今天《自然》杂志上有一篇非常有趣的论文。内容很多,但主要观点是,在一系列模型(如OpenAI的GPT、Meta的Llama、BLOOM)中,模型规模越大,指令和对齐训练越多,模型的可靠性就越低。研究考察了LLM在五个困难任务类别中的表现:加法(算术)、字谜(词汇重排)、局部性(地理知识)、科学(多样化的科学技能)和转换(信息转换)。虽然模型在较简单的任务上表现越来越好,但在更难的问题变体上,它们越来越倾向于不再避免回答,而是开始给出错误答案。在下图中,蓝色表示正确答案(好),红色表示错误(坏),灰色表示拒绝回答(如果模型无法准确回答,这是好的)。
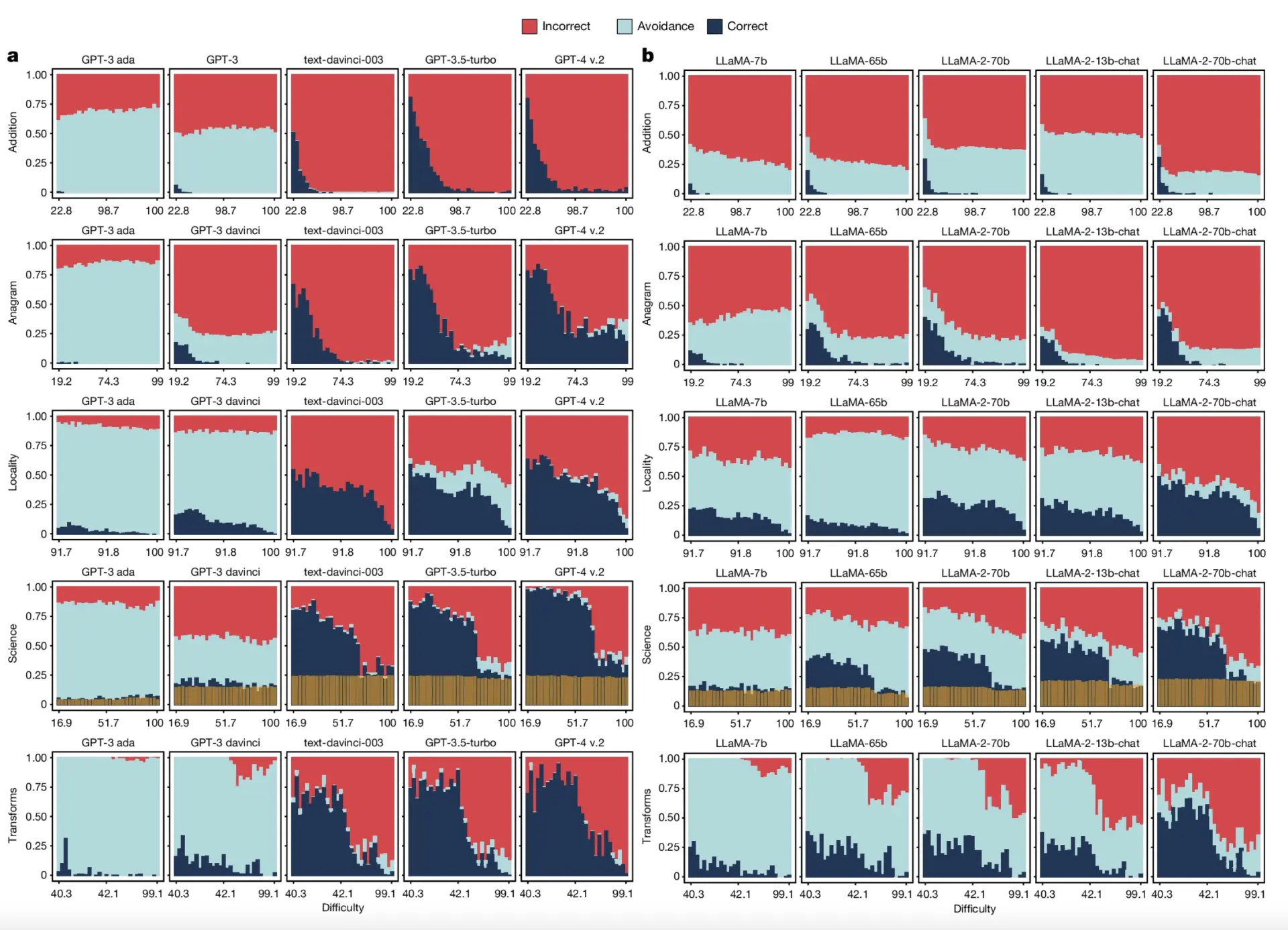
从左到右阅读,随着模型规模的增大,蓝色区域越来越多,因为较大的模型能给出更好的答案,尽管偏向于较简单的问题。问题在于灰色区域,较小的模型或基础模型会拒绝给出错误答案,而较大的模型则被自信的错误答案所取代。所有这些都与人类读者进行了基准测试,令人担忧的发现是,对于越来越错误的答案,人类无法准确判断答案是否正确。因此,这些模型变得越来越大,越来越自信地出错,但我们人类却很难辨别它们何时在自信地欺骗我们。
讨论总结
本次讨论主要围绕一篇发表在《Nature》上的论文展开,该论文指出大型AI模型(如OpenAI的GPT、Meta的Llama、BLOOM等)在扩展和进行更多指令与对齐训练后,其可靠性下降。讨论内容涵盖了研究方法的质疑、模型改进的期望、学术发表的渠道选择等多个方面。主要情感倾向为担忧和质疑,参与者普遍认为当前的RLHF方法未能充分奖励模型准确表达其知识状态,并希望未来的方法能够改进。此外,讨论中还涉及了AI模型在实际应用中的局限性、研究数据的时效性以及公众对AI技术的过度吹捧等问题。
主要观点
👍 当前的RLHF方法未能充分奖励模型准确表达其知识状态。
- 支持理由:评论者希望未来的方法能够改进,以确保模型在提供答案时能够更准确地反映其知识的不确定性或确定性。
- 反对声音:无明显反对声音,但有评论者质疑研究方法的有效性。
🔥 AI模型在规模扩大和指令训练增加后变得更加不可靠。
- 正方观点:这种现象与某些人在工作中职位提升后表现出的自信但错误百出的行为相似。
- 反方观点:有评论者认为研究基于较早版本的模型,数据可能过时,当前模型可能已经有所改进。
💡 研究基于较早版本的GPT-4和Llama模型,数据可能过时。
- 解释:评论者质疑研究的有效性,认为需要当前模型的数据来验证趋势。
👀 大型且经过指令训练的人工智能模型在复杂任务中容易给出错误但自信的答案。
- 解释:评论者认为这些系统仅在辅助人们在其已有专业领域的工作时才有用,并且强调了在使用这些模型时,用户必须具备一定的专业知识。
🤔 AI模型在面对困难任务时,避免响应的方式并不符合问题的要求。
- 解释:评论者通过引用具体的研究内容,强调了AI模型响应的不可靠性,并质疑研究中提到的“更可靠”一词。
金句与有趣评论
“😂 This sounds exactly like some people i used to work with”
- 亮点:通过幽默的类比,评论者表达了对AI模型发展趋势的担忧,同时也隐含了对人类行为的一种讽刺。
“🤔 Boy do I wish commonly employed RLHF methods rewarded models for accurately representing epistemic status.”
- 亮点:评论者对当前RLHF方法的不足提出了期望,希望未来的方法能够改进。
“👀 Yes, LLMs are just a part of a useful and complex AI system. They are not the complete solution.”
- 亮点:评论者强调了LLMs在复杂AI系统中的作用,认为它们不能替代人类科学家,也不能单独构成完整的AI解决方案。
情感分析
讨论的总体情感倾向为担忧和质疑。主要分歧点在于对研究方法的有效性和模型改进的期望。担忧主要来自于AI模型在扩展和指令训练后变得更加不可靠的现象,以及公众对AI技术的过度吹捧。质疑则集中在研究数据的时效性、学术发表的渠道选择以及模型在实际应用中的局限性。
趋势与预测
- 新兴话题:未来可能会有更多关于如何改进RLHF方法以提高模型准确性的讨论。
- 潜在影响:对AI模型的可靠性研究可能会影响未来AI技术的发展方向,尤其是在模型训练和应用方面。此外,公众对AI技术的认知也可能因此发生变化,尤其是在AGI的期待和炒作方面。
详细内容:
标题:关于大型且可指导的 AI 模型可靠性的热门讨论
在 Reddit 上,一篇题为“Larger and More Instructable AI Models Become Less Reliable”的帖子引发了广泛关注。该帖子分享了发表在《自然》杂志上的一篇有趣论文的相关内容,其中指出在一系列模型(如 OpenAI GPT、Meta 的 Llama、BLOOM 等)中,模型规模越大,指令和对齐训练越多,反而越不可靠。此研究考察了语言模型的五个困难任务类别:加法(计算能力)、字谜(词汇重组)、位置(地理知识)、科学(多种科学技能)和变换(信息转换)。帖子获得了众多点赞和大量评论,主要讨论方向集中在模型不可靠的原因、研究的时效性以及其对实际应用的影响等方面。文章将要探讨的核心问题是如何解决模型规模增大却可靠性降低的矛盾,以及这对未来 AI 发展的意义。
在讨论中,有人认为常见的 RLHF 方法应奖励模型准确呈现认知状态。还有人表示这种模型越来越自信地犯错的情况,听起来就像曾经共事过的一些人。有人指出研究基于较旧版本的模型,数据可能过时,但也有人认为这是一种趋势,即便数据在更新,新增的也可能多是简单任务。有人提到该研究只是确认了长久以来已知的事实,即此类系统仅在人们已有一定专业知识的领域辅助工作有用。有人认为尽管最新的模型能加快工作速度,但使用者必须清楚自己在做什么。还有人指出研究中几乎所有的回避型回答都属于“不符合标准的回避”类型,很难称这种回答“更可靠”。有人对研究发表在《自然》杂志而非顶级机器学习会议表示疑惑,有人解释因为研究需要时间。有人认为这并非实验研究,样本量小,且可能未控制每个模型不断增加的帮助性和冒险性。也有人认为大型语言模型只是有用且复杂的 AI 系统的一部分,不能替代人类科学家,只有神经符号 AI 才能做到。有人指出虽然大型语言模型能提高生产力,但并非通用人工智能。
总的来说,讨论中的共识在于认识到大型语言模型存在可靠性问题,且不是解决一切的万能钥匙。特别有见地的观点如指出研究中回避型回答的类型不可靠,丰富了对模型可靠性的理解。但对于如何解决这些问题,以及未来 AI 发展的方向,仍存在诸多争议和不同看法。


感谢您的耐心阅读!来选个表情,或者留个评论吧!