讨论总结
本次讨论主要围绕GPT-4o-mini与其他开源大型语言模型(SLMs)在30个多样化任务中的表现进行。讨论内容涵盖了模型的微调效果、参数大小、模型添加、性能比较等多个方面。部分评论者提出了对模型参数信息的质疑,建议提高信息透明度和准确性。此外,讨论中还涉及了不同模型在微调任务中的表现,如GPT-4o-mini在微调后的性能提升有限,而Gemma系列模型的微调效果也引起了关注。总体而言,讨论氛围偏向技术探讨,旨在优化模型性能和选择最适合任务的模型。
主要观点
👍 建议在对比分析中添加Gemma 2 9b和Qwen 2.5 7b两个模型
- 支持理由:这两个模型在某些任务中表现出色,值得加入对比测试。
- 反对声音:Gemma 2 9b的某些变体在之前的测试中表现未达预期。
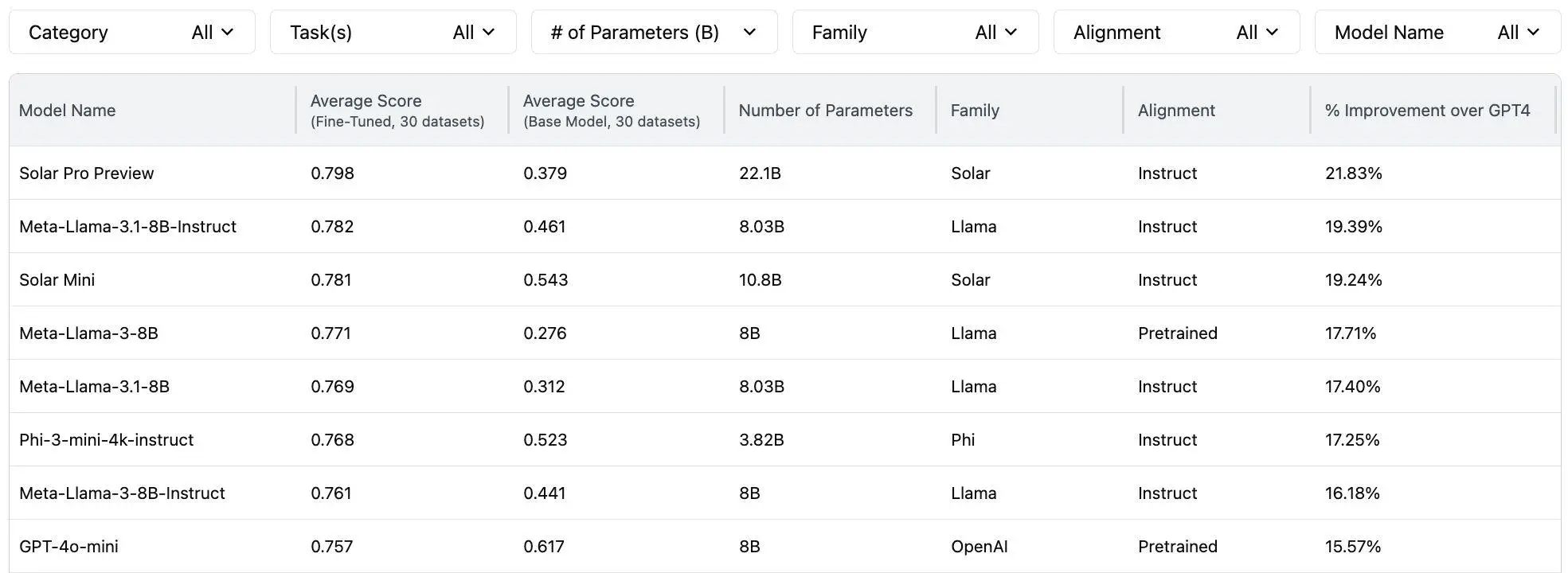
🔥 GPT-4o-mini的参数大小最初被认为是8B,但这一信息可能存在误导性
- 正方观点:建议更新相关信息,以避免混淆。
- 反方观点:不应随意捏造事实,而应提供准确的信息。
💡 GPT-4o-mini在未微调前表现最强,但微调后的提升有限
- 解释:尽管GPT-4o-mini在未微调前表现出色,但经过微调后,其性能提升有限,最终仅处于中等水平。
🤔 评论者质疑帖子中提到的模型是“overfit”而非“fine-tuned”
- 解释:评论者认为这些模型在特定任务上表现相似,可能是因为过度适应了这些任务。
📊 Gemma-2-27b模型在Gemma系列中表现最差,可能不适合微调
- 解释:通过数据对比,Gemma-2-27b模型在预训练和指令调整中的性能变化百分比均为负值。
金句与有趣评论
“😂 SiliconSynapsed:We’ve updated the leaderboard to remove the param count on 4o-mini as many felt it was misleading to assume 8B params. Mea culpa!”
- 亮点:作者承认并修正了参数信息的误导性。
“🤔 EmilPi:Please correct me, if I am wrong, but this looks not like fine-tuned, but like overfit…”
- 亮点:评论者对模型的微调效果提出了质疑。
“👀 asankhs:We had also recently done some benchmarking for fine-tuning gpt-4o-mini, gemini-flash-1.5 and llama-3.1-8b on the same dataset but our experience was that gpt-4o-mini was actually the best and easiest to fine-tune.”
- 亮点:作者分享了实际微调测试的经验,指出GPT-4o-mini表现最佳。
情感分析
讨论的总体情感倾向偏向中性,主要集中在技术探讨和模型性能分析上。部分评论者对模型的参数信息和微调效果提出了质疑,但整体氛围较为理性,旨在通过数据和实验结果进行客观分析。争议点主要集中在模型参数信息的准确性和微调效果的真实性上。
趋势与预测
- 新兴话题:未来可能会围绕更多模型的微调效果和参数信息进行深入讨论,特别是新加入的Gemma 2 9b和Qwen 2.5 7b模型。
- 潜在影响:讨论结果可能会影响用户在选择和使用模型时的决策,特别是在微调任务中,如何选择最适合的模型将成为关键。
详细内容:
《关于 GPT-4o-mini 与顶级开源 SLMs 在 30 项不同任务中的比较引发的热议》
近日,Reddit 上一篇关于比较微调后的 GPT-4o-mini 与顶级开源 SLMs 在 30 项不同任务中的表现的帖子引发了众多关注。该帖子获得了大量的点赞和众多评论。
帖子主要探讨了 GPT-4o-mini 在与其他模型比较中的情况,比如有人提出将 gemma 2 9b 和 qwen 2.5 7b 加入比较,还有人询问 GPT-4o-mini 的参数等问题。而发帖人表示 Qwen 2.5 会很快加入比较,对于 gemma 2 9b 也会考虑,同时解释了之前对 GPT-4o-mini 参数设定的一些情况。
讨论的焦点主要集中在以下几个方面:
- 关于模型参数的准确性。有人认为不能随意设定参数,而发帖人已经更新了相关内容。
- 不同模型在特定任务中的表现和适应性。比如有用户提到自己的测试中 GPT-4o-mini 是最好且最易微调的。
- 对于 Gemma 系列中不同型号在微调方面的适宜性存在疑问。
有用户分享道:“我们最近对微调 gpt-4o-mini、gemini-flash-1.5 和 llama-3.1-8b 在相同数据集上进行了一些基准测试,但我们的经验是 gpt-4o-mini 实际上是最好且最容易微调的。你可以在这里阅读更多相关内容:https://www.patched.codes/blog/a-comparative-study-of-fine-tuning-gpt-4o-mini-gemini-flash-1-5-and-llama-3-1-8b”
也有人质疑这可能是发帖人的公司营销行为。但总体而言,大家对于模型的比较和性能评估充满了关注和讨论,希望能够得出更准确和客观的结论。


感谢您的耐心阅读!来选个表情,或者留个评论吧!