1.5%)
结论:
我非常失望,尽管拥有数百万美元的资金,Mistral 在视觉领域仍然严重依赖 OpenAI 的训练数据。我更失望的是,他们甚至没有做一点点后处理来消除这些数据中常见的无用短语。
MistralAI 曾被描述为“与 OpenAI 竞争,成为欧洲的 AI 冠军”。看到他们在原创性和试图击败 OpenAI 上投入的实际价值如此之少,我感到很难过。
更多 Pixtral 输出:
图片捕捉到了日落时分山脉的壮丽景色。天空被橙色和粉色的色调所浸染,为雄伟的山峰提供了壮丽的背景。山峰被一层纯净的白雪覆盖,在天空的映衬下显得格外雄伟。最高的山峰位于图片中央,被夕阳的温暖光芒所笼罩。这座山峰被几座较小的山峰环绕,在图片中营造出深度和规模感。图片是从高处拍摄的,提供了景观的全景视图。图片中没有明显的文字或人造物体。山峰和夕阳的相对位置在图片构图中创造了一种和谐的平衡。
图片中,一只小型柯基犬是主要主题,站在草地上。狗的毛色是棕色和白色的混合,戴着黑色项圈。它的舌头伸出来,表明它可能在喘气或兴奋。狗面向相机,让我们清楚地看到它的特征。图片的背景是一片绿色的草地,有树木和灌木,为狗提供了自然的背景。图片中没有明显的文字或其他物体。狗相对于背景的位置表明它在图片的前景中。狗似乎独自在草地上,没有其他狗或人可见。
讨论总结
本次讨论主要围绕MistralAI发布的Pixtral模型在图像描述方面的表现展开。许多用户对Pixtral模型在训练数据上严重依赖OpenAI表示失望,认为其描述过于冗长且包含大量无用的修饰性语言,缺乏原创性和实用性。部分用户指出,尽管MistralAI获得了大量资金支持,但其视觉模型在创新性上表现不佳,只是在模仿OpenAI。然而,也有用户对Pixtral模型的准确性和开放源代码表示肯定,认为这对于盲人用户和社区来说是有价值的。讨论中还涉及了模型微调、数据质量、情感描述和工程师式描述等多个方面,总体情感倾向较为负面,但也存在一些建设性的批评和建议。
主要观点
👍 Pixtral模型在训练数据上严重依赖OpenAI
- 支持理由:用户指出Pixtral的描述风格与GPT4V相似,缺乏原创性。
- 反对声音:部分用户认为依赖OpenAI的数据并不一定是坏事,关键在于模型的实际表现。
🔥 Pixtral模型的描述过于冗长且包含大量无用的修饰性语言
- 正方观点:用户认为这些修饰词在实际应用中(如视觉辅助)是无用的废话。
- 反方观点:有用户认为情感描述在某些场景(如艺术评论)中是必要的。
💡 MistralAI缺乏原创性和创新性
- 支持理由:用户认为MistralAI作为一家被寄予厚望的公司,应该在原创性和创新性上投入更多,而不是简单地模仿OpenAI。
👍 Pixtral模型的准确性令人满意
- 支持理由:部分用户认为Pixtral在图像描述的准确性上表现良好,尤其是在描述橡皮鸭的场景中。
🔥 开放源代码的Pixtral模型对社区有益
- 支持理由:用户认为开放源代码的模型对于盲人用户和社区来说是非常有价值的。
金句与有趣评论
“😂 ResearchCrafty1804:I get what you’re saying, but you’re complaining for a multi million dollar model that we get for free. It’s kind enough they made it open weight.”
- 亮点:强调了尽管模型存在问题,但免费提供给用户已经是一种慷慨。
“🤔 hopbel:That doesn’t mean we can’t give constructive criticism. "The model uses flowery language even when it’s unwanted" is useful feedback for future dataset curation.”
- 亮点:提出了建设性批评的重要性,认为用户的反馈可以帮助改进模型。
“👀 GobDaKilla:Reading this post, the cocktail of disgust and amusement I feel is sending shivers down my spine.”
- 亮点:生动地描述了用户对帖子内容的复杂情感反应。
“😂 Few_Painter_5588:Pixtral is a good first step, but I don’t think it’s particularly good as it can’t do many visual tasks beyond describing an image.”
- 亮点:指出了Pixtral模型在功能上的局限性。
“🤔 Baader-Meinhof:I’m curious if anyone knows the process and tooling for fine tuning these visual descriptions?”
- 亮点:表达了用户对微调工具和流程的好奇心。
“👀 West-Code4642:this speak is similar to how art critics also describe art.”
- 亮点:将Pixtral模型的描述风格与艺术评论家的描述方式进行了类比。
“😂 LienniTa:yeah i also got tired of all the breathtaking bullshit, that vision models poops with their voice just above the whisper.”
- 亮点:幽默地表达了用户对模型描述中夸张语言的不满。
“🤔 Nification:Your captions are technically correct and are more lean in token count, I have to ask why? Why is the saving of a mere 50 (or if we retain some details that you have omitted that are useful in getting a more accurate spacial picture, 20) or so tokens, when models that can handle 20k+ are increasingly available, so important?”
- 亮点:提出了对描述简洁性的质疑,认为在现代模型中,节省少量token并不重要。
“👀 F_Kal:comparing it to the LLaVA models I’ve used, I like the fact that these descriptions at least point out elements of composition such as light and placement of objects”
- 亮点:指出了Pixtral模型在描述中包含更多构图细节的优点。
“😂 MrMeier:更倾向于事实性的描述,但这最终是个人偏好的问题。”
- 亮点:强调了描述风格的主观性,认为不同用户可能有不同的偏好。
情感分析
讨论的总体情感倾向较为负面,主要集中在对Pixtral模型依赖OpenAI数据、描述冗长且缺乏原创性的批评上。用户普遍对MistralAI在创新性和实用性上的表现感到失望,认为其未能充分利用其资金和资源。然而,也有部分用户对Pixtral模型的准确性和开放源代码表示肯定,认为这对于盲人用户和社区来说是有价值的。讨论中的主要分歧点在于描述的简洁性与丰富性之间的平衡,以及模型在实际应用中的实用性与创新性之间的权衡。
趋势与预测
- 新兴话题:未来可能会出现更多关于如何微调图像描述模型以提高其实用性和准确性的讨论,以及如何减少对OpenAI数据的依赖。
- 潜在影响:如果MistralAI能够改进Pixtral模型,减少对OpenAI数据的依赖,并提高描述的简洁性和实用性,可能会在视觉语言模型领域取得更大的进展,甚至可能挑战OpenAI在该领域的领导地位。
详细内容:
标题:对 Pixtral 模型的争议:在视觉模型领域的探索与批评
近日,Reddit 上出现了一个关于 Pixtral 模型的热门讨论。原帖作者称,MistralAI 发布的 Pixtral 模型虽令人期待,但其表现却不尽如人意。该模型在描述图像时,充满了类似 GPT4V 的主观性和无用的废话,这让作者深感失望。此帖获得了众多关注,评论数众多,引发了大家对于该模型的热烈讨论。
讨论的焦点主要集中在以下几个方面:
- 有人认为,对于一个免费且耗费数百万美元研发的模型,我们不应过于苛责,应看到其开放的价值。但也有人反驳,这并不妨碍给出建设性的批评,指出模型存在的问题有助于未来数据的优化。
- 一些用户表示,不能仅凭个人喜好来评判模型的描述风格,关键在于其是否有效和准确。比如对于盲人用户来说,准确的图像描述就非常重要。
- 还有用户探讨了不同模型的优劣,如 Qwen2-VL 在某些方面表现出色,而 Pixtral 在某些方面有待改进。
- 关于模型描述中的“无用废话”,有人认为这并非毫无价值,而是能够连接概念,对于艺术欣赏等场景有其作用;但也有人坚决反对,认为这些描述过于冗长和多余,会影响模型在特定场景下的应用。
比如,有用户分享道:“作为一名盲人,拥有一个出色的本地图像描述人工智能,只要准确,那将是非常棒的!”还有用户提供了相关模型的对比链接:https://github.com/QwenLM/Qwen2-VL 。
这场讨论中的共识在于,大家都希望模型能够不断改进和优化,以更好地满足不同的需求。特别有见地的观点是,有人指出模型的描述风格应根据具体应用场景进行调整,不能一概而论。
总之,对于 Pixtral 模型的评价呈现出多样化的态势,反映了大家对视觉模型发展的关注和期待。希望未来能有更加出色和实用的模型出现,为相关领域带来更多的便利和创新。


感谢您的耐心阅读!来选个表情,或者留个评论吧!