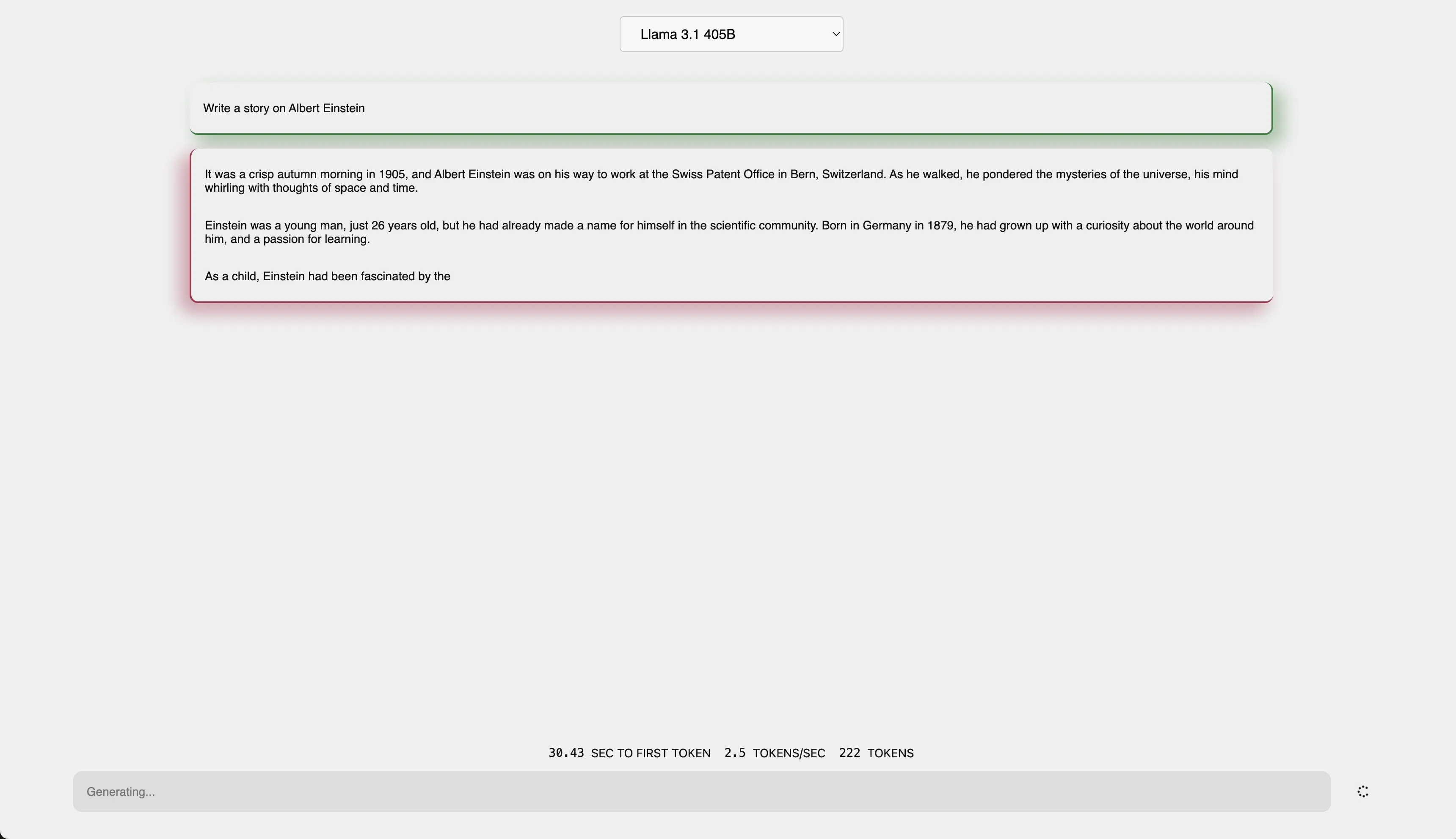
这里是Llama 405B在Mac Studio M2 Ultra + Macbook Pro M3 Max上运行! 每秒2.5个token,但我相信它会随着时间的推移而改进。
由Exo驱动:https://github.com/exo-explore 和Apple MLX作为后端引擎。
来自Apple MLX创建者的重要技巧:u/awnihannun
在Exo网络中的所有机器上设置这些: sudo sysctl iogpu.wired_lwm_mb=400000 sudo sysctl iogpu.wired_limit_mb=180000
讨论总结
本次讨论主要围绕Llama 405B模型在Mac Studio M2 Ultra和Macbook Pro M3 Max上的本地运行展开。讨论内容涵盖了模型的性能表现、硬件配置需求、后端引擎的选择(如Exo和Apple MLX)、以及性能优化的技术细节(如量化和多设备池化)。此外,讨论中还涉及了经济成本与订阅服务的权衡,以及未来商业化运作的可能性。总体而言,讨论氛围偏向技术性和专业性,参与者对模型的性能和优化表现出浓厚兴趣。
主要观点
👍 Llama 405B在Mac设备上的运行速度为2.5 tokens/sec
- 支持理由:尽管速度较慢,但能在Mac设备上运行Llama 405B仍然令人印象深刻。
- 反对声音:初始响应时间(30.43秒)对于仅有6个token的提示来说表现不佳。
🔥 Exo和Apple MLX作为后端引擎,对模型的运行起到了关键作用
- 正方观点:Exo和Apple MLX的结合使用,性能表现良好。
- 反方观点:网络连接(wifi)可能是影响性能的一个因素。
💡 量化技术在模型优化中的应用
- 解释:量化是一种优化技术,通常用于减少模型的大小和提高推理速度。
🌐 多设备池化的可能性
- 解释:Exo和llama.cpp可以用于多设备处理能力池化,提升整体性能。
💰 经济成本与订阅服务的权衡
- 解释:尽管展示的技术很酷,但考虑到硬件的高成本,更倾向于选择订阅服务。
金句与有趣评论
“😂 ifioravanti:153.56 TFLOPS! Linux with 3090 added to the cluster!!!”
- 亮点:展示了通过添加高性能设备显著提升集群性能的兴奋之情。
“🤔 kjerk:With prompts like that, Llama 405B isn’t going to save you.”
- 亮点:指出了AI模型性能受限于输入提示质量的问题。
“👀 quiettryit:For the cost of hardware I’ll just pay a subscription, still cool though!”
- 亮点:从经济角度出发,提出了硬件成本与订阅服务之间的权衡。
“😂 drosmi:I umm might have enough hardware to do this…. So cool.”
- 亮点:表达了可能具备足够硬件条件来运行Llama 405B的兴奋之情。
“🤔 estebansaa:very cool! Im wondering wether there is some business model on a farm of mac studios doing lots more tks.”
- 亮点:对利用Mac Studio集群进行商业化运作的可能性表示好奇。
情感分析
讨论的总体情感倾向偏向积极和技术性。参与者对Llama 405B在Mac设备上的运行表现表示赞赏,并对未来的性能提升持乐观态度。主要分歧点在于硬件成本与订阅服务的权衡,以及不同模型版本和优化技术的性能对比。这些分歧主要源于经济考量和技术细节的差异。
趋势与预测
- 新兴话题:多设备池化和量化技术在AI模型优化中的应用可能会引发更多讨论。
- 潜在影响:随着技术的发展,本地运行大型AI模型的成本和性能将进一步提升,可能会影响企业和个人用户的选择。
详细内容:
标题:Llama 405B 在本地运行引发热议
近日,Reddit 上一则关于 Llama 405B 在本地运行的帖子引起了广泛关注,获得了众多点赞和大量评论。帖子中展示了运行 Llama 405B 的相关界面截图,详细介绍了其视觉元素、情感氛围、技术细节等方面,还提到了它在 Mac Studio M2 Ultra 和 Macbook Pro M3 Max 上的运行情况。
讨论的焦点主要集中在性能和配置方面。有人称赞 exo 是一个很酷的分布式引擎,搭配 MLX 性能出色,能达到接近饱和的 500gb/秒的 GPU 传输速度。但也有人指出,30.43 秒才生成第一个令牌且提示中只有 6 个令牌的情况并不理想。还有用户表示 2.5 令牌/秒的速度还算能玩。
在配置方面,有人尝试将 NVidia 3090 添加到集群中,运行速度达到 153.56 TFLOPS。对于所需内存,有人指出运行 q4 版本至少需要 229GB 的 RAM,而 q2_k 版本则需要 149GB。
关于连接方式,有说是通过 wifi 连接,也有开玩笑说蓝牙、拨号、电报、信鸽、烟雾信号等。
在性能比较方面,有人认为 q2 与 fp16 和 70b fp16 相比存在差异;也有人表示在实际体验中 Llama 405B 比 DeepSeek 更好;还有人提到或许可以尝试 deepseek-v2.5,称其速度更快。
对于多设备聚合的方式,有人提到 llama.cpp 效果不错但存在性能损失,还可以测试 cake 作为替代。
总的来说,这次关于 Llama 405B 在本地运行的讨论十分热烈,展示了大家对新技术探索的热情和不同的见解。


感谢您的耐心阅读!来选个表情,或者留个评论吧!