我刚买了我的第一张3090显卡,它到达的同一天Qwen发布了2.5版本。我制作了这个插图,只是为了弄清楚我是否应该使用它,在使用它几天并看到32B模型是多么出色之后,我觉得应该分享这张图片,这样我们都可以再看一遍,并欣赏阿里巴巴为我们所做的一切。
讨论总结
本次讨论主要围绕Qwen 2.5和Llama 3.1的模型性能、许可证限制、硬件需求和成本效益展开。参与者们分享了各自的使用体验和实验结果,讨论了不同模型的优缺点、许可证限制以及在实际使用中的表现。此外,还涉及了硬件需求(如3090显卡)和成本效益的考量。讨论中还提到了开源贡献、快速更新和实际使用体验,以及中英文切换问题和性价比的考量。
主要观点
- 👍 70B模型被认为是目前最好的模型,但存在许可证限制。
- 支持理由:性能优越,但许可证限制了其广泛应用。
- 反对声音:许可证限制可能阻碍其普及。
- 🔥 32B模型在大多数使用场景中可能已经足够,且成本更低。
- 正方观点:成本效益高,适用于大多数用户。
- 反方观点:性能可能不如更大规模的模型。
- 💡 Qwen的许可证相对宽松,适用于大多数使用场景。
- 解释:许可证宽松,便于广泛应用。
- 🚀 硬件升级(如购买第二张3090显卡)是否值得取决于具体的使用需求和问题。
- 解释:硬件升级需根据实际需求评估。
- 🤔 不同模型之间的性能差距可能并不显著。
- 解释:需通过实际使用来评估模型性能。
金句与有趣评论
- “😂 Is there any provider from which I can use 32B?”
- 亮点:反映了用户对32B模型的需求。
- “🤔 I find the Qwen license quite permissive for most use cases.”
- 亮点:强调了Qwen许可证的宽松性。
- “👀 I keep coming close to pulling the trigger on a second video card, but then a new small model drops that outperforms the current larger ones.”
- 亮点:表达了用户对新模型发布的无奈。
- “🚀 Alibaba has come a long way. Love what they’re doing for open source.”
- 亮点:赞赏阿里巴巴在开源领域的贡献。
- “💡 Llama3.1 who? Llama3.2 dropped like a whole 30 minutes ago!”
- 亮点:幽默地反映了模型更新的快速。
情感分析
讨论的总体情感倾向较为积极,主要集中在对模型性能和开源贡献的赞赏。主要分歧点在于硬件升级的必要性和不同模型之间的性能对比。可能的原因包括新模型的快速发布和许可证限制的影响。
趋势与预测
- 新兴话题:未来可能会有更多新模型发布,如Gemma 3、Llama 4、Queen 3、Phi 4、Deepseek和新的Mistral等。
- 潜在影响:快速更新的模型可能会对硬件需求和许可证限制产生进一步影响,同时开源贡献的价值将更加凸显。
详细内容:
标题:Qwen 2.5 与 Llama 3.1 模型的激烈讨论
近日,一位用户在 Reddit 上分享了自己购买 3090 显卡并对 Qwen 2.5 模型进行体验的经历,引发了众多网友的热烈讨论。该帖子获得了较高的关注度,评论众多。
讨论的主要方向包括不同模型参数的性能比较,如 32B、70B、72B 等,以及模型在不同场景下的应用表现。
文章将要探讨的核心问题是:Qwen 2.5 与 Llama 3.1 各个版本的模型在性能和实际应用中的优劣势究竟如何。
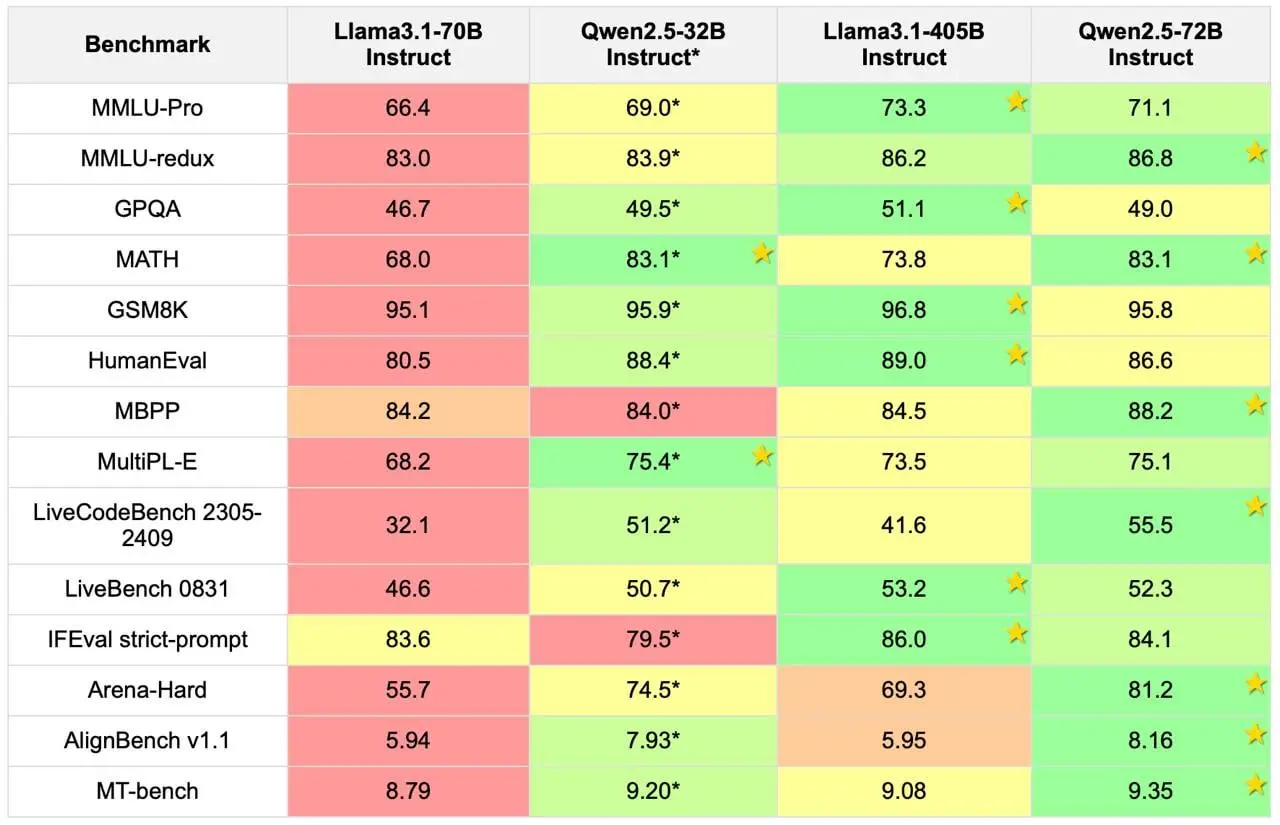
有人表示 70B 是最好的,测试中能给到 16 T/s 的表现。但也有人认为 32B 对于大多数使用场景可能已经足够好,而且价格更便宜。有人指出 Qwen 的许可证在大多数使用场景下相当宽松,只有在达到 1 亿月活跃用户规模时才需要单独授权。
还有人分享自己使用不同模型的体验,称 70 亿参数的模型表现优于其他参数相近的模型,其响应质量可与 400 多亿参数的模型相媲美。8 亿参数的模型类似于 32 亿参数的模型,但可能在世界知识和深度上有所欠缺。
有人好奇阿里巴巴是如何做到的,是训练数据还是架构的改进。也有人在考虑是否要购买第二张显卡,因为新的小模型不断推出,性能超越现有的大模型。
有人称赞阿里巴巴为开源技术做出的贡献,也有人认为不能盲目崇拜科技公司。
有人询问如何在 3090 上运行 32B 模型以及使用何种量化压缩来获得良好性能,并分享了相关的技术设置。
有人开玩笑说模型更新速度快得让人应接不暇,刚提到 Llama 3.1,Llama 3.2 就发布了。
有人认为 72B 的性能达到了 405B 的水平,有时 32B 也能胜出。但也有人指出 Qwen 2.5 的 32B 模型在某些方面不如 L 3.1 70B,72B 虽然可比,但也难以明确说哪个更好。
有人想知道有没有地方可以比较开源模型与 OpenAI 和 Claude 的性能。也有人认为虽然开源模型可能不如 OpenAI 和 Claude,但免费往往具有更高的价值。
总之,关于 Qwen 2.5 与 Llama 3.1 模型的讨论十分热烈,各方观点各有依据,展现了模型领域的快速发展和复杂性。


感谢您的耐心阅读!来选个表情,或者留个评论吧!