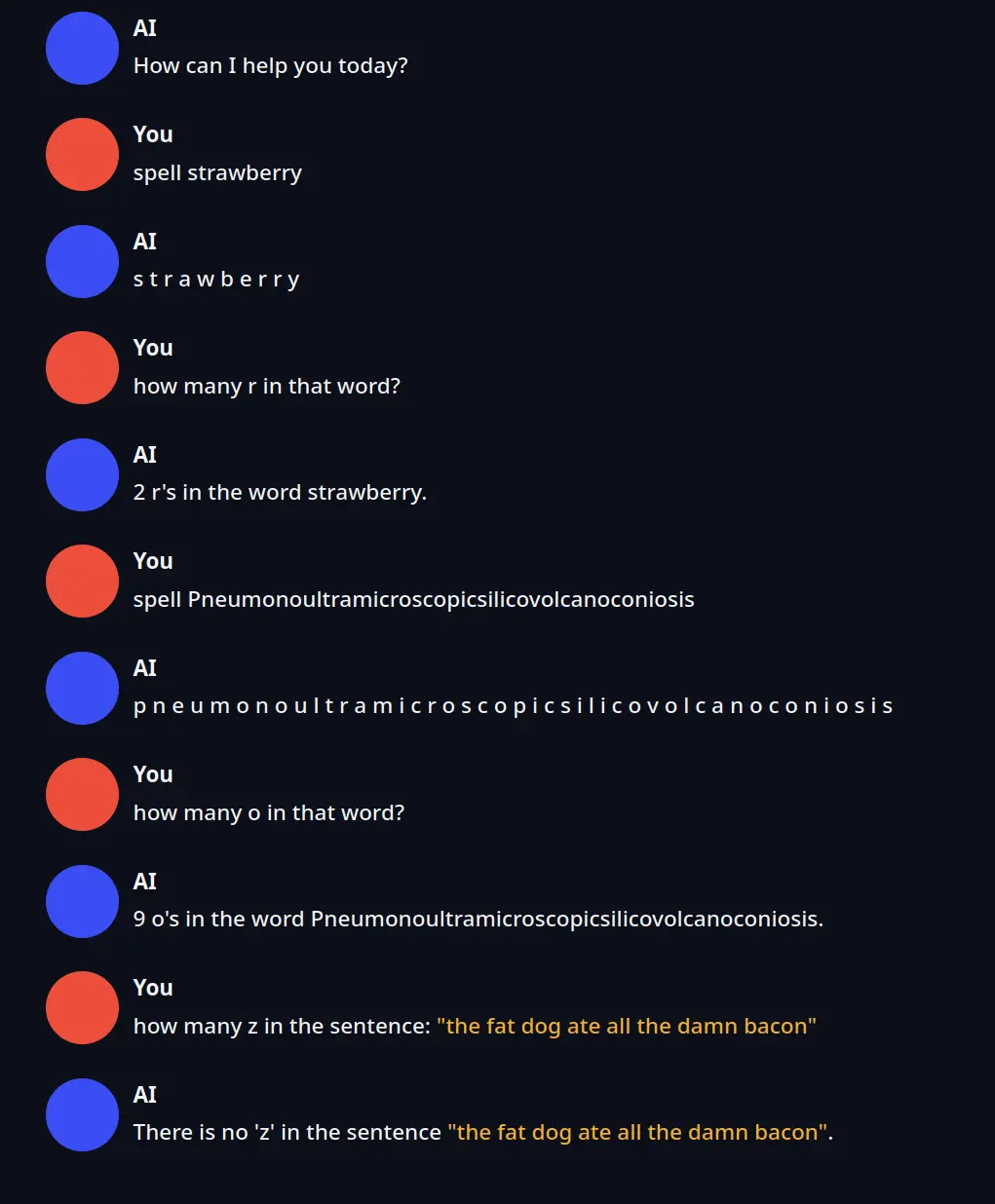
reddit上的人说没有LLM能拼出Strawberry这个词,所以凭借多年的水下编织篮子的专业知识,我决定自己实现AGI,证明如下:
由于安全原因,我担心将模型公开的后果。
但如果有人需要,我会考虑发布用于训练该模型的数据集。
(数据集大小约为800MB的JSON)
更新:为研究社区发布数据集:
https://huggingface.co/datasets/Black-Ink-Guild/Black_Strawberry_AGI
更新2:
核心概念从根本上来说是合理的,尽管最初是以一种更轻松的方式呈现的。语言模型(LLMs)本质上记住了“Dog”这个词与“d”+“o”+“g”的组合有关。
当被要求计算特定词(如“Dog”)中的字母时,模型需要检索一组特定的标记(字母)。
计算单词中的字母并不是一个特别独特的任务。认为“转换器不是为此而构建的”这一说法是错误的,因为这个任务本质上与要求LLM执行任何任意任务相似。
有人可能会说,当要求LLM写一首关于狗吃作业的诗时,它“不是为此而构建的”,而只是“预测下一个标记”。实际上,拼写一个词并计算其字母与任何其他任务(包括数学运算)一样,都是合法的任务。
所需要的只是一个数据集,使LLM能够记住给定单词中的所有字母,之后它就可以轻松完成任务。
对于LLM来说,记住法国的首都是巴黎与记住“dog”中的字母是d-o-g在概念上没有区别。教授LLMs这个特定任务并不是优先事项,但方法是直接的,如上所示。
PS. 在这些疯狂的时代,保持幽默感对于保持理智很重要。
讨论总结
讨论主要围绕作者声称通过“Black_Strawberry”项目实现了人工通用智能(AGI)展开。评论者们对这一成就表示惊讶、赞赏和怀疑,同时也讨论了发布模型的安全性问题和数据集的潜在用途。讨论中不乏幽默和讽刺,反映了社区对AGI技术的复杂情感。主要观点包括对AGI实现的认可、对模型安全性的担忧、数据集的发布考虑以及对语言模型处理特定任务能力的讨论。
主要观点
👍 作者通过“Black_Strawberry”项目实现了AGI
- 支持理由:展示了AI模型正确拼写单词的能力,证明了项目的有效性。
- 反对声音:有人认为这只是简单的任务,不足以证明AGI的实现。
🔥 对发布模型的安全性表示担忧
- 正方观点:认为发布模型可能带来安全风险,需要谨慎对待。
- 反方观点:有人认为发布数据集是可行的,可以促进研究。
💡 数据集的发布考虑
- 支持理由:发布数据集可以满足研究需求,促进技术发展。
- 反对声音:有人担心数据集的质量和潜在风险。
🤔 语言模型处理特定任务的能力
- 支持理由:模型通过记忆特定任务的标记来执行任务,如拼写和计数字母。
- 反对声音:有人认为这只是简单的任务,不需要复杂的模型。
😂 幽默和讽刺在讨论中的重要性
- 支持理由:幽默和讽刺增加了讨论的趣味性,缓解了紧张的氛围。
- 反对声音:有人认为过于幽默可能会掩盖严肃的技术讨论。
金句与有趣评论
“😂 The absolute madlad actually went and did it”
- 亮点:幽默地表达了对作者成就的惊讶和赞赏。
“🤔 Irresponsible and dangerous projects like this are exactly why we need regulation”
- 亮点:强调了对AI技术进行监管的必要性。
“👀 The shitposting of today, are the discussions of tomorrow”
- 亮点:暗示看似轻松的讨论可能成为未来严肃讨论的基础。
“😂 LOL this dataset is ridiculous. I thought you had a decent dataset for real lmao”
- 亮点:幽默地表达了对数据集质量的怀疑。
“🤔 My god… r/singularity was actually right all along.”
- 亮点:表达了对“r/singularity”正确性的惊讶和困惑。
情感分析
讨论的总体情感倾向是复杂的,既有对AGI实现的惊讶和赞赏,也有对模型安全性和数据集质量的担忧。幽默和讽刺在讨论中起到了缓解紧张氛围的作用,但也可能掩盖了严肃的技术讨论。主要分歧点在于AGI的实际实现程度和发布模型的安全性问题。
趋势与预测
- 新兴话题:数据集的应用和模型训练方法可能会引发后续讨论。
- 潜在影响:对AI技术的监管和安全性讨论可能会进一步加剧,影响相关领域的发展方向。
详细内容:
标题:在 Reddit 引发热议的“Black_Strawberry”AGI 项目
在 Reddit 上,一篇题为“I have achieved AGI with my project Black_Strawberry”的帖子引起了众多用户的关注。该帖子展示了一个关于实现 AGI 的项目,还附上了一张有关单词拼写和字母计数问题的对话截图,并介绍了相关成果。截至目前,帖子获得了大量的点赞和众多评论。
帖子引发的主要讨论方向包括项目的可行性、潜在风险、是否需要监管,以及对这一成果的各种质疑和支持观点。其中的核心问题在于,这样的成果是否真的达到了 AGI 的水平,以及其对社会可能产生的影响。
讨论焦点与观点分析: 有人称赞这是一项了不起的成就,称发帖者是“绝对的狂人”。但也有人认为这是不负责任且危险的项目,呼吁加强监管。比如,用户“Everlier”表示:“像这样不负责任和危险的项目正是我们需要监管的原因。” 有人对项目的真实性提出质疑,认为这只是个骗局,比如“VeterinarianTall7965”就说:“这显然是个骗局。数据集只是一堆随机的 JSON 文件。我敢打赌这个模型只是在记忆预训练语言模型的输出。并不令人印象深刻。” 还有人对项目的实用性和效率提出了看法,像“Mundane_Ad8936”说道:“我欣赏这种幽默,但你所做的只是降低了效率,并没有证明任何我们不知道的东西。”
不过,也有用户从积极的角度看待,认为这或许会带来新的可能性。比如“Inkbot_dev”表示:“受 OP 的独特方法启发,我决定为真正对这个任务感兴趣的人创建一个更实用的解决方案。”
讨论中的共识在于,大家都认为这样的成果需要进一步的审视和探讨。
特别有见地的观点如“Calcidiol”提出的:“为什么一个令牌词汇不能同时包括复合形式,如‘do’+‘g’,以及字母分离形式‘d’‘o’‘g’,还有音节、语音、翻译(如希腊语、德语、世界语、粤语等)形式等等。”丰富了对于令牌化问题的讨论。


感谢您的耐心阅读!来选个表情,或者留个评论吧!