我进行了一个快速测试,以评估量化对 Mistral NeMo 2407 12B instruct 性能的影响。我专注于计算机科学类别,因为仅测试这一类别每个模型就需要20分钟。
| 模型 | 大小 | 计算机科学 (MMLU PRO) |
|---|---|---|
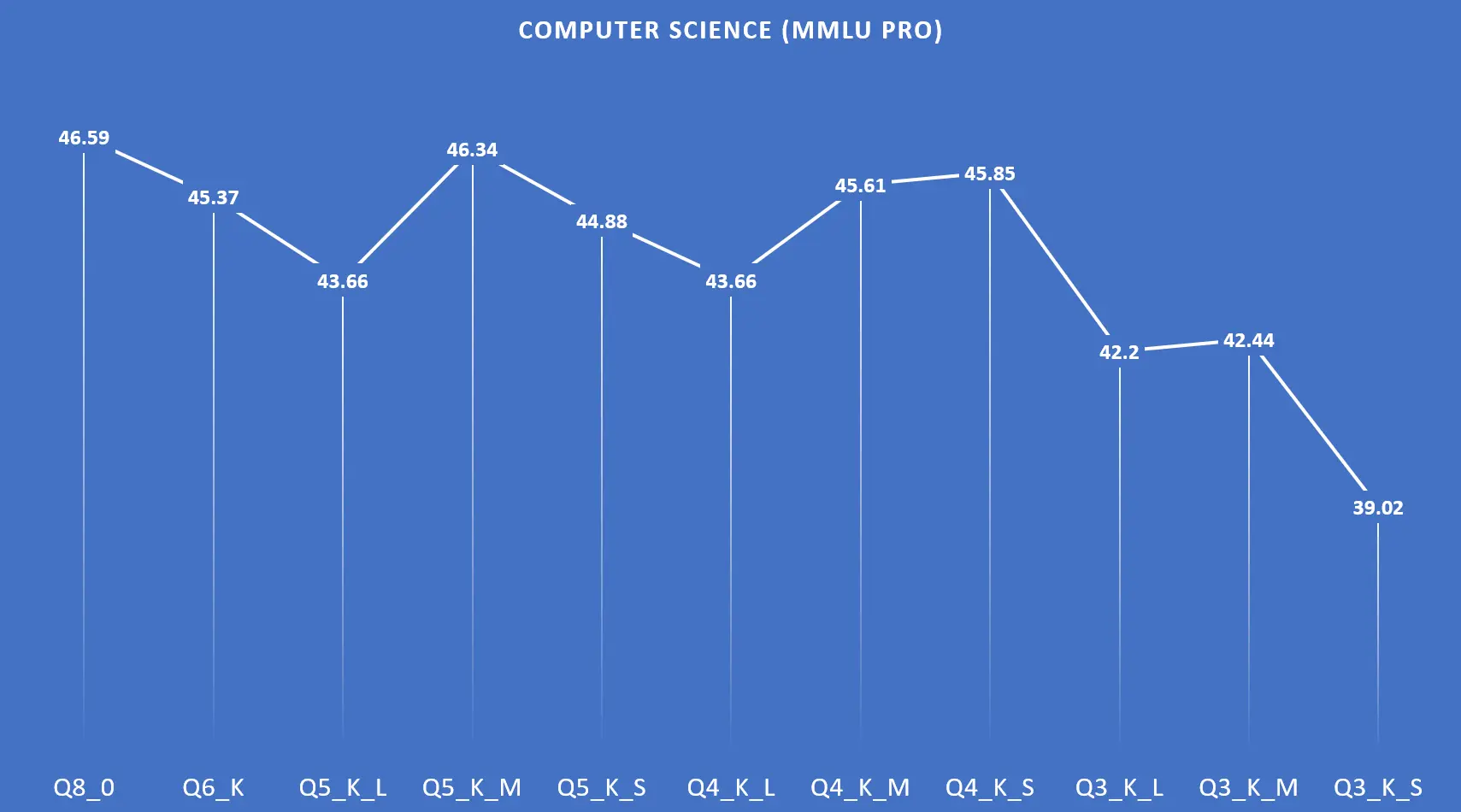
| Q8_0 | 13.02GB | 46.59 |
| Q6_K | 10.06GB | 45.37 |
| Q5_K_L | 9.14GB | 43.66 |
| Q5_K_M | 8.73GB | 46.34 |
| Q5_K_S | 8.52GB | 44.88 |
| Q4_K_L | 7.98GB | 43.66 |
| Q4_K_M | 7.48GB | 45.61 |
| Q4_K_S | 7.12GB | 45.85 |
| Q3_K_L | 6.56GB | 42.20 |
| Q3_K_M | 6.08GB | 42.44 |
| Q3_K_S | 5.53GB | 39.02 |
| — | — | — |
| Gemma2-9b-q8_0 | 9.8GB | 45.37 |
| Mistral Small-22b-Q4_K_L | 13.49GB | 60.00 |
| Qwen2.5 32B Q3_K_S | 14.39GB | 70.73 |
GGUF 模型: https://huggingface.co/bartowski & https://www.ollama.com/
评估工具: https://github.com/chigkim/Ollama-MMLU-Pro
评估配置: https://pastebin.com/YGfsRpyf
讨论总结
本次讨论主要围绕Mistral NeMo 2407 12B GGUF量化模型在计算机科学类别中的性能评估展开。参与者们通过数据分析和经验分享,探讨了不同量化等级(如Q4_K_S、Q5_K_M、Q3_K_S等)对模型性能的影响。讨论中,一些评论者提出了量化等级并非越大越好的观点,并指出了测试中可能存在的随机性和误差。此外,还有关于量化模型在不同上下文长度下的表现、多语言能力的需求以及基线数值的疑问。总体而言,讨论氛围较为技术性,参与者们对量化模型的性能表现和潜在问题进行了深入探讨。
主要观点
- 👍 Q4_K_S 和其他模型的得分高于 Q6_K 和某些 Q5 模型
- 支持理由:量化等级并非越大越好,Q4_K_S 在某些情况下表现更优。
- 反对声音:测试中可能存在随机性和误差,需要多次测试以确保准确性。
- 🔥 测试中可能存在转换过程中的错误
- 正方观点:错误可能影响结果的准确性,特别是在量化过程中。
- 反方观点:需要进一步的技术分析和验证,以确定错误的来源。
- 💡 MMLU 作为单一基准的局限性
- 解释:MMLU 不能全面反映模型的性能,建议进行更多基准测试以获取更多数据。
- 👀 Q3_K_M 模型在测试中表现稳定
- 解释:显示出较好的性能,可能是性能下降的起点。
- 🤔 量化模型的性能下降可能与“脑损伤”现象有关
- 解释:Q3_K_S 模型可能是性能下降的起点,需要进一步研究。
金句与有趣评论
- “😂 Interesting how Q4_K_S and other have a better score than Q6_K and some Q5s. So the Q is not always the bigger the better.”
- 亮点:提出了量化等级并非越大越好的观点,引发了对量化模型性能的深入思考。
- “🤔 Yeah, interesting is a good word for it. It’s likely there is a mistake somewhere during conversion. Could be while creating the GGUF or during inferencing.”
- 亮点:指出了测试中可能存在的转换错误,强调了技术细节的重要性。
- “👀 For some strange reason, the Q4_K_S quanta work very well, sometimes even better than the Q5, or with ridiculous differences.”
- 亮点:对Q4_K_S量化的优异表现感到好奇,提出了进一步探讨的需求。
- “🤔 What’s the fp16 baseline? 44.63? Odd the Quant is higher. Maybe I looked wrong place?”
- 亮点:提出了对基线数值的疑问,引发了关于数据准确性的讨论。
- “👍 Nice work!👍🏻”
- 亮点:简洁明了地表达了对作者工作的认可和鼓励。
情感分析
讨论的总体情感倾向较为中性,主要集中在技术性的分析和探讨上。大多数评论者对量化模型的性能表现表示了兴趣和好奇,同时也指出了测试中可能存在的误差和随机性问题。部分评论者对作者的工作表示了赞赏和鼓励,整体氛围较为友好和建设性。
趋势与预测
- 新兴话题:进一步探讨量化等级对模型性能的影响,特别是Q4_K_S量化的优异表现。
- 潜在影响:对量化模型的研究和应用可能会有更深入的发展,特别是在计算机科学和其他领域中的应用。
详细内容:
标题:关于 Mistral NeMo 2407 12B GGUF 量化评估结果的热门讨论
近日,Reddit 上一篇关于 Mistral NeMo 2407 12B GGUF 量化评估结果的帖子引发了广泛关注。该帖子详细展示了不同量化配置下模型在计算机科学类别中的性能表现,获得了众多用户的点赞和大量评论。
帖子主要内容为作者进行的量化测试,包括不同量化模式下模型的大小和在计算机科学(MMLU PRO)方面的得分。同时,还提供了相关的图片和多个链接,以便读者获取更详细的信息。
讨论焦点主要集中在量化效果的不确定性和复杂性上。有人指出 Q4_K_S 等量化模式的得分比 Q6_K 和一些 Q5 模式更好,认为并非量化数值越大性能就越好。也有人对测试结果表示怀疑,认为可能存在转换过程中的错误或者测试次数不足导致的随机性。还有用户认为 Q3_K_M 表现不错,但同时也提醒不要过于依赖单一的测试结果,因为 MMLU 只是一个基准,不能完全代表实际情况。
有用户分享道:“我在其他任务中也有相同的经历,更大的量化并不总是自动与更好的性能相关联。” 另一位用户则表示:“Q4_K_S 量化模式表现出色有时甚至优于 Q5,差异令人感到惊讶。” 但也有人提出疑问,比如“为什么 L(大型)量化模式比 M 量化模式差?为什么 Q8 与 Q5_K_M 基本相同?”
讨论中的共识在于认识到量化效果的多变性和不能简单根据量化数值判断性能优劣。特别有见地的观点认为,需要进行更多不同随机种子的测试,并且不能仅仅依赖 MMLU 这一个基准。
这次讨论让我们看到了 Mistral NeMo 2407 12B GGUF 量化评估的复杂性和不确定性,也为进一步的研究和测试提供了方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!