你好,localllama!
受到[Qwen2.5 14B GGUF](https://www.reddit.com/r/LocalLLaMA/comments/1flqwzw/qwen25_14b_gguf_quantization_evaluation_results/)验证结果的启发,我决定在一个我一直很好奇的多语言设置中进行一个有趣的模型量化实验。我想与大家分享这些结果。
本次实验主要关注两个关键问题:
- 多语言iMatrix真的能提高日语性能吗?
- L和FP16量化变体实际上有效吗?
简要总结结果:
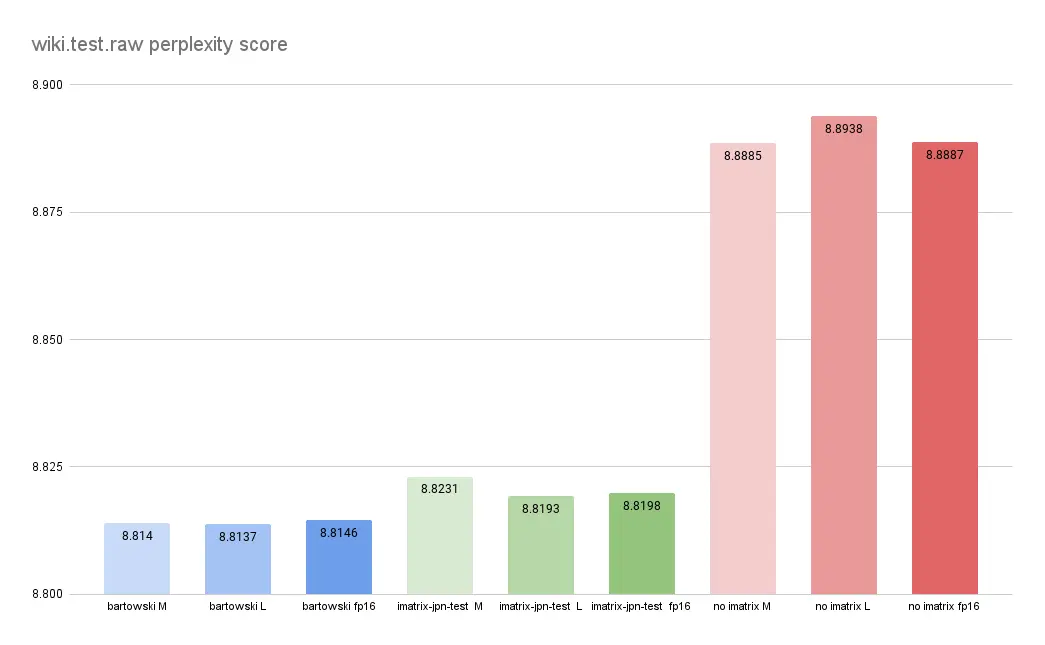
- 使用多语言iMatrix提高了日语困惑度分数。
- L和FP16量化显示出良好的结果,尤其是在日语数据上。
然而,对英语性能有细微影响…
查看这些图表以获取详细数据和分析结果:
本次实验中使用的文件和详细解释已上传到这个Hugging Face仓库:https://huggingface.co/dahara1/imatrix-jpn-test
请在评论中分享你的想法和进一步实验的建议!你对这些结果有什么看法?你认为在其他语言或模型上是否也能达到类似的效果?
讨论总结
本次讨论主要围绕一个关于模型量化的实验展开,重点探讨了多语言iMatrix对日语性能的影响以及L和FP16量化变体的有效性。实验结果显示,使用多语言iMatrix显著提升了日语的困惑度得分,而L和FP16量化在日语数据上表现良好。然而,实验也对英语性能产生了细微影响。讨论中,参与者提出了进一步实验的建议,包括使用更多的量化和iMatrix数据集,以及增加输入块的数量。此外,还讨论了生成iMatrix文件所需的时间和硬件要求,以及GPU处理速度对实验结果的影响。总体而言,讨论氛围积极,参与者对实验结果表示赞赏,并提出了有价值的建议和见解。
主要观点
👍 多语言iMatrix确实提高了日语的困惑度得分
- 支持理由:实验数据和图表显示,使用iMatrix的模型在日语数据上的困惑度得分显著低于未使用iMatrix的模型。
- 反对声音:无明显反对声音,但有讨论提到对英语性能的细微影响。
🔥 L和FP16量化在日语数据上表现良好
- 正方观点:实验结果显示,L和FP16量化在日语数据上的表现优于其他量化方法。
- 反方观点:无明显反方观点,但有讨论提到需要进一步实验以确保结论的可靠性。
💡 建议进行更多量化和iMatrix数据集的测试
- 解释:参与者建议增加实验次数和数据集,以确保结论的可靠性,并避免因偶然性导致的错误结论。
💡 生成iMatrix文件需要较长时间,建议寻求帮助以加快进程
- 解释:讨论中提到生成iMatrix文件的时间成本较高,建议通过合作或优化方法来缩短时间。
💡 GPU处理速度显著影响实验效率,建议使用GPU进行处理
- 解释:参与者指出,GPU处理速度对实验效率有显著影响,建议使用高性能GPU来加速实验进程。
金句与有趣评论
“😂 Chromix_:You might want to test with more quants, imatrix datasets and number of input chunks for imatrix, to ensure that you’re not arriving at conclusions when it was just a lucky dice-roll.”
- 亮点:强调了增加实验次数和数据集的重要性,以确保结论的可靠性。
“🤔 noneabove1182:添加日语数据对模型性能的提升微乎其微,但值得进一步探索。”
- 亮点:提出了对日语数据提升效果的谨慎态度,并建议进一步探索。
“👀 dahara111:Translation work requires high performance in both languages, so training must be balanced, which is difficult.”
- 亮点:指出了翻译任务中平衡两种语言性能的挑战性。
情感分析
讨论的总体情感倾向积极,参与者对实验结果表示赞赏,并提出了有价值的建议和见解。主要分歧点在于对日语数据提升效果的谨慎态度,以及对进一步实验的必要性。可能的原因包括实验次数不足和数据集的多样性。
趋势与预测
- 新兴话题:进一步实验和数据集的扩展,以及对其他语言和模型的测试。
- 潜在影响:对多语言模型性能的提升和量化方法的优化,可能对相关领域的研究和应用产生积极影响。
详细内容:
标题:关于提升日语性能的模型量化实验在 Reddit 引发热议
最近,Reddit 上有一个关于模型量化实验的帖子备受关注,获得了众多点赞和大量评论。帖子的主题是“Boosting Japanese Performance? Testing Multilingual iMatrix and L/fp16 Quants Effects on Gemma-2-9b-it”,作者受 Qwen2.5 14B GGUF 的验证结果启发,进行了一个聚焦于多语言设置的模型量化有趣实验,并分享了结果。
这个实验主要关注两个关键问题:一是多语言 iMatrix 是否真的能提升日语性能;二是 L 和 FP16 量化变化是否真的有效。结果显示,使用多语言 iMatrix 提高了日语的困惑度得分,L 和 FP16 量化也表现不错,特别是在日语数据上,但对英语性能有细微影响。作者还提供了详细数据和分析结果的图表,相关文件和详细解释上传至了https://huggingface.co/dahara1/imatrix-jpn-test。
讨论焦点与观点分析: 有人建议测试更多的量化、iMatrix 数据集和输入块的数量,以确保结论不是偶然得出的。有人表示自己用 3090 显卡能很快生成 iMatrix 文件,并指出任何 30 系列显卡都应该能较快完成,还提到了硬件和软件设置的要求。有人认为应该多样化数据集,并建议模型创建者上传用于 iMatrix/校准步骤的样本数据集。有人还提出进行 KLD 测试,因为它能展示比困惑度更多的信息。有人在自己的数据集中得出了相同结论,甚至在对日语和中文轻小说翻译进行微调的模型上进行了 iMatrix 操作。
总体而言,大家对这次实验的结果表示了关注和思考,也提出了很多有价值的建议和想法,为进一步的研究提供了方向。你对这些结果有什么看法?你认为在其他语言或模型上能达到类似效果吗?


感谢您的耐心阅读!来选个表情,或者留个评论吧!