我创建了这个快速比较,对比了今天两大发布的模型——Molmo似乎真的在包括最近发布的llama 3.2视觉模型在内的竞争中脱颖而出 💪
讨论总结
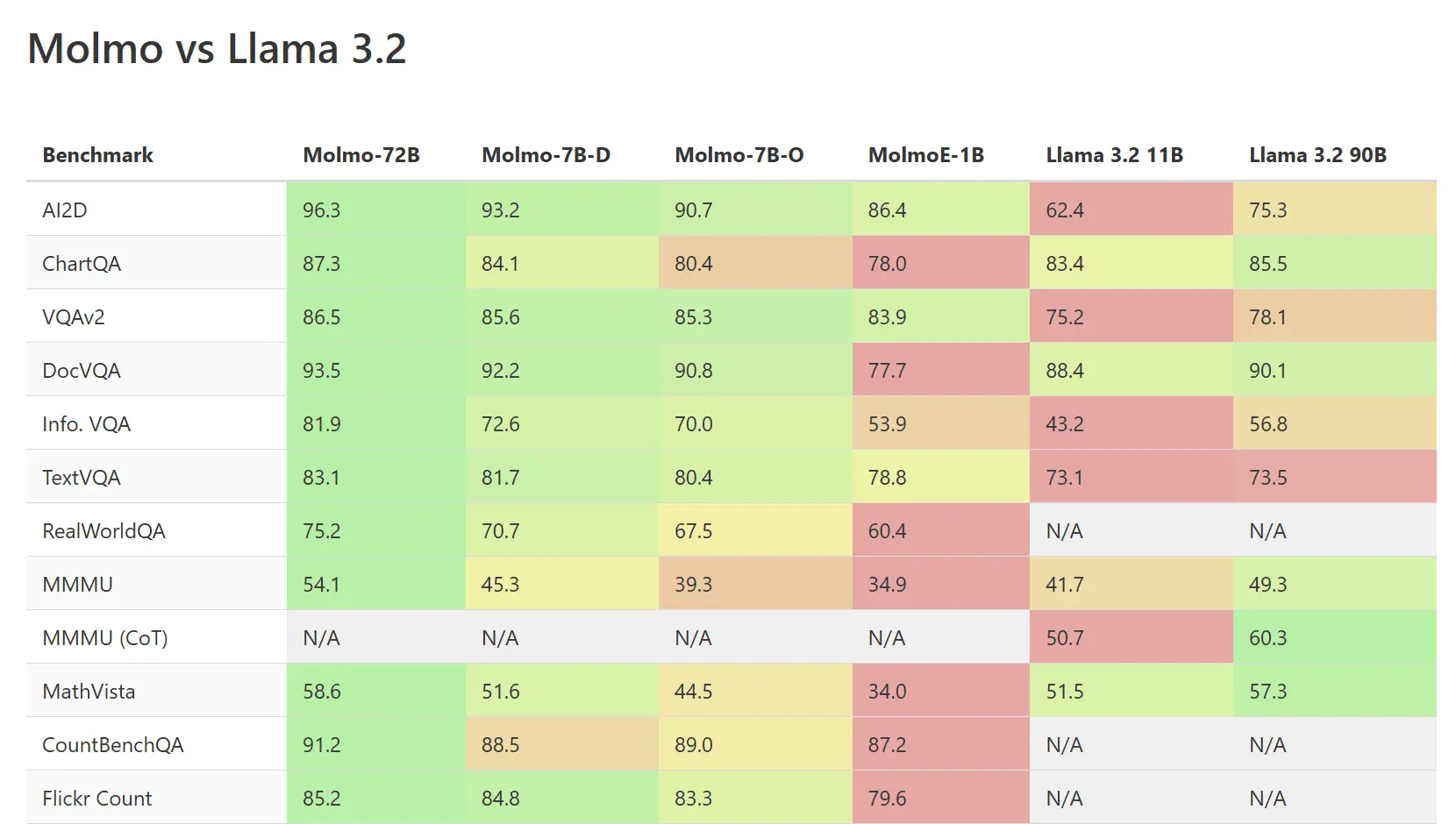
本次讨论主要围绕Molmo模型在视觉基准测试中优于Llama 3.2的表现展开。讨论内容涵盖了模型性能比较、训练方法、数据集使用等多个方面。评论者们对Molmo模型的表现给予了高度评价,同时也对Llama 3.2的不足之处进行了分析。讨论中还涉及到了多模态训练、数据集发布等新兴话题,显示出对未来模型发展的关注。整体讨论氛围较为技术化,主要面向研究人员和技术人员。
主要观点
- 👍 Molmo在多个视觉基准测试中表现优于Llama 3.2
- 支持理由:Molmo在AI2D、ChartQA、VQAv2等多个基准测试中得分较高,显示出其在视觉任务中的优越性能。
- 反对声音:部分评论者对Molmo宣称其表现优于GPT-4的情况表示怀疑。
- 🔥 Molmo在空间理解方面表现出色
- 正方观点:Molmo能够输出具体的坐标用于工具使用,这种能力对于某些应用场景非常有用。
- 反方观点:Llama 3.2在训练中缺乏重要的动作数据,导致其在某些任务中表现不佳。
- 💡 Molmo并非从头开始训练,而是在现有LLMs基础上进行扩展
- 解释:Molmo采用了与Meta不同的训练方法,专注于高质量的人工标注数据集,这使得其性能提升显著。
- 💡 Molmo计划在未来发布其数据集
- 解释:这一举措将对未来的视觉语言模型(VLMs)产生积极影响,有助于推动整个领域的发展。
- 💡 评论者建议在实际应用中测试模型性能
- 解释:不应过于关注潜在的推理或微调错误,而是应该在实际应用中验证模型的表现。
金句与有趣评论
- “😂 Molmo模型在大多数视觉基准测试中表现优于Llama 3.2模型。”
- 亮点:直接点明了Molmo模型的优越性能,简洁有力。
- “🤔 The instruct 90B version has a MMMU of 60 vs 54 for Molmo and 69 for GPT4-o. It seems kinda fishy that they claim they do so much better than GPT4 but worse on the critical benchmark (IMO).”
- 亮点:对Molmo宣称其表现优于GPT-4的情况表示怀疑,提出了关键基准测试得分较低的问题。
- “👀 The important thing to note here is that Llama 3.2 does not have significant action data trained into it, This is where Molmo shines- as it has a spatial understanding of the image and can output specific coordinates for use with tools.”
- 亮点:指出了Llama 3.2在训练中缺乏动作数据的不足,强调了Molmo在空间理解方面的优势。
- “👀 I’d recommend releasing the release blog, it contains quite a bit of technical details, more than you usually get with these releases.”
- 亮点:推荐了Molmo模型的官方博客,提供了丰富的技术细节,有助于深入了解模型。
- “👀 What are requirements? Can I run this locally on 3060 12GB?”
- 亮点:直接询问了Molmo模型的本地运行要求,显示出对模型实际应用的关注。
情感分析
讨论的总体情感倾向偏向正面,大多数评论者对Molmo模型的表现给予了高度评价。然而,也有部分评论者对Molmo宣称其表现优于GPT-4的情况表示怀疑,显示出一定的争议性。主要分歧点在于对基准测试结果的信任度,以及对不同模型训练方法的认可程度。
趋势与预测
- 新兴话题:多模态训练、数据集发布等话题可能会引发后续讨论,尤其是Molmo计划发布其数据集的举措,将对未来的视觉语言模型(VLMs)产生积极影响。
- 潜在影响:Molmo模型的优越性能和独特的训练方法,可能会对未来的模型选择和开发产生重要影响,尤其是在视觉任务和多模态应用领域。
详细内容:
《Molmo 模型在多数视觉基准测试中超越 Llama 3.2,引发热烈讨论》
近日,Reddit 上一则关于 Molmo 模型与 Llama 3.2 模型性能比较的帖子引发了众多关注。该帖子展示了一张详细的性能基准测试结果表格,比较了两者在多个领域的表现,获得了大量的点赞和众多评论。
讨论的焦点主要集中在以下几个方面: 有人提议将 Molmo 模型与 Qwen2 VL 模型进行比较。有用户分享说自己使用 Qwen2-VL-7B 进行图像字幕和手写文本图像的 OCR 时运气不错。还有人指出 Molmo 模型实际上是基于 Qwen 2 构建的。 对于模型的性能表现,看法不一。有人认为对于 7B 范围的模型,Qwen2 VL 在视觉任务方面表现极佳,目前尚未找到能超越它的模型。但也有人指出在某些基准测试中,Molmo 模型的表现优于 Llama 3.2,比如在 MMMU 测试中。 关于模型的训练方式和数据来源,有人提到 Molmo 模型并非从头开始训练,而是在现有 LLM 基础上增加了视觉能力,其采取的是创建相对较小但高质量数据集的方法,而不像 Meta 的模型使用大量来自 Instagram 等平台的数据。
同时,讨论中也存在一些争议。比如有人对 Molmo 模型声称比 GPT4 表现更好但在关键基准测试中表现不佳表示怀疑。还有人认为 Llama 3.2 由于没有大量训练行动数据,在这方面不如 Molmo。
总的来说,这次关于模型性能的讨论展现了大家对于人工智能模型发展的关注和深入思考。不同的观点和经验分享,为研究人员和技术爱好者提供了丰富的参考,也让公众对模型的能力差异有了更深入的了解。但究竟哪个模型更适合具体的应用场景,还需要根据实际情况进行测试和评估。


感谢您的耐心阅读!来选个表情,或者留个评论吧!