来源 (现已删除)
讨论总结
本次讨论主要围绕Llama 3.2 1B和3B模型的性能基准数据展开,涵盖了模型的开源发布、训练过程、与其他模型的对比以及对未来应用的期待。讨论中,用户们对模型的性能表现、训练数据、知识蒸馏技术、上下文扩展等方面进行了深入探讨。部分用户对Llama 3.2模型的性能表示不满,认为其不如之前的版本,而另一些用户则对模型的开源和未来应用表示期待。总体上,讨论氛围较为技术性,涉及大量专业术语和数据分析。
主要观点
- 👍 LLAMA-1B和LLAMA-3B模型已开源,训练数据量高达9T个tokens
- 支持理由:开源有助于研究人员和开发者更好地理解和应用AI技术。
- 反对声音:部分用户认为模型的性能不如预期。
- 🔥 Llama 3.2 1B和3B模型的基准测试结果比phi3.5模型的结果更可靠
- 正方观点:Llama 3.2系列模型是从8B和70B权重中提炼出来的,数据更可靠。
- 反方观点:部分用户认为phi模型在数据填充方面表现不佳,可能有数据泄露的问题。
- 💡 Llama 3.2 1B和3B模型与Qwen 2.5模型的性能对比
- 解释:用户们对Llama 3.2系列模型与Qwen 2.5模型在不同任务上的表现差异进行了讨论,涉及模型训练数据和性能评估。
- 💡 Llama 3.2 1B和3B的性能不如Llama 3.1 8B
- 解释:部分用户认为新版本模型的性能不如之前的版本,提出了明确的对比观点。
- 💡 Llama 3.2 1B和3B模型被认为是“pure trash”
- 解释:有用户对模型的性能表示强烈不满,称其为“pure trash”,并提出了其他偏好的模型。
金句与有趣评论
- “😂 TKGaming_11:Thrilled to open-source LLAMA-1B and LLAMA-3B models today.”
- 亮点:表达了作者对模型开源的兴奋和期待。
- “🤔 ResidentPositive4122:I trust these benchmarks more than phi3.5 ones, since the 3.2 SLMs were distilled from the 8&70B weights, not mainly synthetic gpt slop.”
- 亮点:强调了对Llama 3.2模型基准测试结果的信任,并指出了数据来源的可靠性。
- “👀 Future_Might_8194:Is this suggesting that Llama 3.2 3B is stronger than Llama 3.1 8B?”
- 亮点:提出了对模型性能对比的疑问,引发了进一步的讨论。
- “😂 grigio:llama3.1 8B still is much better”
- 亮点:简洁明了地表达了对新版本模型性能的不认可。
- “🤔 Existing_Freedom_342:pure trash”
- 亮点:强烈表达了对模型性能的不满,引发了关于模型偏好的讨论。
情感分析
讨论的总体情感倾向较为技术性和客观,大部分用户对模型的性能和训练细节进行了深入探讨。然而,也有部分用户对新版本模型的性能表示不满,情感倾向较为负面。主要分歧点在于对模型性能的评估和对其他模型的偏好。可能的原因包括用户对模型性能的期望不同,以及对不同模型训练数据和技术的理解差异。
趋势与预测
- 新兴话题:模型训练中的知识蒸馏技术和上下文扩展挑战可能会引发后续讨论。
- 潜在影响:Llama 3.2模型的开源和性能评估可能会影响研究人员和开发者在选择和应用AI模型时的决策。
详细内容:
标题:关于 Llama 3.2 语言模型的热门讨论
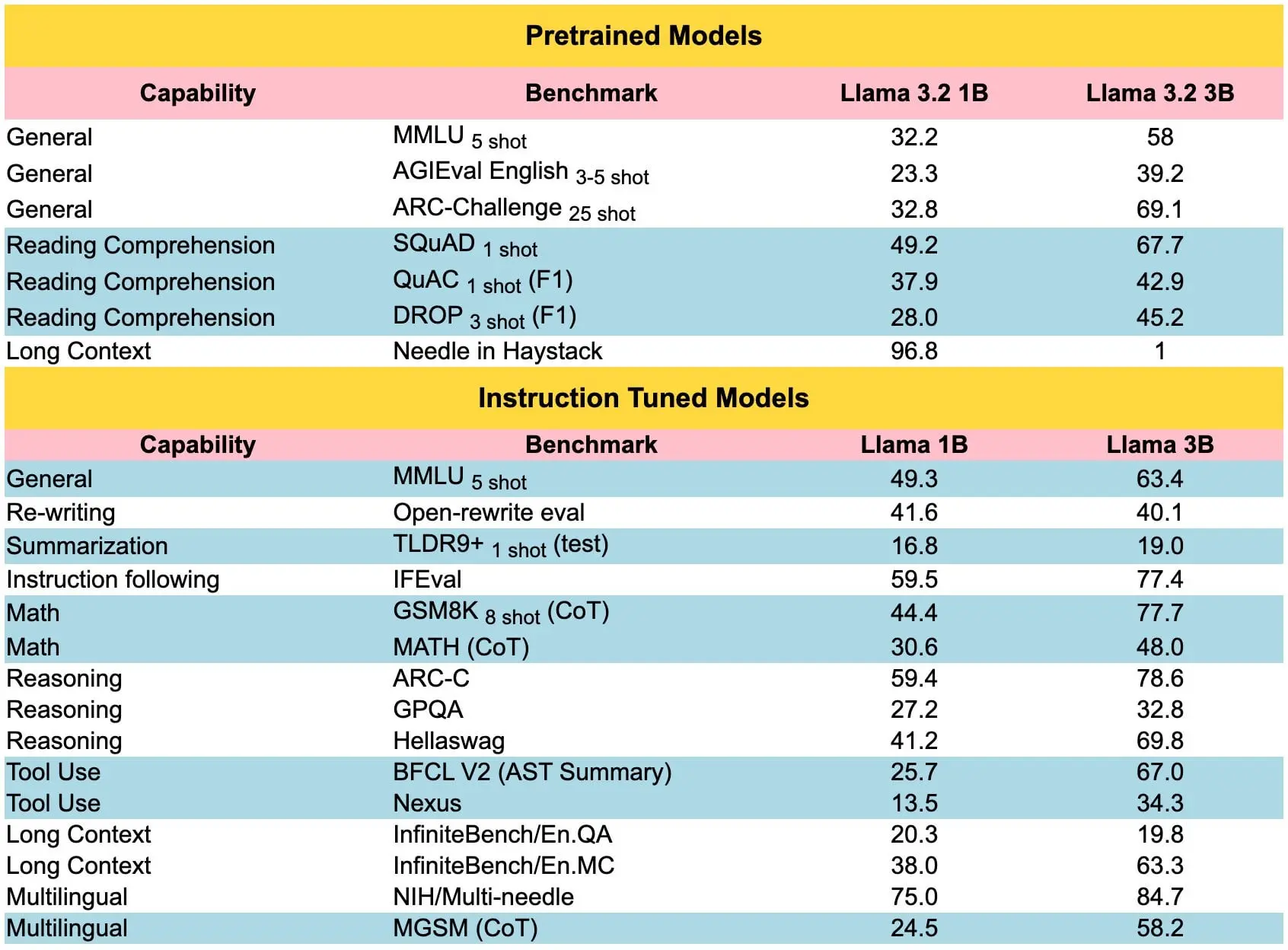
近日,Reddit 上有关 Llama 3.2 语言模型的话题引发了广泛关注。一张详细展示其性能基准数据的表格图片被分享,获得了众多点赞和大量评论。该话题主要围绕着 Llama 3.2 1B 和 3B 在不同任务上的表现展开讨论。
在讨论中,有人分享了自己对于该模型训练过程和特点的详细介绍,包括如何从更大规模的模型进行修剪和知识蒸馏,以及在不同规模下处理上下文长度的挑战和解决方案等。还有用户提到在测试中对 llama 3.1 8B 的功能调用效果不太满意,并希望能对 3.1 8B 进行更新。有人认为使用 Nvidia Nemo 可以显著增强模型效果,也有人表示自己安装了很多语言模型,并分享了使用和分配任务的经验。
有人表示信任 Llama 3.2 的基准测试结果,认为其比 phi3.5 的更可靠。还有人认为 llama3.1 8B 仍然表现出色,也有人给出了“纯垃圾”这样极端的评价,并提到更喜欢 Gemma 2、Qwen 2.5 等模型。
对于这一话题,不同用户的观点各异,反映出大家对于语言模型性能评估和选择的不同看法。是模型本身的特性决定了其优劣,还是使用和训练方法的差异导致了不同的效果,成为了讨论中的关键争议点。而关于如何在众多模型中选择适合自己需求的产品,以及如何进一步优化和提升模型性能,仍有待更多的探讨和研究。


感谢您的耐心阅读!来选个表情,或者留个评论吧!