我使用 IFEval 数据集对 Llama 3.2-1B GGUF 量化进行了基准测试,以找到速度和准确性之间的最佳平衡。为什么我选择 IFEval? 它是一个很好的基准测试,用于测试大型语言模型如何遵循指令,这对于大多数现实世界的使用案例(如聊天、问答和总结)至关重要。
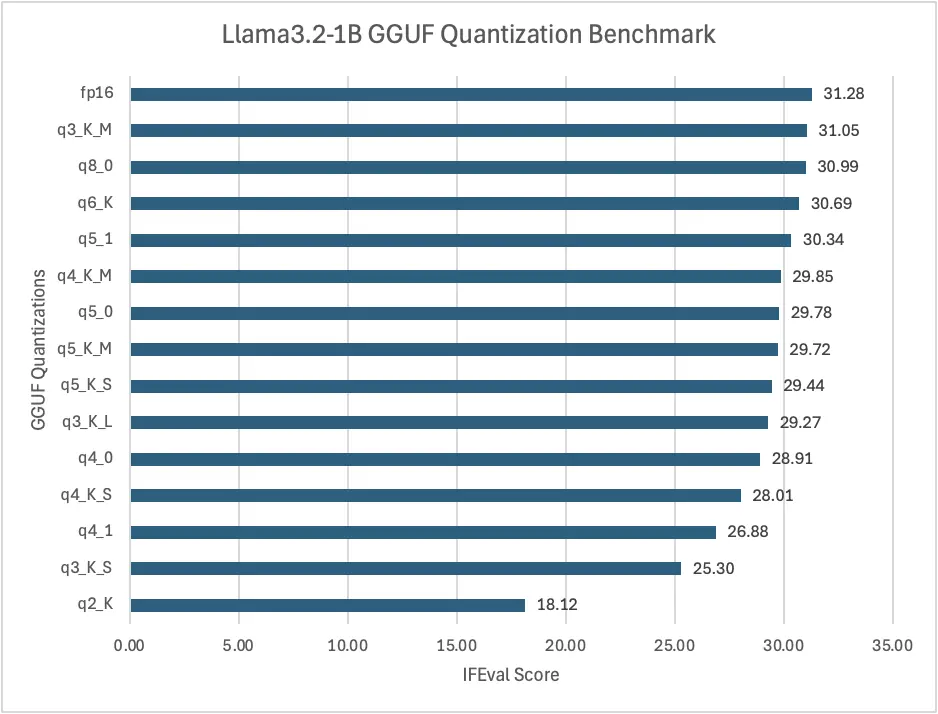
第一张图表展示了不同 GGUF 量化在 IFEval 评分上的表现。
第二张图表说明了文件大小与性能之间的权衡。令人惊讶的是,q3_K_M 占用空间更小(更快),但保持了与 fp16 相似的准确性水平。
完整数据可在此处获取:nexaai.com/benchmark/llama3.2-1b
量化模型从 ollama.com/library/llama3.2 下载
后端:github.com/NexaAI/nexa-sdk(SDK 将很快支持基准测试/评估!)
接下来是什么?
- 我应该接下来对 Llama 3.2-3B 进行基准测试吗?
- 对不同的量化方法(如 AWQ)进行基准测试?
- 欢迎提出改进此基准测试的建议!
让我知道你的想法!
讨论总结
本次讨论主要围绕Llama 3.2-1B GGUF量化基准测试结果展开,涉及量化方法的性能比较、数据集合理性、未来研究方向等多个方面。讨论中,用户对测试结果的可靠性提出了质疑,特别是Q3量化方法在1B模型上的表现与预期不符,引发了关于向量存储信息理解的讨论。此外,用户建议尝试其他基准测试方法如MMLU或MMLU Pro,以验证q3_K_M的表现。总体上,讨论氛围较为技术性,用户积极参与,提出了许多有价值的见解和建议。
主要观点
👍 Q3量化方法在1B模型上的表现与预期不符
- 支持理由:评论者tu9jn指出,根据其经验,Q3量化方法通常只适用于非常大的模型,而1B模型在这种量化下应该表现不佳。
- 反对声音:部分用户认为结果可能是由于样本量小导致的随机噪声。
🔥 IFEval数据集的合理性受到质疑
- 正方观点:评论者Healthy-Nebula-3603对IFEval数据集的合理性提出质疑,认为测试结果“非常奇怪”。
- 反方观点:有用户建议尝试其他基准测试方法,如MMLU或MMLU Pro,以验证q3_K_M的表现。
💡 q3_K_M量化方法在多个基准测试中的表现异常
- 解释:评论者注意到q3_K_M在多个基准测试中的表现异常,认为其“神秘地”表现出色,建议进一步探索其表现。
💡 困惑度(PPL)并不直接衡量模型的推理能力
- 解释:评论者TyraVex指出,困惑度仅反映模型复述维基百科内容的能力,并不直接衡量模型的推理能力。
💡 1B模型在互动文本冒险游戏中表现出色
- 解释:评论者compilade分享了其在主观测试中的发现,指出Llama-3.2-1B-Instruct模型在互动文本冒险游戏中表现出色。
金句与有趣评论
“😂 Odd result, Q3 is only tolerable with very large models in my experience, a 1B should be brain dead at that quant.”
- 亮点:tu9jn的经验分享引发了关于Q3量化方法适用性的讨论。
“🤔 That benchmark uses always the same questions or kind of random ones?”
- 亮点:Healthy-Nebula-3603对IFEval数据集的合理性提出质疑,引发了对测试方法的讨论。
“👀 Maybe the benchmark isnt good enough”
- 亮点:JorG941对现有基准测试的可靠性提出质疑,建议改进测试方法。
“😂 Man I’m very new to local LLM and choosing quants is always so confusing for me.”
- 亮点:eggs-benedryl表达了对选择量化方法的困惑,引发了对新手用户的建议和讨论。
“🤔 From my subjective testing,
Llama-3.2-1B-Instructis the first model of its size range which can adequately behave as an interactive text adventure game.”- 亮点:compilade的主观测试结果展示了1B模型在特定应用中的潜力。
情感分析
讨论的总体情感倾向较为中性,主要集中在技术性和信息性的讨论上。用户对测试结果的可靠性提出了质疑,但也有用户对量化方法的选择和应用表示认可。主要分歧点在于对Q3量化方法在1B模型上的表现的理解,以及对IFEval数据集合理性的质疑。可能的原因包括对向量存储信息的理解尚不全面,以及测试样本量小导致的随机噪声。
趋势与预测
- 新兴话题:未来可能会围绕其他基准测试方法如MMLU或MMLU Pro展开更多讨论,以验证q3_K_M的表现。
- 潜在影响:对量化方法的深入理解和优化将有助于提升模型性能和存储效率,对深度学习模型的研究和应用具有重要意义。
详细内容:
标题:Llama3.2-1B GGUF 量化基准测试结果引发热烈讨论
近日,一则关于 Llama3.2-1B GGUF 量化基准测试的帖子在 Reddit 上引起了广泛关注。该帖子详细介绍了对不同量化方法的测试,以寻找速度和准确性之间的最佳平衡,并使用 IFEval 数据集进行评估。帖子中的第一张图表展示了不同 GGUF 量化方法基于 IFEval 分数的性能表现,第二张图表则说明了文件大小和性能之间的权衡关系,令人惊讶的是,q3_K_M 占用空间更少但能保持与 fp16 相似的准确性。
此帖子获得了众多的点赞和大量的评论。讨论主要围绕测试结果的合理性、不同量化方法的实际应用效果以及进一步的测试方向展开。
有人表示“Q3 在非常大的模型中才勉强能接受,对于 1B 规模的模型来说,这样的结果很奇怪”。也有人认为“这个结果很神秘,在其他类似的基准测试中,q3_K_M 也表现得出奇地好”。还有人指出“这表明我们还不完全理解所有向量是如何存储信息的”,甚至有人觉得“整个基准测试结果看起来像是由于样本量小而产生的随机噪声测量”。
对于接下来的测试方向,有人建议“应该对 Llama 3.2-3B 进行基准测试”,有人提出“对不同的量化方法如 AWQ 进行测试”,也有人认为“尝试 MMLU 或 MMLU Pro 替代 IFEval 作为基准测试”。
在评论中,有人对数据的准确性提出疑问,如“那个基准测试使用的是始终相同的问题还是随机的问题?因为结果非常奇怪”。还有人对量化结果的实际应用表示关注,比如“对于本地 LLM 来说,选择量化方法总是令人困惑,看起来选择 Q4 或 Q5 K M 似乎不是个坏选择”。
总的来说,这次关于 Llama3.2-1B GGUF 量化基准测试的讨论充满了各种观点和疑问,为相关研究和应用提供了丰富的思考方向。但对于这些测试结果的解读和应用,仍需要进一步的研究和探讨。


感谢您的耐心阅读!来选个表情,或者留个评论吧!