讨论总结
本次讨论主要聚焦于Molmo视觉模型在读取模拟时钟时间方面的表现,对比了其他大型模型如Claude、GPT、Gemini的不足。讨论中涉及了模型的训练数据、泛化能力、以及在特定情况下的识别错误。参与者们分享了各自的实验结果和观点,强调了Molmo模型在处理模拟时钟图片时的独特方法,如使用嵌入模型和分词器训练。此外,讨论还涉及了模型在读取时钟时间时的沟通障碍和失败案例,以及对模型能力的质疑。整体讨论氛围较为技术性,但也不乏对模型性能的实际应用和潜在影响的探讨。
主要观点
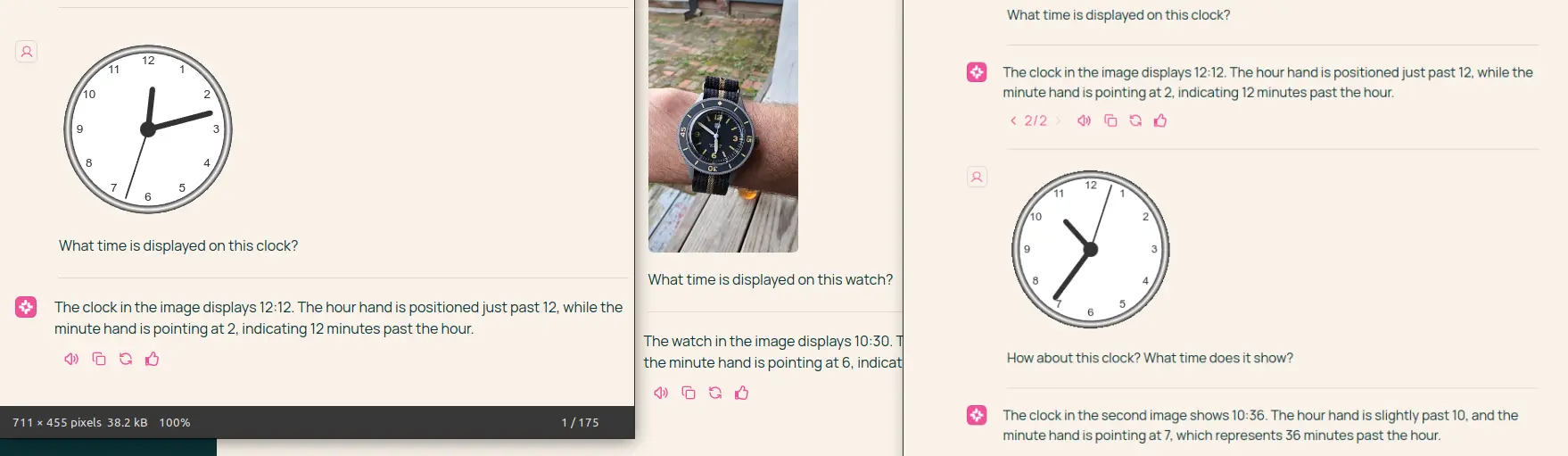
👍 Molmo模型能够读取模拟时钟时间,尽管有时会混淆分钟和小时指针。
- 支持理由:Molmo在其论文中明确提及了模拟时钟数据,并通过大规模渲染合成时钟数据,模型在读取时钟时间方面表现出色。
- 反对声音:有评论者认为这种能力并不值得特别称赞,因为该模型在训练时有20%的数据专门用于此任务。
🔥 Molmo模型在其论文中明确提及了模拟时钟数据。
- 正方观点:这表明Molmo在训练时已经考虑到了模拟时钟数据的特殊性,从而提升了模型的性能。
- 反方观点:有评论者质疑这种专门训练的数据是否真的提升了模型的泛化能力。
💡 当前最先进的模型(如Claude、GPT、Gemini)可能缺乏模拟时钟数据。
- 解释:讨论中提到,这些模型在处理模拟时钟图片时表现不佳,可能是因为它们在训练时缺乏相关的数据集。
💡 模拟时钟数据的收集非常具有挑战性,且在互联网上缺乏相关标注数据。
- 解释:这一观点强调了Molmo模型在数据收集方面的独特性和挑战性,以及其在处理模拟时钟任务时的优势。
💡 通过大规模渲染合成时钟数据,模型在读取时钟时间方面表现出色。
- 解释:这一观点展示了Molmo模型在数据生成和处理方面的创新方法,以及其在实际应用中的有效性。
金句与有趣评论
“😂 AnticitizenPrime:So, I had a look at their paper and they explicitly mention analog clock data :)”
- 亮点:评论者通过查阅论文,确认了Molmo模型在训练时确实考虑了模拟时钟数据,这一发现为讨论提供了有力的支持。
“🤔 Emergency_Talk6327:This is a dataset we collected :0 Surprisingly very non-trivial to collect well!”
- 亮点:评论者分享了数据收集的困难,强调了Molmo模型在数据处理方面的独特性和挑战性。
“👀 AnticitizenPrime:I even tried to ’trick’ it by setting one watch an hour behind and asked it for the time on all three watches, it got it right!”
- 亮点:评论者通过实验验证了Molmo模型的能力,尽管设置了“陷阱”,模型仍然正确识别了时间。
“🤔 dodiyeztr:it’s not just training data, it is also the embedding model that is being used to train the tokenizer”
- 亮点:评论者强调了嵌入模型在Molmo模型训练中的关键作用,这一观点为讨论提供了新的视角。
“👀 FrermitTheKog:I’m pretty sure the photo of the watch shows 5:50, not 10:30 since the small hand is just behind the 6 and the big hand is on 50 minutes.”
- 亮点:评论者通过详细分析图片,指出了Molmo模型在识别腕表时间时的错误,这一发现引发了进一步的讨论。
情感分析
讨论的总体情感倾向偏向于技术性和中立,参与者们主要关注模型的性能和数据处理方法。尽管有部分评论者对Molmo模型的能力表示质疑,但大多数讨论仍然集中在模型的实际表现和潜在影响上。主要分歧点在于模型的泛化能力和训练数据的特殊性,部分评论者认为Molmo模型的表现并不值得特别称赞,因为它在训练时已经专门针对模拟时钟任务进行了优化。
趋势与预测
- 新兴话题:未来可能会有更多关于模型泛化能力和训练数据多样性的讨论,特别是在处理特定任务时,如何平衡专门训练和泛化能力之间的关系。
- 潜在影响:Molmo模型的成功可能会引发更多关于视觉模型在特定任务上的应用研究,特别是在需要高精度识别的任务中,如模拟时钟读取。此外,这一讨论也可能推动更多关于模型训练数据和方法的创新研究。
详细内容:
《关于模型读取模拟时钟的热门讨论》
近日,Reddit 上有一个关于模型读取模拟时钟的帖子引发了热烈关注。该帖子展示了一组模拟时钟的图片,并对其进行了详细描述,获得了众多点赞和大量评论。帖子中提到,Molmo 是第一个被发现能读取模拟时钟的视觉模型,而 Claude、GPT 和 Gemini 似乎在这方面表现不佳。
讨论焦点主要集中在以下几个方面: 有人指出看过 Molmo 的相关论文,其中明确提到了模拟时钟数据。还有人认为其实 Gemini 也具备读取模拟时钟的能力,只是可能由于下游训练任务的影响导致性能被覆盖。有人分享说收集模拟时钟的数据集并非易事,而这个模型能通过大规模渲染合成时钟实现良好性能,这非常厉害,并且通过研究时钟还能探讨模型的泛化能力。 有人好奇这个能读取时钟的模型是否在读取图表等方面表现更好,但尝试对其他大模型进行“教学”却未成功,并且怀疑大模型不是不会做,而是无法分辨指针指向。也有人提出或许之前的模型在视觉部分和文本部分存在沟通差距。
在讨论中,有人认为不仅仅是训练数据的问题,嵌入模型用于训练标记器也很关键。还有人提到 qwen2-vl-72b-instruct 也能做到,而 Llama-3.2-90B-Vision 则失败了,令人失望。
对于模型在读取模拟时钟任务上的表现,有人认为如果 20%的训练数据都专注于该任务,成功也不算稀奇。
总之,关于模型读取模拟时钟的能力,Reddit 上的讨论热烈且观点多样,反映了大家对于模型性能和训练方式的深入思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!