我们发布了Prem-1B-SQL。这是一个开源的1.3参数模型,专用于文本到SQL任务。它在BirdBench私有测试集上达到了51.54%的执行准确率。
我们在两个流行的基准数据集上评估了我们的模型:BirdBench和Spider。BirdBench包含一个公开的验证数据集(包含1534个数据点)和一个私有测试数据集。Spider只提供了一个公开的验证数据集。以下是结果:
| 数据集 | 执行准确率 (%) |
|---|---|
| BirdBench (验证) | 46 |
| BirdBench (私有测试) | 51.54 |
| Spider | 85 |
BirdBench数据集分布在不同的难度级别上。以下是不同难度级别的私有测试结果的详细视图。
| 难度 | 数量 | 执行准确率 (%) | 软F1 (%) |
|---|---|---|---|
| 简单 | 949 | 60.70 | 61.48 |
| 中等 | 555 | 47.39 | 49.06 |
| 挑战 | 285 | 29.12 | 31.83 |
| 总计 | 1789 | 51.54 | 52.90 |
Prem-1B-SQL使用PremSQL库进行训练,这是一个专注于文本到SQL类任务的端到端本地优先开源库。
对于数据库上的问答任务(有时数据库是私有的,企业不希望他们的数据被第三方闭源模型泄露),因此我们认为它应该是一个本地优先的解决方案,完全控制您的数据。
HuggingFace模型卡: https://huggingface.co/premai-io/prem-1B-SQL
PremSQL库: https://github.com/premAI-io/premsql
BirdBench结果(目前排名第35位,共50个): https://bird-bench.github.io/ 大多数表现最好的模型要么使用GPT-4o,要么使用一些非常大的模型,无法在本地运行。
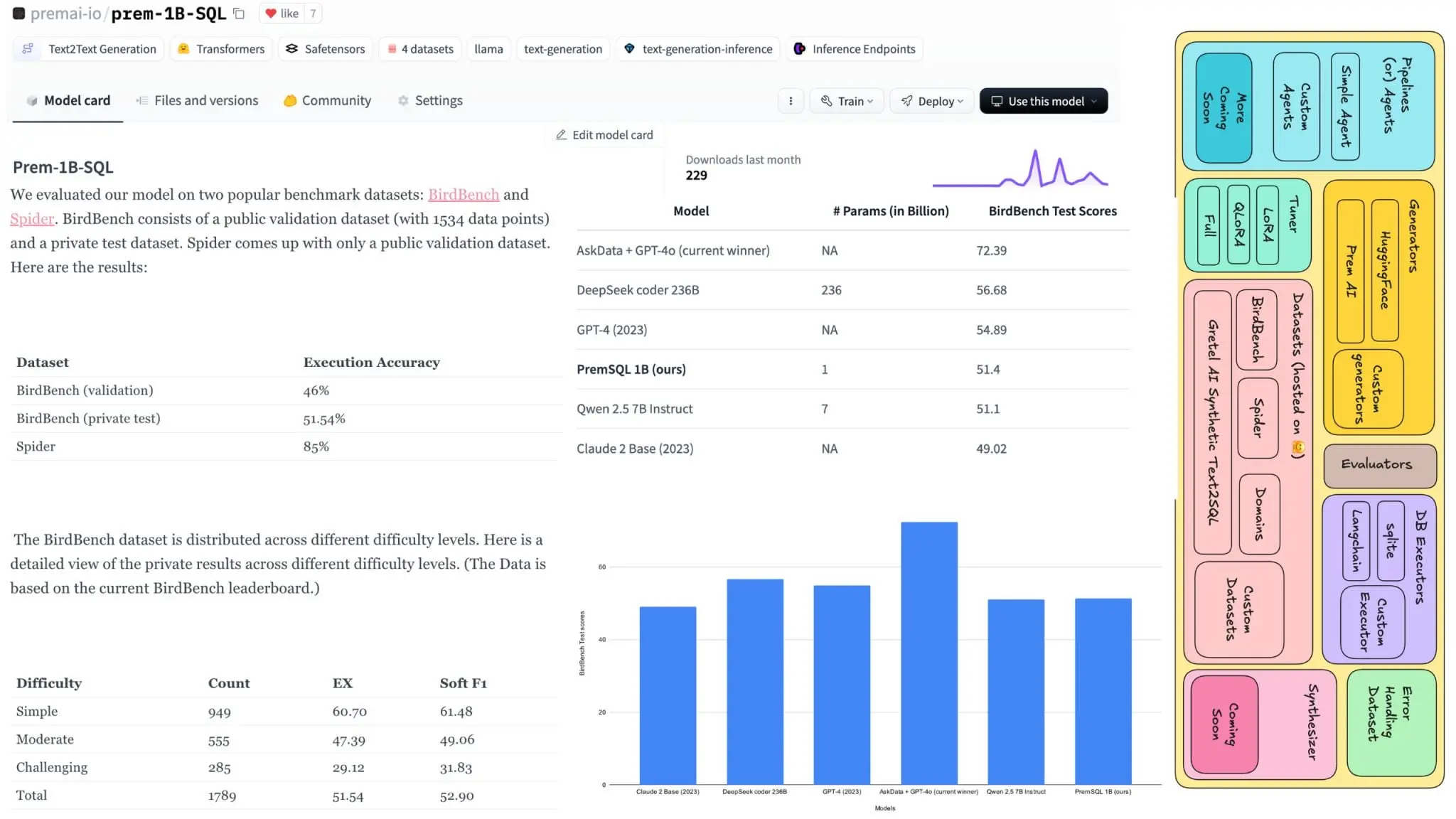
如果您想知道结果与GPT-4相比如何?以下是一些最新的结果
而PremSQL是51.54%。然而,我们正在努力做得更好。所以请保持更新。我们还将为PremSQL仓库带来新的更新,例如小型自托管的游乐场,用于尝试您的模型、API等。
讨论总结
讨论主要围绕Prem-1B-SQL模型在文本到SQL任务中的表现、应用前景及技术细节展开。评论者普遍认为文本到SQL是大型语言模型(LLMs)的重要应用场景,能够使自然语言处理(NLP)技术更加普及。然而,目前的模型准确率(51.54%)仍不足以应用于实际场景,需要进一步提高。此外,讨论还涉及模型的数据库兼容性、未来发展计划以及如何通过微调提升性能。
主要观点
- 👍 文本到SQL应该是LLMs的主要应用场景
- 支持理由:文本到SQL的普及将使NLP技术更加大众化。
- 反对声音:目前的准确率还不够高,不足以应用于实际场景。
- 🔥 目前的准确率(51.54%)还不够高
- 正方观点:需要进一步提高模型的准确率,至少达到70%。
- 反方观点:目前的模型(如Prem-1B-SQL)是一个好的开始,但还不够。
- 💡 通过微调可以提高模型的性能
- 解释:微调是提升模型在特定任务上表现的有效方法。
- 💡 Prem-1B-SQL模型应具备数据库无关性
- 解释:该模型应能够操作任何关系型数据库管理系统(RDBMS)。
- 💡 未来计划包括训练更多不同规模的小模型
- 解释:这将有助于在不同应用场景中使用该模型。
金句与有趣评论
- “😂 Text to SQL should be the most dominant use case for LLMs. Basically finally enabling NLP for the general populace.”
- 亮点:强调了文本到SQL在NLP普及中的重要性。
- “🤔 Generally a Text2SQL prompt is very dynamic and DB dependent.”
- 亮点:指出了文本到SQL提示的动态性和数据库依赖性。
- “👀 理想情况下,它应该是数据库无关的。”
- 亮点:强调了模型应具备数据库无关性的重要性。
情感分析
讨论的总体情感倾向较为积极,评论者对Prem-1B-SQL模型的表现表示赞赏,并对其未来发展充满期待。主要分歧点在于模型准确率的提升和数据库兼容性的扩展,这些技术细节的讨论体现了专业性和技术性。
趋势与预测
- 新兴话题:未来可能会出现更多关于如何通过微调提升模型性能的讨论。
- 潜在影响:提高文本到SQL模型的准确率和数据库兼容性将对NLP技术的普及和应用产生深远影响。
详细内容:
《Prem-1B-SQL 模型在 Text to SQL 任务中的表现引发 Reddit 热议》
近日,Reddit 上一则关于“Prem-1B-SQL 模型在 Text to SQL 任务中的表现”的帖子引起了广泛关注。该帖子介绍了 Prem-1B-SQL 这一开源 1.3 参数模型在 Text to SQL 任务中的出色成绩,在 BirdBench 私人测试集中执行准确率达到 51.54%,获得了众多点赞和大量评论。帖子还提供了多个相关链接,包括模型的 HuggingFace 模型卡、PremSQL 库以及 BirdBench 结果等。
讨论焦点主要集中在模型的性能、应用前景以及改进方向等方面。有人认为 Text to SQL 应成为大型语言模型的主要应用场景,能为大众所用。但也有人指出,虽然 PremSQL 达到 51.54%的准确率很出色,但对于实际应用来说还不够,应将 70%作为下一个目标。
有用户分享道:“一般来说,Text2SQL 提示非常动态且依赖于数据库。假如数据库有三个表(T1、T2 和 T3),提示格式就会是……” 还有用户表示:“接下来我们将训练更多此类小型模型,尝试 1 - 7B 范围内的更多模型,并推出一个 API,以便在其他应用中使用,同时还将提供一个自托管的小型游乐场,方便用户使用。”
讨论中存在的共识是模型取得了一定的成绩,但仍有很大的提升空间。特别有见地的观点认为,应在小型模型训练上持续发力,并通过技术改进进一步提高准确率。
总的来说,这次关于 Prem-1B-SQL 模型的讨论,展现了大家对 Text to SQL 领域的关注和期待,也为模型的未来发展提供了多样的思路。


感谢您的耐心阅读!来选个表情,或者留个评论吧!