讨论总结
本次讨论主要围绕Qwen 2.5模型在Livebench编码类别中的表现展开,涉及多个AI模型的性能比较、技术进步、实际应用等方面。评论者们对Qwen 2.5的优异表现表示赞赏和惊讶,同时也对其他模型的表现进行了讨论。讨论中不乏幽默和质疑的声音,整体氛围积极且充满期待。
主要观点
👍 Qwen 2.5在Livebench编码类别中表现优异
- 支持理由:评论者们普遍认为Qwen 2.5在编码任务中表现出色,甚至超越了GPT-4o和o1-preview。
- 反对声音:部分评论者对数据的真实性表示质疑,认为目前尚未有Qwen2.5 coder 32b版本。
🔥 Qwen 2.5的低参数模型表现出色
- 正方观点:评论者认为低参数模型是巨大的进步,接近“下一代”水平。
- 反方观点:硬件限制导致无法运行高参数模型,但低参数模型已经让作者印象深刻。
💡 Qwen 2.5在实际编程任务中表现突出
- 评论者分享了使用Qwen 2.5编写完整Pacman游戏的经验,认为其表现优于Claude模型。
👀 Qwen 2.5的API将在Hugging Face平台上可用
- 评论者期待在API可用时,能够使用Qwen模型更新其聊天机器人。
🤔 Qwen 2.5在哲学陈述方面表现出色
- 评论者认为Qwen 2.5不仅在编码方面表现优异,还在哲学领域展现了令人印象深刻的创造力。
金句与有趣评论
“😂 ResearchCrafty1804:Qwen nailed it on this release! I hope we have another bullrun next week with competitive releases from other teams”
- 亮点:表达了对Qwen 2.5优异表现的赞赏,并期待其他团队的竞争性发布。
“🤔 Ok-Perception2973:I have to say I am extremely impresssed by Qwen 2.5 72b instruct. Succeeded in some coding tasks that even Claude struggles, such as in debugging a web scrapper on first try…”
- 亮点:分享了个人经验,强调Qwen 2.5在复杂编码任务中的出色表现。
“👀 balianone:Amazing! I hope I can update my chatbot with Qwen when the API is available at https://huggingface.co/spaces/llamameta/llama3.1-405B"
- 亮点:表达了对Qwen 2.5 API的期待,并提供了具体的链接。
“😂 b_e_innovations:Qwen whipsers: "Uh hi lemme just, imma slide in right here, excuse me, pardon me.."”
- 亮点:通过幽默的方式表达了对Qwen 2.5性能的认可和对其未来发展的期待。
“🤔 custodiam99:Not only coding. Qwen 2.5 32b Q_6 was the first local model which was actually able to create really impressive philosophical statements.”
- 亮点:强调Qwen 2.5不仅在编码方面表现优异,还在哲学领域展现了令人印象深刻的创造力。
情感分析
讨论的总体情感倾向积极,评论者们对Qwen 2.5的表现表示赞赏和惊讶。主要分歧点在于对数据真实性的质疑,部分评论者认为目前尚未有Qwen2.5 coder 32b版本。情感氛围中不乏幽默和期待,整体上对AI技术的发展持乐观态度。
趋势与预测
- 新兴话题:Qwen 2.5在不同任务中的全面表现,特别是其在哲学陈述方面的突出表现,可能引发后续讨论。
- 潜在影响:Qwen 2.5的优异表现可能推动AI模型在实际应用中的进一步发展,特别是在编程和哲学领域的应用。
详细内容:
标题:Qwen 2.5 在 Livebench 编码类别中的出色表现引发 Reddit 热议
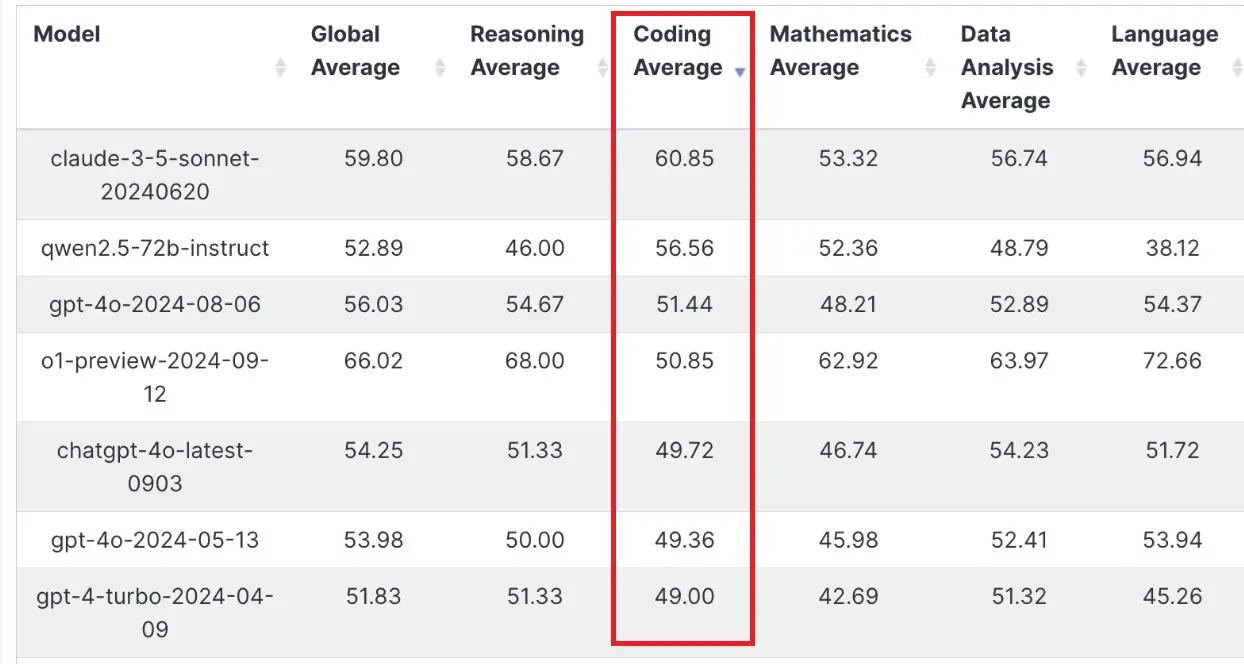
近日,Reddit 上一则关于 Qwen 2.5 在 Livebench 编码类别中表现出色的帖子引发了广泛关注。该帖子包含一张展示不同模型性能指标数据的表格图片,获得了众多用户的点赞和大量评论。
讨论焦点主要集中在 Qwen 2.5 与其他模型的性能对比以及其在实际应用中的表现。有人称赞 Qwen 2.5 在这次发布中表现出色,比如 [ResearchCrafty1804] 表示“Qwen 这次干得漂亮!希望下周其他团队也能有竞争力的发布”。[_raydeStar] 称将其接入 copilot 后效果惊人,速度超快。但也有人对测试的基准提出疑问,如 [pet_vaginal] 问道“用 Python 写一个吃豆人游戏是一个好的基准吗?我认为训练数据集中存在许多变体。”
[ortegaalfredo] 分享了自己的测试经历,称“用‘Write a pacman game in python’指令测试时,qwen-72B 完成了包括幽灵、吃豆人、地图以及从磁盘加载实际.png 文件的精灵等的完整游戏,甚至打败了 Claude 的基本地图且没有幽灵的版本。”这一结果让不少人感到印象深刻,如 [ambient_temp_xeno] 就表示“这确实令人印象深刻”。
对于 Qwen 2.5 的表现,大家观点不一。有人认为它是一个巨大的进步,比如 [u/Uncle___Marty] 称“从低参数模型开始测试,效果超级好,参数越高效果越好,即使是低参数模型也是向前迈出的一大步。”但也有人觉得 Claude 在处理大型复杂代码库方面更胜一筹,如 [SuperChewbacca] 表示“Claude 在通过聊天进行多次迭代处理大型复杂代码库方面仍然更好。”
在这场热烈的讨论中,也有用户提到了模型的使用方式、数据处理等方面的问题。总之,关于 Qwen 2.5 的性能和应用,Reddit 上的讨论展现了其多样性和复杂性,也为人们深入了解 AI 模型的发展提供了更多视角。


感谢您的耐心阅读!来选个表情,或者留个评论吧!