这是Qwen2.5 7B Chat模型,不是coder
| 模型 | 大小 | 计算机科学(MMLU PRO) |
|---|---|---|
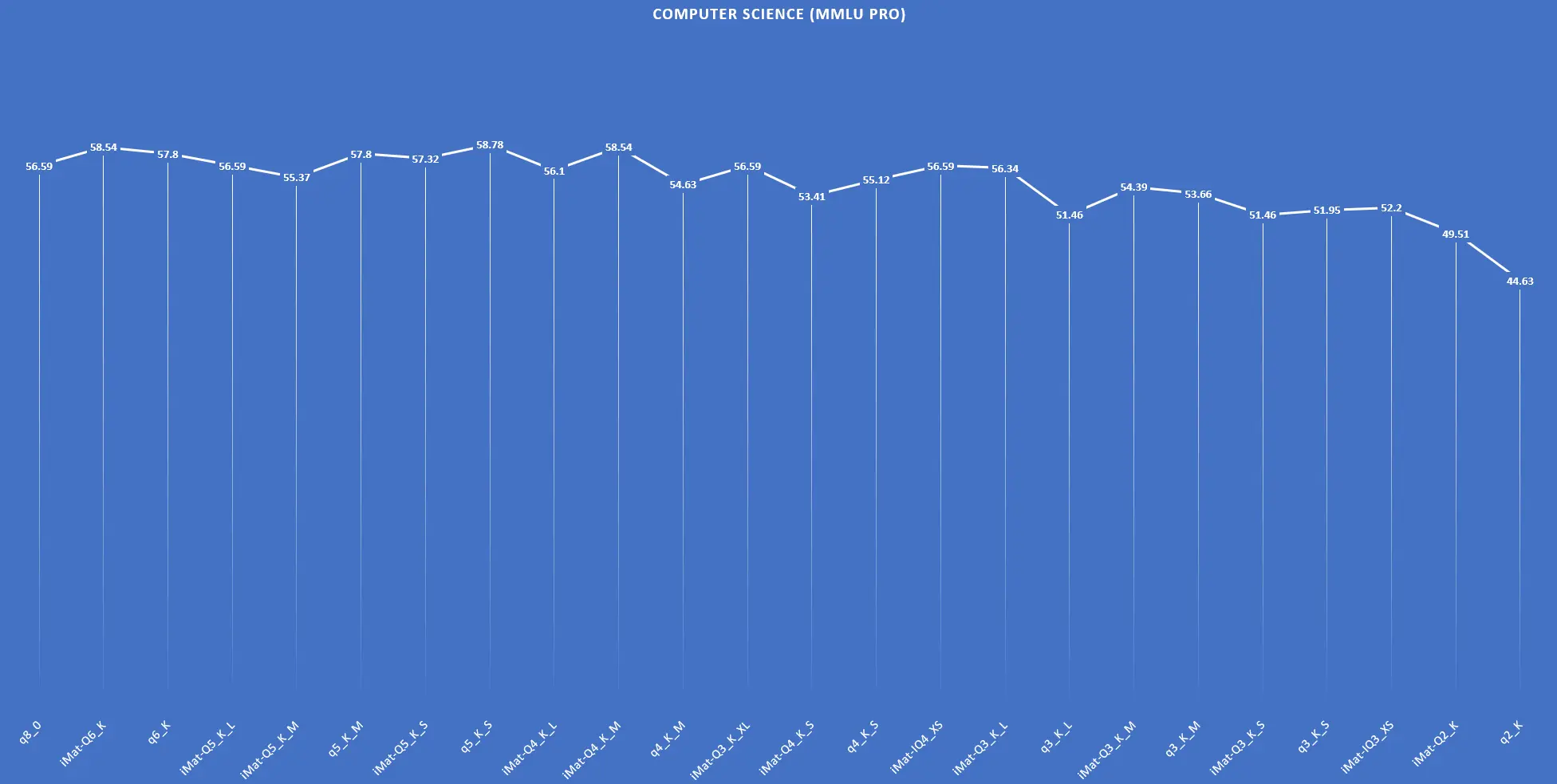
| q8_0 | 8.1 GB | 56.59 |
| iMat-Q6_K | 6.3 GB | 58.54 |
| q6_K | 6.3 GB | 57.80 |
| iMat-Q5_K_L | 5.8 GB | 56.59 |
| iMat-Q5_K_M | 5.4 GB | 55.37 |
| q5_K_M | 5.4 GB | 57.80 |
| iMat-Q5_K_S | 5.3 GB | 57.32 |
| q5_K_S | 5.3 GB | 58.78 |
| iMat-Q4_K_L | 5.1 GB | 56.10 |
| iMat-Q4_K_M | 4.7 GB | 58.54 |
| q4_K_M | 4.7 GB | 54.63 |
| iMat-Q3_K_XL | 4.6 GB | 56.59 |
| iMat-Q4_K_S | 4.5 GB | 53.41 |
| q4_K_S | 4.5 GB | 55.12 |
| iMat-IQ4_XS | 4.2 GB | 56.59 |
| iMat-Q3_K_L | 4.1 GB | 56.34 |
| q3_K_L | 4.1 GB | 51.46 |
| iMat-Q3_K_M | 3.8 GB | 54.39 |
| q3_K_M | 3.8 GB | 53.66 |
| iMat-Q3_K_S | 3.5 GB | 51.46 |
| q3_K_S | 3.5 GB | 51.95 |
| iMat-IQ3_XS | 3.3 GB | 52.20 |
| iMat-Q2_K | 3.0 GB | 49.51 |
| q2_K | 3.0 GB | 44.63 |
| — | — | — |
| llama3.1-8b-Q8_0 | 8.5 GB | 46.34 |
| glm4-9b-chat-q8_0 | 10.0 GB | 51.22 |
| Mistral NeMo 2407 12B Q5_K_M | 8.73 GB | 46.34 |
| Mistral Small-Q4_K_M | 13.34GB | 56.59 |
| Qwen2.5 14B Q4_K_S | 8.57GB | 63.90 |
| Qwen2.5 32B Q4_K_M | 18.5GB | 71.46 |
平均分数:
静态 53.98111111
iMatrix 54.98666667
静态 GGUF: https://www.ollama.com/
iMatrix 校准 GGUF 使用英语数据集(iMat-): https://huggingface.co/bartowski
评估工具: https://github.com/chigkim/Ollama-MMLU-Pro
评估配置: https://pastebin.com/YGfsRpyf
讨论总结
本次讨论主要围绕Qwen2.5 7B Chat模型的量化评估结果展开,特别是在计算机科学(MMLU PRO)领域的性能表现。社区成员对Qwen2.5系列模型的优异表现感到兴奋,认为其在同尺寸模型中达到了最先进(SOTA)水平。讨论中涉及了不同量化级别对模型性能的影响,以及量化过程中可能出现的“脑损伤”现象。此外,社区成员还对模型的实际应用表现进行了探讨,并对其他模型的性能进行了比较。整体讨论氛围积极,大家对Qwen团队的发布表示赞赏,并期待开放权重社区中的其他公司也能在接下来的几周内更新他们的模型,以超越Qwen。
主要观点
👍 Qwen2.5 7B模型在特定基准测试中表现出色,被认为是同尺寸模型中的最先进(SOTA)。
- 支持理由:Qwen2.5系列的其他模型在OP的基准测试中也表现出类似的趋势。
- 反对声音:无明显反对声音,但有讨论其他模型可能在未来超越Qwen。
🔥 量化过程中可能出现“脑损伤”现象,影响模型性能。
- 正方观点:量化级别与性能之间存在逐渐下降的趋势,而非明显的断崖式下降。
- 反方观点:有评论者认为单一样本可能不足以全面反映问题,建议增加样本数量。
💡 Qwen2.5 32B Q4_K_M模型在计算机科学领域的评分最高,达到71.46。
- 解释:不同模型的评分与其大小(GB)之间存在一定的关联性,但并非绝对。
💡 选择合适的模型对结果有重要影响。
- 解释:有评论者指出Qwen2.5 14b IQ4_XS-iMat-EN在同一测试中表现更佳,得分更高。
💡 电力成本和评估时间成本是进行全面评估的限制因素。
- 解释:有评论者提到电力成本和运行所有这些量化的评估需要很长时间,每个量化一个样本就足够发现脑损伤了。
金句与有趣评论
“😂 ResearchCrafty1804:Qwen2.5 7B is SOTA for its size (and slightly bigger even).”
- 亮点:直接指出Qwen2.5 7B模型在同尺寸模型中的领先地位。
“🤔 Maykey:q8_0 shows surprisingly bad results”
- 亮点:简洁明了地指出了模型在特定量化版本下的性能问题。
“👀 Professional-Bear857:Was the Q4K_M for the 32b model an imatrix quant?”
- 亮点:直接询问模型的量化技术,引发进一步讨论。
“😂 swagonflyyyy:Those 18T tokens are really paying off.”
- 亮点:对模型性能的积极评价,强调了tokens数量的重要性。
“🤔 Mart-McUH:The catch is that it is probably optimized for benchmarks. That said it is still great model, just don’t expect it to be so much better in real use case.”
- 亮点:对模型性能的客观评价,提醒读者注意实际应用中的表现。
情感分析
讨论的总体情感倾向积极,社区成员对Qwen2.5系列模型的优异表现感到兴奋和赞赏。主要分歧点在于量化级别对模型性能的影响,以及量化过程中可能出现的“脑损伤”现象。部分评论者认为单一样本可能不足以全面反映问题,建议增加样本数量。此外,电力成本和评估时间成本也是讨论中提到的限制因素。
趋势与预测
- 新兴话题:可能引发后续讨论的新观点包括其他模型的性能比较,如arcee-ai/Llama-3.1-SuperNova-Lite模型的评估,以及Qwen2.5 14B与DeepSeek-V2-Lite (16B MoE)的比较。
- 潜在影响:对相关领域或社会的潜在影响包括推动本地大型语言模型(LLM)社区的快速发展,以及促进开放权重社区中的其他公司更新他们的模型,以提升整体性能。
详细内容:
标题:Qwen2.5 7B Chat 模型量化评估结果引发Reddit热议
近日,Reddit上一篇关于Qwen2.5 7B Chat模型量化评估结果的帖子引发了众多关注。该帖子详细列举了不同模型的尺寸、在计算机科学领域(MMLU PRO)的得分情况,并配有相关图表。截至目前,帖子已获得[具体点赞数和评论数]的高关注度。
讨论主要围绕Qwen2.5系列模型的性能表现、与其他模型的对比以及在实际应用中的效果等方面展开。
有人认为,根据这个基准,Qwen2.5 7B在其尺寸范围内表现卓越,甚至超越了同尺寸的其他模型。还有人对不同模型的性能排序进行了梳理。
例如,有人分享道:“Qwen2.5 32B Q4_K_M模型的性能最为出色,得分高达71.46。而q8_0的结果却出人意料地差。” 也有人提到:“5_K_S和4_K_M在众多模型中处于领先地位。”
同时,对于Qwen2.5系列模型,也存在一些不同的看法。有人认为其可能是针对基准测试进行了优化,在实际使用中未必有如此出色的表现。
还有人提出疑问,比如为何在聊天模型上使用编码任务而非编码者模型,以及为何某些模型的链接无法找到等问题。
不过,大多数用户对Qwen2.5系列模型的表现给予了肯定,认为其在解决高级数学、推理和编码等方面表现良好。
总之,这次关于Qwen2.5 7B Chat模型量化评估结果的讨论,充分展现了大家对该模型的关注和期待,也为模型的进一步发展和应用提供了有价值的参考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!