我在一个非常小的(甚至可以说是微小的)规模上进行实验,但我真的被它的可行性震撼了,看看这个(是的,这是一个愚蠢的测试,但我认为对于Q4_K_M 8B模型来说已经很不错了):
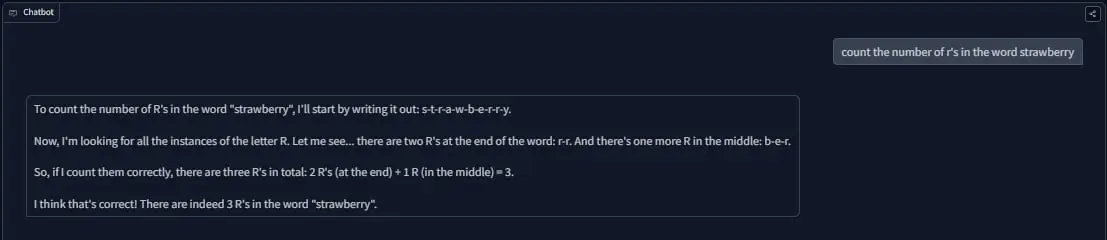
是的,它可能看起来毫无意义或多余(因为分词器之类的原因),但用于微调的数据集只包含370行(可以说是)高质量的数据,欢迎查看数据集。
另外,欢迎下载模型并测试完整精度的版本,只需确保使用模型仓库中的提示,否则它将无法工作,我已经提交到排行榜,希望能很快得到结果。
这篇帖子的目的不是介绍一个SOTA模型,而是强调我们这些GPU资源匮乏的人很快就能拥有一个开源的o1类型模型的可扩展性和潜力。
模型: https://huggingface.co/Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
演示: https://huggingface.co/spaces/Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3-Q4_K_M
数据集 https://huggingface.co/datasets/Lyte/Reasoner-1o1-v0.3-HQ
讨论总结
本次讨论主要围绕一个开源o1模型的实验展开,作者分享了在极小规模上的实验结果,展示了模型的可行性。评论者们对实验的透明度和积极意义表示肯定,但也提出了对模型性能的质疑和技术挑战。讨论中涉及的主要话题包括模型的强化学习实现、数据集的质量和结构、推理能力的提升以及模型训练过程中的技术细节。总体上,讨论氛围积极,但也存在一些争议和质疑。
主要观点
👍 开源模型的可扩展性和潜力
- 支持理由:实验展示了在极小数据集上也能让模型“学习推理”,尽管这不是逻辑推理,但仍然展示了推理能力。
- 反对声音:有人认为模型在多次测试中表现不稳定,仅有一次正确。
🔥 强化学习在模型中的应用
- 正方观点:o1模型可能需要强化学习的实现,以提升模型的推理能力。
- 反方观点:强化学习在模型中的应用方式存在争议,有人认为现有的CoT数据集已经足够。
💡 数据集的质量和结构
- 解释:数据集的质量和结构对模型的表现有重要影响,尽管实验使用的数据集规模很小,但质量较高。
🚀 模型训练过程中的技术挑战
- 解释:模型训练过程中评分和误差控制是关键挑战,需要进行基准测试以验证模型性能。
🌱 新兴技术方向:并发计算和思维树
- 解释:并发计算在模型开发中具有重要意义,思维树的概念可能与并发计算相关联。
金句与有趣评论
“😂 FancyMetal:Disclaimer: Just to be clear, I don’t like hype, and I don’t stand to gain anything from this. I simply found this experiment interesting and wanted to share it with everyone.”
- 亮点:作者的坦诚和分享精神。
“🤔 1EvilSexyGenius:当前大量资金投入在构建大型超级计算机和神经网络是错误的。”
- 亮点:对AI发展方向的深刻反思。
“👀 Many_SuchCases:This holds a lot of potential! Great job!”
- 亮点:对模型潜力的认可和鼓励。
“😅 Dankmre:Sorry that was a dick thing to say and had no basis on what you posted.”
- 亮点:评论者的道歉和反思。
“💡 RedditPolluter:The dataset doesn’t contain any prompts related to counting letters and teaching a model to count letters in a word does not improve its general reasoning ability.”
- 亮点:对数据集和模型训练的深入分析。
情感分析
讨论的总体情感倾向较为积极,大多数评论者对实验表示认可和支持,认为开源模型的可扩展性和潜力值得期待。然而,也有一些评论者对模型的性能和技术细节提出了质疑,认为需要更多的基准测试和数据集扩展来验证模型的实际效果。总体上,讨论氛围较为友好,但也存在一些技术上的争议和挑战。
趋势与预测
- 新兴话题:并发计算和思维树的概念可能会引发后续讨论,尤其是在模型开发和应用中的关键作用。
- 潜在影响:开源模型的实验和讨论可能会推动本地语言模型的开发和创新,尤其是在资源有限的开发者中。未来可能会看到更多关于小型模型效率提升和推理能力增强的研究和实践。
详细内容:
标题:关于创建开源 o1 模型的热门讨论
近日,Reddit 上一则关于创建开源 o1 模型的帖子引发了热烈讨论。该帖子的作者 [FancyMetal] 称,尽管是在极小的规模上进行实验,但效果令其惊叹。此帖获得了众多关注,评论数众多。
帖子主要展示了一个计算单词“strawberry”中字母“r”数量的聊天机器人界面截图,并提供了相关模型、演示和数据集的链接。作者强调,此帖目的并非介绍最先进的模型,而是突显对于资源有限的人来说,创建开源 o1 型模型的可扩展性和潜力。
讨论焦点主要集中在模型的性能、训练方法以及与现有模型的比较等方面。有人认为这只是一个不错的开端,也有人质疑其实际效果。例如,有用户分享道:“对于任何抱怨非本地 LLMs 在 /r/LocalLLaMA 上被讨论的人来说,这就是为什么它们会在这里被讨论。因为它激发了像 OP 这样的人的好奇心和实验,有助于推动我们走向更有趣的本地 LLMs。”
还有用户指出:“大资金投入人工智能的方向是错误的,应该致力于让较小的模型更有能力和效率。”但也有人认为小型语言模型由于神经网络的连接有限,难以达到足够的智能水平。
在讨论中,对于模型的改进方向和实际效果存在争议。一方面,有人认为通过小规模实验能看到模型“学习推理”的潜力;另一方面,也有人认为数据集过小,无法真正提升模型性能,且模型在某些任务上的表现存在缺陷。
总体而言,这场讨论展示了大家对于开源 o1 模型的关注和期待,同时也反映出在模型开发和应用方面存在的诸多思考和挑战。


感谢您的耐心阅读!来选个表情,或者留个评论吧!