我进行了一个快速测试,以评估量化对Qwen2.5 14B instruct性能的影响。我仅关注计算机科学类别,因为仅测试这一类别每个模型就需要40分钟。
| 模型 | 大小 | 计算机科学(MMLU PRO) |
|---|---|---|
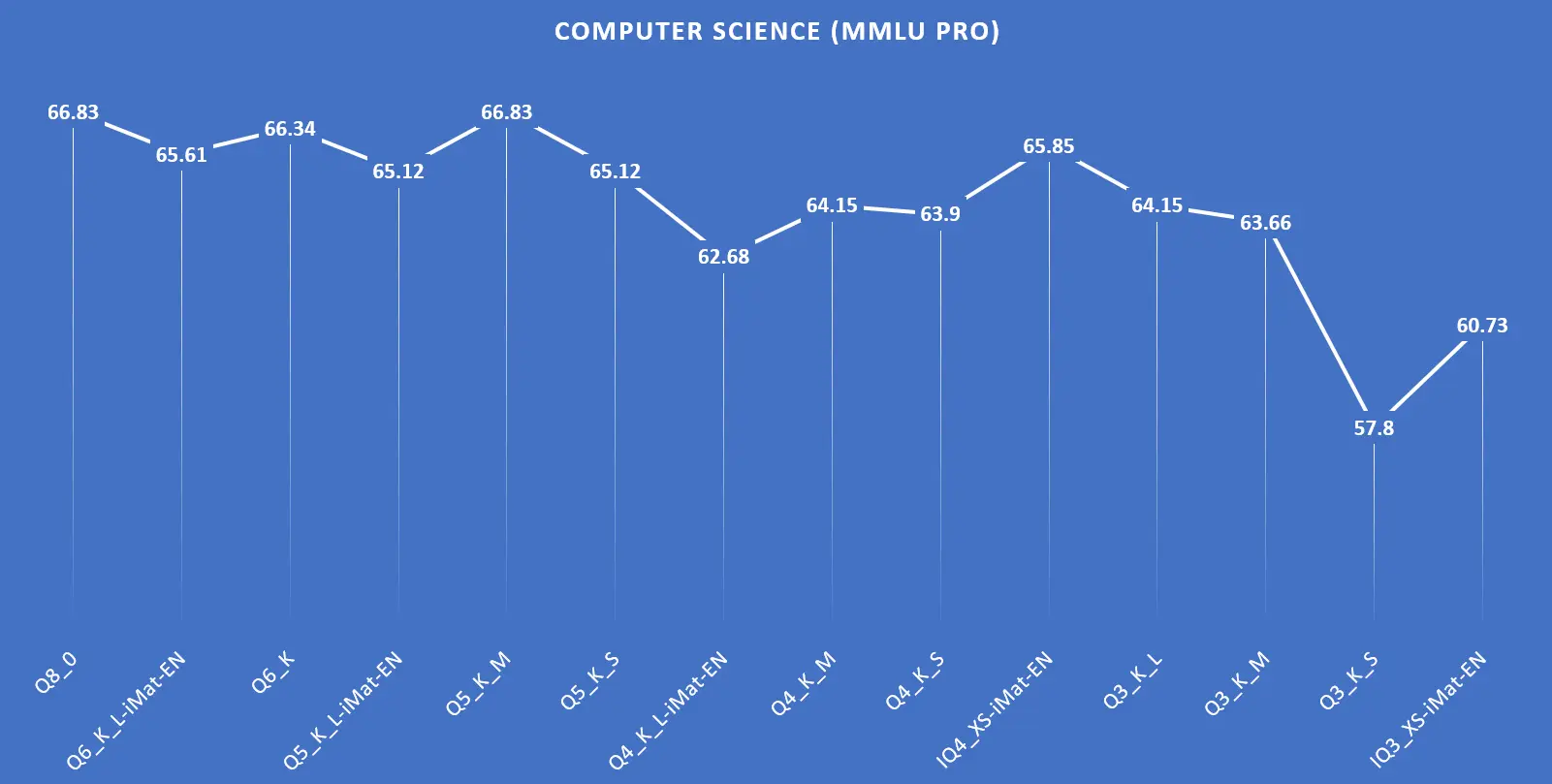
| Q8_0 | 15.70GB | 66.83 |
| Q6_K_L-iMat-EN | 12.50GB | 65.61 |
| Q6_K | 12.12GB | 66.34 |
| Q5_K_L-iMat-EN | 10.99GB | 65.12 |
| Q5_K_M | 10.51GB | 66.83 |
| Q5_K_S | 10.27GB | 65.12 |
| Q4_K_L-iMat-EN | 9.57GB | 62.68 |
| Q4_K_M | 8.99GB | 64.15 |
| Q4_K_S | 8.57GB | 63.90 |
| IQ4_XS-iMat-EN | 8.12GB | 65.85 |
| Q3_K_L | 7.92GB | 64.15 |
| Q3_K_M | 7.34GB | 63.66 |
| Q3_K_S | 6.66GB | 57.80 |
| IQ3_XS-iMat-EN | 6.38GB | 60.73 |
| — | — | — |
| Mistral NeMo 2407 12B Q8_0 | 13.02GB | 46.59 |
| Mistral Small-22b-Q4_K_L | 13.49GB | 60.00 |
| Qwen2.5 32B Q3_K_S | 14.39GB | 70.73 |
静态GGUF: https://www.ollama.com/
仅使用英语数据集校准的iMatrix GGUF(-iMat-EN): https://huggingface.co/bartowski
我担心像这样的iMatrix GGUF会损害模型的多语言能力,因为校准数据集仅使用英语。是否有更多专业知识的人可以解释这一点?谢谢!!
评估工具: https://github.com/chigkim/Ollama-MMLU-Pro
评估配置: https://pastebin.com/YGfsRpyf
讨论总结
本次讨论主要围绕 Qwen2.5 14B 模型的量化评估展开,重点关注不同量化级别对模型在计算机科学类别中的性能表现。参与者通过对比不同量化级别的模型(如 Q8_0、Q6_K、Q5_K 等)在 MMLU PRO 测试中的得分,探讨了量化对模型性能的影响。此外,讨论还涉及了 iMatrix 校准对多语言能力的影响,并引用了专家的解释,说明 iMatrix 校准不会显著改变模型的多语言能力。讨论中还提到了模型在不同硬件平台上的表现,以及量化模型的选择和优化问题。总体而言,讨论氛围较为技术性,参与者对量化模型的性能和多语言能力表现出了高度关注。
主要观点
👍 Qwen2.5 14B 模型的不同量化级别在计算机科学类别中的性能表现有所不同。
- 支持理由:通过 MMLU PRO 测试得分对比,不同量化级别的模型性能差异明显。
- 反对声音:部分评论者对测试结果的误差范围表示质疑。
🔥 iMatrix 校准不会显著改变模型的多语言能力。
- 正方观点:iMatrix 校准通过轻微调整缩放因子,确保关键权重在反量化时接近其原始值。
- 反方观点:有评论者担心仅使用英语数据集进行校准可能会损害模型的多语言能力。
💡 IQ4_XS 模型在 CPU 上表现出色,适合在较弱机器上运行。
- 解释:评论者认为 IQ4_XS 是一个性能和资源占用的理想平衡点。
💡 量化模型的性能表现因任务而异,选择合适的模型取决于具体需求。
- 解释:不同量化级别的模型在不同任务中的表现可能有所不同,需要根据具体需求进行选择。
💡 需要一个平台来汇总和比较不同量化模型的基准测试结果。
- 解释:评论者认为现有的测试工具和平台不足以全面评估量化模型的性能。
金句与有趣评论
“😂 FreedomHole69:IQ4_XS is such a great sweet spot.”
- 亮点:强调了 IQ4_XS 模型在性能和资源占用方面的理想平衡。
“🤔 AaronFeng47:I am worried iMatrix GGUF like this will damage the multilingual ability of the model, since the calibration dataset is English only.”
- 亮点:表达了对 iMatrix 校准可能损害多语言能力的担忧。
“👀 VoidAlchemy:Loving these community led benchmarks u/AaronFeng47 ! Thanks for pointing us all towards
chigkim/Ollama-MMLU-Pro!”- 亮点:赞赏社区基准测试的贡献,并感谢工具推荐。
“🤔 What_Do_It:Does anyone know if these benchmarks have an established margin of error?”
- 亮点:对量化模型基准测试结果的误差范围提出质疑。
“😂 Very_Large_Cone:Would love to see you make a scatter plot of model size in GB vs score.”
- 亮点:建议通过数据可视化更直观地展示模型性能。
情感分析
讨论的总体情感倾向较为中性,参与者对量化模型的性能和多语言能力表现出了高度关注。主要分歧点在于 iMatrix 校准对多语言能力的影响,部分评论者担心仅使用英语数据集进行校准可能会损害模型的多语言能力,而另一部分评论者则认为 iMatrix 校准不会显著改变多语言表现。此外,讨论中还存在对量化模型基准测试结果的误差范围的质疑。
趋势与预测
- 新兴话题:量化模型在不同硬件平台上的表现,以及量化模型的选择和优化问题。
- 潜在影响:随着量化技术的不断发展,量化模型在资源受限环境中的应用将更加广泛,对多语言处理能力的优化也将成为研究重点。
详细内容:
标题:关于 Qwen2.5 14B GGUF 量化评估结果的热门讨论
在 Reddit 上,一篇关于 Qwen2.5 14B GGUF 量化评估结果的帖子引发了广泛关注。该帖子详细列出了不同量化方式下模型在计算机科学类别中的性能表现,获得了众多用户的热烈讨论。点赞数和评论数众多,主要的讨论方向包括不同量化方式的优劣比较、对多语言能力的影响以及实际应用中的性能差异等。
在讨论中,有人认为 IQ4_XS 是一个不错的选择;也有人在比较 Qwen2.5 与 llama3.1 8b 等模型,并讨论如何根据任务需求做出选择。有用户表示 Imatrix 校准在量化过程中不会显著改变不同语言的整体性能,只是对缩放因子进行了微调。但也有人担心 iMatrix GGUF 这种仅使用英语校准数据集的方式会损害模型的多语言能力。
例如,有用户分享道:“作为一名经常尝试小型本地模型的人,我发现即使是最新的模型,在使用第二语言交流时表现也不尽如人意。”还有用户指出:“在 8 位量化中,使用多语言的 iMatrix 总体上表现更好。”
同时,关于量化方式对不同模型性能的具体影响也存在争议。有人发现某些理论上更优的量化方式实际表现不佳,有人计划用脚本将 iMatrix gguf 替换为静态量化,还有人对测试结果的准确性和可重复性提出了疑问。
总之,这场关于 Qwen2.5 14B GGUF 量化评估结果的讨论,充分展示了用户对于模型性能和技术细节的关注与思考,为相关领域的研究和应用提供了有价值的参考。但关于模型量化的最佳方式以及对多语言能力的影响等问题,仍有待进一步的探讨和研究。


感谢您的耐心阅读!来选个表情,或者留个评论吧!