大家好,
我正在考虑为我的工作站升级内存,需要一些建议。当前配置:
- CPU: Ryzen 9 7900
- GPU: RTX 4090
- RAM: 32GB (16x2) Kingston 4800 MHz DDR5
- 主板: Asus ProArt X670E Creator WiFi
我使用LLaMA3-8B_Q4模型在不同RAM速度(4000, 4800, 5200, 5600 MHz)下运行了llama-bench 5次,并附上了平均结果。
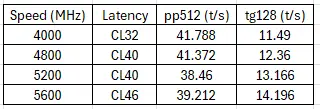
似乎,提示处理更倾向于低延迟,而令牌生成更倾向于RAM速度。 我最初计划升级到192 GB (48x4),但我听说这可能会导致速度显著下降(降至3600 MHz!)。有人能验证这些发现吗?
我的目标是本地运行70/120B+模型,并进行一些GPU卸载。
问题:
- 对于更大的模型,RAM速度会有影响吗?
- 如果是,7000+ MHz的速度能快多少?
- 有人成功运行192 GB而没有显著的速度损失吗?
- 你会优先考虑RAM速度还是延迟?
讨论总结
本次讨论主要围绕内存速度和延迟对大型语言模型(LLMs)性能的影响展开。发帖者分享了在不同内存速度下的测试结果,并提出了关于内存速度对大模型性能影响的疑问。评论者们从多个角度进行了深入讨论,包括内存配置、处理器线程数、GPU 卸载、内存带宽和 Infinity Fabric 总线的影响。讨论中既有技术细节的分享,也有对未来优化方向的建议。总体而言,讨论氛围较为专业,涉及多个技术层面的探讨。
主要观点
👍 内存速度和延迟对LLMs的性能有影响
- 支持理由:测试数据显示,内存速度增加时延迟也在增加,但性能指标没有明显变化。
- 反对声音:有人认为延迟对性能影响不大,应关注总内存带宽。
🔥 2D2R(双通道双列)内存配置对内存控制器来说非常困难
- 正方观点:这种配置增加了内存控制器的负担,可能导致性能下降。
- 反方观点:有人成功运行了 192 GB 内存而没有显著速度损失,但稳定性测试存在疑问。
💡 提示处理(Prompt Processing)更倾向于低延迟,而令牌生成(Token Generation)更倾向于高内存速度
- 解释:测试结果表明,提示处理在低延迟下表现更好,而令牌生成在高内存速度下表现更好。
🚀 增加处理器线程数可以显著提高提示处理的性能,但对令牌生成的提升有限
- 解释:线程数的增加对提示处理有显著加速效果,但对令牌生成的影响较小。
🌐 内存速度的提升对某些性能指标没有显著影响
- 解释:测试数据显示,内存速度的提升并未带来明显的性能提升,可能受限于其他硬件因素。
金句与有趣评论
“😂 Wrong-Historian:Yes, 2 dimms per channel is a lot harder for the memory controller.”
- 亮点:强调了内存配置对内存控制器的挑战。
“🤔 Wrong-Historian:Prompt processing favours lower latency while token generation favours ram speed.”
- 亮点:总结了提示处理和令牌生成对内存速度和延迟的不同需求。
“👀 trithilon:Thats a huge jump, clearly you were limited by CPU - going from 63 t/s on 8 threads to 257 t/s on 32 fpr pp512.”
- 亮点:指出了处理器线程数对提示处理性能的显著影响。
“💡 vorwrath:Latency is basically irrelevant, you just want the highest total memory bandwidth.”
- 亮点:提出了延迟对性能影响不大的观点,强调了总内存带宽的重要性。
“🔍 marclbr:在 AMD 平台上,内存带宽受限于 Infinity Fabric 总线。”
- 亮点:指出了 AMD 平台内存带宽的限制因素。
情感分析
讨论的总体情感倾向偏向于技术性和专业性,评论者们对硬件配置和性能优化进行了深入探讨。主要分歧点在于内存速度和延迟对性能的具体影响,以及不同硬件配置下的最佳优化策略。可能的原因包括硬件平台的差异、内存控制器的限制以及测试方法的不同。
趋势与预测
- 新兴话题:未来可能会进一步探讨如何在 AMD 平台上优化内存带宽和 Infinity Fabric 总线,以及如何通过 GPU 卸载提升性能。
- 潜在影响:对硬件配置和性能优化的深入讨论可能会影响用户在选择和升级硬件时的决策,尤其是在运行大型语言模型时。
详细内容:
《Reddit 热议:内存速度和延迟对 LLM 模型性能的影响》
在 Reddit 上,有一则关于内存速度和延迟对大语言模型(LLM)性能影响的讨论引起了广泛关注。原帖作者考虑给自己的工作站升级内存,并分享了不同内存速度下的基准测试结果。该帖获得了众多用户的积极参与,评论数众多。
主要讨论方向集中在内存速度和延迟对 LLM 性能的具体影响,以及在不同硬件配置下如何优化性能。
核心问题包括:内存速度对大型模型是否重要、在更高频率下能提升多少速度、能否成功运行 192GB 内存而不显著降低速度,以及是否应优先考虑内存速度以降低延迟。
有人认为,提示处理更倾向于低延迟,而令牌生成更青睐内存速度。也有人指出,2 个内存模块每个通道对于内存控制器来说难度较大,甚至大容量的双 rank 内存模块也有困难。还有用户提到,对于像 IQ3 这样的量化,需要比 Q4 或 Q8 更多的 CPU 功率来饱和内存。并且,使用过多或过少的线程,或未有效分配负载,会导致线程开销从而减慢令牌生成。
有人表示,平均锐龙在 1:1 内存控制器模式下,无法做到超过 6000 - 6200 MT 的速度,因此实际上没有必要追求更高的速度。并且,在 AMD 平台上,最大内存带宽受到 Infinity Fabric 总线的限制。
有用户通过实际测试发现,从 8 线程的 63 t/s 到 32 线程的 257 t/s,性能有了巨大提升,表明之前可能受到了 CPU 的限制。还有用户分享,在 DDR5 6800 频率下的测试结果。
总之,这场讨论展现了内存性能与 LLM 模型运行之间复杂的关系,为相关硬件配置和优化提供了有价值的参考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!